tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Dec 31, 2007 1:36am
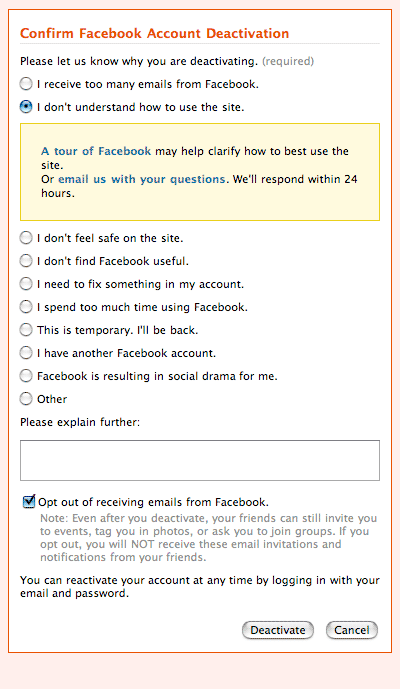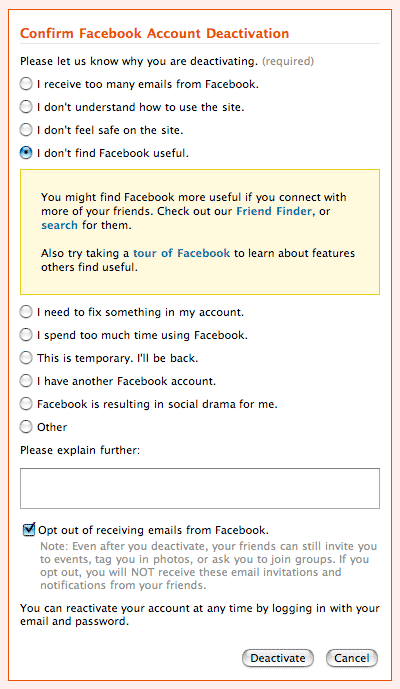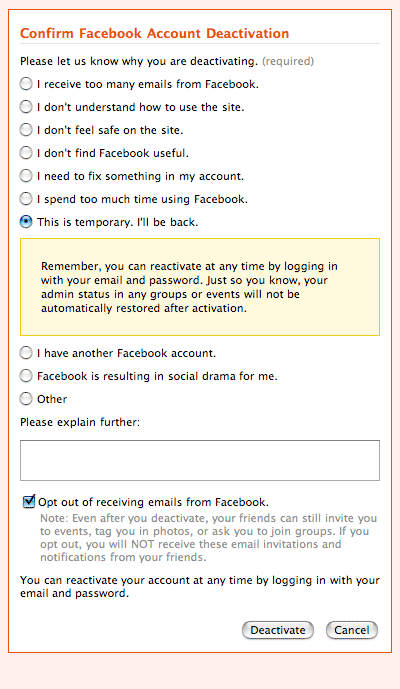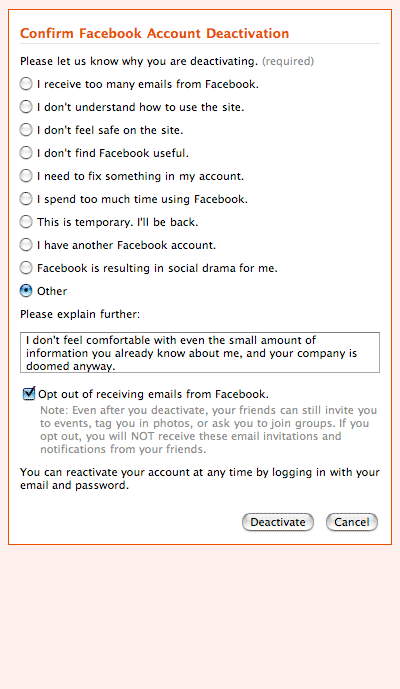
jaron lanier
What's wrong with Jaron Lanier?
Last month, he wrote a NYTimes opinion piece, Pay Me For My Content, arguing that it's up to "us" (geeks) to figure out how to make the Internet less free so that writers can get paid:
To help writers and artists earn a living online, software engineers and Internet evangelists need to exercise the power they hold as designers. Information is free on the Internet because we created the system to be that way. ... We owe it to ourselves and to our creative friends to acknowledge the negative results of our old idealism. We need to grow up.
Now, he has a piece in Discover, Long Live Closed-Source Software!, arguing that open source software unsuitable for "innovation":
Open wisdom-of-crowds software movements have become influential, but they haven't promoted the kind of radical creativity I love most in computer science. If anything, they've been hindrances. ... Linux is a superbly polished copy of an antique, shinier than the original, perhaps, but still defined by it.
Why did the adored iPhone come out of what many regard as the most closed, tyrannically managed software-development shop on Earth? An honest empiricist must conclude that while the open approach has been able to create lovely, polished copies, it hasn't been so good at creating notable originals.
This goes on until Lanier mires himself in a loopy biological metaphor about cellular membranes and finally falls back on the twin Old Faithfuls, "I get so much heat for my dangerous, minority opinion" and "I know Richard Stallman".
While I have my agreements and disagreements with both pieces, I'm trying to figure out what Jaron Lanier is trying to do by publishing these views as he wears his Linden Labs hat. I can see how both lines of argument support Linden's business model: reinventing scarcity so their users' creations can command monetary value (horrifying example: unicorn babies via interspecies sex). What else is going on here? Can anyone familiar with Lanier's history clue me in on where his arguments come from, and where they're going?
Sepcifically, where ever did the NYTimes opinion originate? There have been plenty of examples of closed networks in the past, e.g. AOL, MSN, Prodigy, Compuserv, all of which have been crushed by the internet. In that sense, Free has already trumped Closed, and there's nothing us geeks "need" to do but enjoy it. In another sense, there are plenty of excellent examples of thriving markets, stores, and closed communities built on the internet and the web that implement the gettin'-paid features Lanier wants to see. What does Lanier want to see done differently? Credit card authorization built into TCP/IP?
Dec 17, 2007 8:16am
open gov
Last week, Carl Malamud had Shawn and I as guests at his Open Government Working Group meeting, held in O'Reilly's Sebastopol offices.
Ethan Zuckerman has one of the more comprehensive write-ups of this excellent event, as do John Geraci and Nat Torkington. Joseph Hall recorded Shawn's O.G. gang sign for posterity.
All I've got is this bag of links to mentioned projects and people, and the lasting conviction that Tom Steinberg's guruhood derives from him having tried everything.
Dec 3, 2007 7:42am
alaskan urbanism
For comparison:
"The last bit of Earth unclaimed by any nation-state was eaten up in 1899. Ours is the first century without terra incognita, without a frontier. Nationality is the highest principle of world governance--not one speck of rock in the South Seas can be left open, not one remote valley, not even the Moon and planets. This is the apotheosis of "territorial gangsterism." Not one square inch of Earth goes unpoliced or untaxed"
- Hakim Bey, found at Temporary Personal Urbanisms via Adam.
We stole countries! That's how you build an empire. We stole countries with the cunning use of flags! Sail halfway around the world, stick a flag in. "I claim India for Britain." And they're going, "You can't claim us. We live here! There's five hundred million of us." "Do you have a flag?" "We don't need a flag, this is our country you bastard!"
- Eddie Izzard, rendered in Lego.
Imagine living hundreds of miles from your nearest neighbor, having groceries and mail delivered by airplane a few times each year, and battling long, harsh winters with temperatures that plummet to -51 C. Such are the living conditions chosen by the hearty few who inhabit America's last frontier: the Alaskan bush - a spectacular land of rivers and mountains so remote that many remain unnamed. Through the cameras of National Geographic, you'll enter the lives of four families who have turned their backs on civilization to fulfill their dreams of living off the land. Join these modern-day pioneers as they face the daily challenges of survival - hunting for food, staying warm, and fending off grizzlies. You'll experience America's pioneering spirit through these remarkable people who are BRAVING ALASKA!
- Astonishing National Geographic documentary, very much worthwhile. Watch it, buy it.
Dec 1, 2007 6:19pm
in poland
I'm in Poland for a few days, surprising my brother for his 18th birthday.
The plane I flew in on is tiny:

Nov 24, 2007 11:47pm
univega
Last July, I found a crusty old 80's Univega road bike left out for the trash collectors across the street from our apartment. I'd been considering a project bike of some kind ever since getting and loving the IRO, and this seemed like a low-cost way to noodle with a new bike without breaking the bank. Today, after four months, I bent one of the handlebars back into shape, put on some symbolic tape, and finally called it done:

I've actually been using this thing as my primary bike for a few weeks now, mostly to work and on errands, but also the occasional fun ride.

My original idea was that it would be a utility/beater, so I made sure to get a rack and basket for the back. Doing complete food shopping runs and being able to haul a reasonable amount of stuff is liberating... faster than walking, no time wasted with parking, and loaded with endorphin-producing self-righteousness. I also took the whole thing to Adam at Pacific and asked him to check my work for me... there were a few loose or ungreased bits, and he rebuilt the bottom bracket.


I ended up keeping a lot of the original parts that weren't rusted into lumps. The front brake with giant, goofy lever had to stay.

The original wheels and cranks were garbage. I got these 27" Weinmann rims / Formula hubs from E-bay, and the Sugino cranks from Craigslist.


The first loose build had the cranks on the wrong side. Oops.

Originally I was expecting to keep just the frame. I had also planned to paint it, but I wasn't sure if it was going to be worth keeping. It's turned out to be as good a ride as my track bike, possibly even more comfortable due to the loopy, springy steel frame. I may paint it yet, though I'm certainly not going to drop $200+ to get it done professionally. Ultimately, it'd be nice for it to look like Scott Meyer's Univega on FGG.

Here's how I first found it:

Nov 20, 2007 9:03am
blog all dog-eared pages: science in action

Brian Marick's recent series on Actor-Network Theory (parts I, II, III, and IV) reminded me to dig up Science In Action for a fresh books post. I read this book a little over a year ago, after becoming interested in the philosophy of science through Karl Popper, and further diving has since led me to Paul Feyerabend, Thomas Kuhn, and Tracy Kidder's Soul Of A New Machine.
There are two big ideas I took away from this 20-year-old Bruno Latour book about the workings of science and technology. One is a figure-ground reversal akin to the NRA's famous slogan, "guns don't kill people, people kill people". The second is a description of the social conditions that make science possible. Latour frames his argument by introducing the concept of technoscience, his term for the kind of scientific inquiry that needs people, work, equipment, and funding - national laboratories, cancer research, particle physics, the sort of projects that Russell Davies recently described as thirteen smart guy problems in a post about Malcolm Gladwell.
The figure-ground reversal substitutes the common diffusion model with Latour's translation model. The former explains progress in terms of "ideas moving through society", while the latter places the people who act upon ideas in the foreground. People with desires and beliefs occupy the active role in Latour's world, moving ideas forward if they feel their own plans and agendas to be supported. Latour asserts that the diffusion model provides an inaccurate picture of technoscience, because it fails to account for the conscious agency of the technoscientists themselves. The book is well-stocked with examples of scientific and technological progress explained in terms of the people who linked their fates to a particular theory or invention: General Data's Tom West in Soul Of A New Machine, Rudolf Diesel's engine (and the MAN engineers and mechanics who eventually made it work), and the hypothetical "boss" of a biology laboratory.
Latour also shows how a social division between an inside (within the lab) and an outside (out in the world) make scientific and technical work possible. It is necessary to follow both to make any sense of "where" science happens: the outside supports the inside, allowing it to specialize, channeling funding, equipment, and personnel into the lab by enlisting and guiding the self-interest of universities, governments, and foundations towards to the interests of the lab itself. At the same time, the inside justifies the outside, producing results (process, technology) that fulfills the interests of those outside. On the boundary between the inside and outside sits the boss-figure, the scientist or engineer who motivates the lab and fights for its continued survival. "Firefighter up, cheerleader down" as my friend and first boss Darren used to say.
Science In Action has been quite a ride, and I've tried to apply its observations to my own company in a number of ways. For one, it has been instructive to think in terms of inside/outside with our activities, switching between "doing the work" and "talking about the work", having people specialize in one but not the other, and recognizing the importance of aligning the broader world's interests with our own. The time this becomes unusually rewarding are probably more frequent than we rightfully deserve: months of digging deep into nothing by maps, followed by a string of projects focused on images or time. It means we can juggle a lot of balls in the air without everyone fragmenting off into their own private corners. I've also recently sat in on the standards process behind OAuth, and have tried to judge it by Latour's translation model to see where good ideas were being moved about through conscious alignment of many groups' self-interests. I found this quite instructive.
Latour also has a way of describing the idea of a black box that resonates deeply. When I think back to my first visits to San Francisco (upper Haight when in High School, Bahia Cabana, the Mission, and downtown early in college), the city had not yet solidified in my mind, and I encountered each neighborhood on its own terms without a clear understand of how they fit together. The process by which novelty is transformed into familiarity and later background marks the passage of time. Sometimes it'd be nice to unlearn things at will.
Pages 91-92, on reification:
All biologists now take 'protein' for an object; they do not remember the time, in the 1920s, when protein was a whitish stuff that was separated by a new ultracentrifuge in Svedberg's laboratory. At the time protein was nothing but the action of differentiating cell contents by a centrifuge. Routine use however transforms the naming of an actant after what it does into a common name. This process is not mysterious or special to science. It is the same with the can opener we routinely use in our kitchen. We consider the opener and the skill to handle it as one black box which means that it is unproblematic and does not require planning and attention. We forget the many trials we had to go through (blood, scars, spilled beans and ravioli, shouting parent) before we handled it properly, anticipated the weight of the can, the reactions of the opener, the resistance of the tin.
Page 107, on phasing:
If the notion of discrete phases is useless, so, too, is that of trajectory. It does not describe anything since it is again one of the problems to be solved. Diesel indeed claimed that there was one trajectory which links his seminal patent to real engines. This is the only way for his patents to be 'seminal'. But this was disputed by hundreds of engineers claiming that the engine's ancestry was different. Anyway, if Diesel was so sure of his offspring, then why not call it a Carnot engine since it is from Carnot that he took the original idea? But since the original patent never worked, why not call it a MAN engine, or, a constant pressure air injection engine? We see that talking in phases in a trajectory is like taking slices from a pate made from hundreds of morsels of meat. Although it might be palatable, it has no relation whatsoever to the natural joints of the animal.
Page 137, on cameras and black boxes:
Let us remember Eastman's Kodak camera. It was simpler to operate than anything else before. 'Push the button, we'll do the rest,' they said. But they had to do the rest, and that was quite a lot. The simplification of the camera that made it possible to interest everyone in its dissemination in millions of copies had to be obtained by the extension and complication of Eastman's commercial network. When you push the button you do not see the salesmen and the machines that make long strips of celluloid films and the troubleshooters that make the coating stick properly at last; you do not see them, but they have to be there none the less. If they are not, you push the button and nothing happens. ... If we have understood this, then we may draw the conclusions from the two first parts of this chapter: the black box moves in space and becomes durable in time only through the actions of many people; if there is no one to take it up, it stops and falls apart however many people may have taken it up for however long before. But the type, number, and qualifications of the people in the chain will be modified: inventors like Diesel or Eastman, engineers, mechanics, salesmen, and maybe 'ignorant customers' in the end. To sum up, there are always people moving the objects along but they are not the same people all along.
Page 141, on diffusion vs. translation and why society is a fiction:
Among all the features that differ in the two models, one is especially important, that is society. In the diffusion model society is made up of groups which have interests; these groups resist, accept, or ignore both facts and machines, which have their own inertia. In consequence we have science and technics on the one hand, and a society on the other. In the translation model, however, no such distinction exists since there are only heterogeneous chains of associations that, from time to time, create obligatory passage points. Let us go further: belief in the existence of a society separated from technoscience is an outcome of the diffusion model. Once facts and machines have been endowed with their own inertia, and once the collective action of human and non-human actors tied together has been forgotten or pushed aside, then you have to make up a society to explain why facts and machines do not spread.
Page 152, on specialization and isolation:
...an isolated specialist is a contradiction in terms. Either you are isolated and very quickly stop being a specialist, or you remain a specialist but this means you are not isolated. Other, who are as specialized as you, are trying out your material so fiercely that they may push the proof race to a point where are of your resources are barely enough to win the encounter. A specialist is a counter-specialist in the same way as a technical article is a counter-articles (Chapter 1) or a laboratory is a counter-laboratory (Chapter 2).
Page 155, defining outside and inside:
This case shows how important it is to decide who are the people to study. Depending on which scientist is followed, completely different pictures of technoscience will emerge. Simply shadowing West or the boss will offer a businessman's view of science (mixture of politics, negotiation of contracts, public relations); shadowing the microkids or the collaborators will provide the classic view of hard-working white-coated scientists wrapped up in their experiments. In the first case we would be constantly moving outside the laboratory; in the second, we would stay deep inside the laboratory. Who is really doing research? Where is the research really done?
Page 156, more on inside and outside:
The first lesson to be drawn from these examples is rather innocuous: technoscience has an inside because it has an outside. There is a positive feedback loop in this innocuous definition: the bigger, the harder, the purer science is inside, the further outside other scientists have to go. It is because of this feedback that, if you get inside a laboratory, you see no public relations, no politics, no ethical problems, no class struggle, no lawyers; you see science isolated from society. But this isolation exists only in so far as other scientists are constantly busy recruiting investors, interesting and convincing people.
Pages 231-232, on modeling space and time:
Professor Bijker takes a metre-long plaster model of a new dam, fixes it into place and launches a first round of tides shortened to twelve minutes; then he takes it out, tries another one and continues. Sure enough, another 'Copernican revolution' has taken place. There are not that many ways to master a situation. Either you dominate it physically; or you draw on your side a great many allies; or else, you try to be there before anybody else. How can this be done? Simply by reversing the flow of time. Professor Bijker and his colleagues dominate the problem, master it more easily than the port officials who are out there in the rain and are much smaller than the landscape. Whatever may happen in the full-scall space-time, the engineers will have already seen it. They will also have become slowly acquainted with all the possibilities, rehearsing each scenario at leisure, capitalising on paper possible outcomes, which gives them years of experience more than others. The order of time and space has been completely reshuffled. Do they talk with more authority and more certainty than the workmen building the real dam there? Well, of course, since they have already made all possible blunders and mistakes, safely inside the wooden hall in Delft, consuming only plaster and a few salaries along the way, inadvertently flooding not millions of hard-working Dutch but dozens of metres of concrete floor.
Pages 248-249, where it all breaks down:
When the architects, urbanists and energeticians in charge of the Frangocastello solar village project in Crete had finished their calculations in early 1980 they had in their office, in Athens, a complete paper scale model of the village. They knew everything available about Crete: solar energy, weather patterns, local demography, water resources, economic trends, concrete structures and agriculture in greenhouses. They had rehearsed and discussed every possible configuration with the best engineers in the world and had triggered the enthusiasm of many European, American, and Greek development banks by settling on an optimal and original prototype. Like Cape Canaveral engineers the had simply to go 'out there' and apply their calculations, proving once again the quasi-supernatural power of scientists. When they sent their engineers from Athens to Frangocastello to start expropriating property and smoothing out the little details, they met with a totally unexpected 'outside'. Not only were the inhabitants not ready to abandon their lands in exchange for houses in the new village, but they were ready to fight with their rifles against what they took as a new American atomic military base camouflaged under a solar energy village. The application of the theory became harder every day as the mobilisation of opposition grew in strength, enrolling the pope and the Socialist Party. It soon became obvious that, since the army could not be sent to force Cretans to occupy willingly the future prototype, a negotiation had to start between the inside and the outside. But how could they strike a compromise between a brand new solar village and a few hundred shepherds who simply wanted three kilometres of asphalted road and a gas station? The compromise was to abandon the solar village altogether. All the planning of the energeticians was routed back inside the network and limited to a paper scale model, another one of the many projects engineers have in their drawers. The 'out-thereness' had given a fatal blow to this example of science.
Page 249, networks and a conclusion by way of prediction:
So how is it that in some cases science's predictions are fulfilled and in some other cases pitifully fail? The rule of method to apply here is rather straightforward: every time you hear about a successful application of science, look for the progressive extension of a network. Every time you hear about a failure of science, look for what part of which network has been punctured. I bet you will always find it.
Nov 11, 2007 7:54am
more like faumaxion
Earlier this week I posted a bungled attempt at implementing Buckminster Fuller's Dymaxion World Map. Owing to a rainy Saturday, that first pass at understanding the projection has matured into something a bit more stable and applicable.
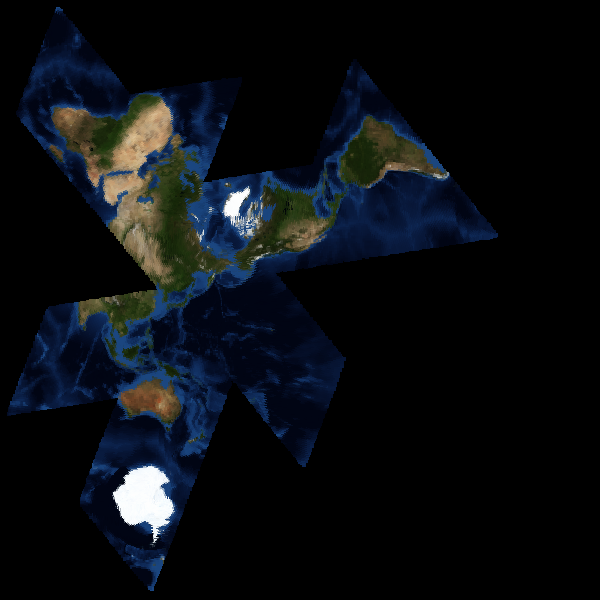
I've been working from Robert Gray's C Implementation of the world map, but after getting it working I ended up discarding it. There are a few limitations with Fuller's projection math and Gray's implementation. I decided to stick with the icosahedron layout on the original map, but switched to the gnomonic projection, similar to Fuller's but blessed with an inverse:
... in computer applications where you "click" on a position on the flat map to get an (x,y) coordinate pair, and you have to convert this to the corresponding (longitude, latitude) coordinate pair, you would have to "loop through" Fuller's projection method several times to get an approximate answer whereas in the Gnomonic case, there is no looping, you have an exact "inverse" equation. -Robert Gray
The gnomonic does pretty much exactly the right thing, in much less space. In effect, each triangular face of the main icosahedron becomes a little projection of its own, accurate at the center and a little less-so at the edges. The general idea is that maps can be arranged about any point on the earth's surface without computationally expensive image reprojection, and with a minimum of surface tearing near the center.
Gray's example code also has just one unfolding of the map hard-coded, making it difficult to create flexible arrangements of land masses for specific needs. It's more interesting to have a version that supports a variety of layouts, like these views centered on various parts of the Atlantic:

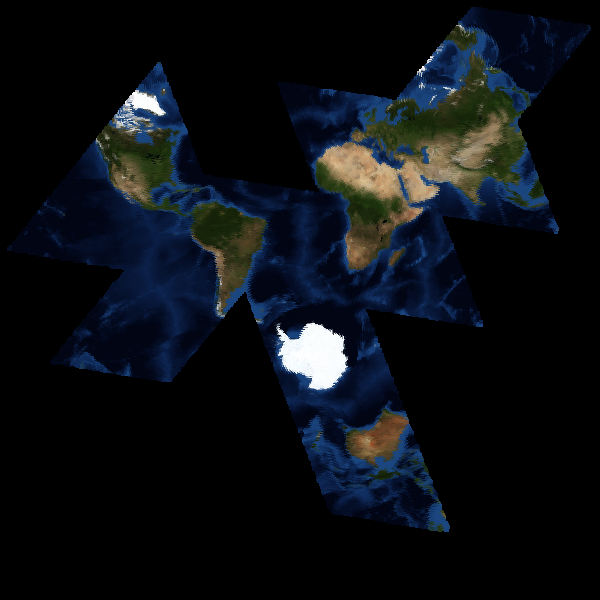
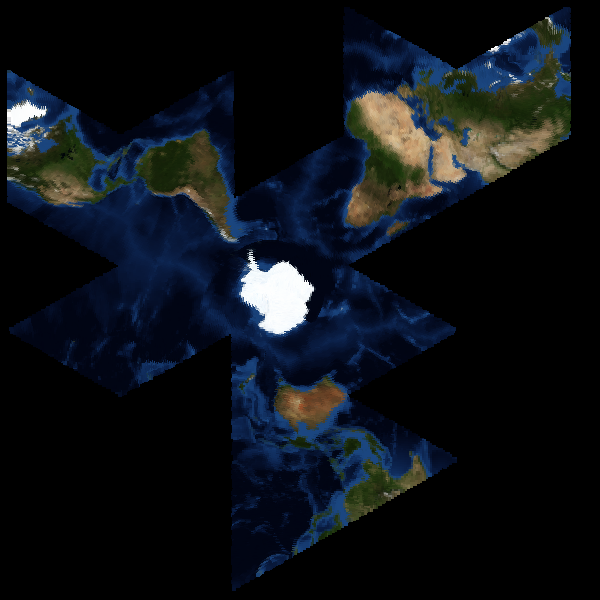
The surface coloration I use is from NASA's Blue Marble satellite image set, something I've written about before. I'm not yet sure how to go about making the faumaxion code public, but I imagine that it may find its way into Modest Maps some time in the future.
Nov 6, 2007 8:41pm
not necessarily dymaxion
This is the first output of a raw Python port of the Fuller Dymaxion projection.
It's not quite the thing, but cool nonetheless:

Oct 29, 2007 7:08am
blog all dog-eared pages: where the suckers moon

(This is a regular series, see previous entries on Kuhn, Whyte, Buxton, Kidder, Whyte again, Levinson, Edgerton, and a recent name-check from Adam)
Where The Suckers Moon is Randall Rothenberg's account of Subaru's search for an advertising agency in the early 1990s and the campaign that resulted. It traces the strange roots of the car company, diverts into histories of the advertising industry, communications, semiotics, and psychology, and follows the creation of a campaign from its first creative development through the trenches of production and out to public release.
The first half of the book is largely historical, and doesn't provide a lot of quotable material for these excerpts. That's not to say it isn't good reading, just doesn't chunk well.
Reading this book reminded me of the blessing and curse that is YouTube. A blessing, because many of the early 1990s ads described in the narrative are readily available on Google's monster video sharing site, such as Tibor Kalman's work for Pepe Jeans. This ad has lurked in my subconscious for the past 17 years. A curse, because anything of recent interest is inevitably scrubbed from YouTube at a rapidly accelerating clip. Exhibit A is my post on the London 2012 identity I love so dearly, whose linked videos have been pulled for bullshit copyright reasons. I have a half a mind to write the minimal amount of Python and Actionscript it would take to mirror posted videos and keep them as presentable as they are now - the hive mind shared memory functions of sites like YouTube and OiNK are as deeply valuable as the communicative functions of the recorded media they store and share.
Anyway, on to the excerpts.
Page 211, on pomo:
Beyond placing emphasis in filmmaking technique, Wieden & Kennedy's Lou Reed ad helped foster the development of a postmodern sensibility in the advertising industry. In the minds of the youngsters who were entering the business, advertising no longer had to be advertising, or entertainment. It could be, in Larry Bridge's phrase, "metacommentary": art that explicated, through irony, camp, iconic references or self-reference, the commercial itself and the consumer culture of which it was a part. It was a living, evolutionary answer to Walter Benjamin's denial that art could exist in the modern era - "that which withers in the age of mechanical reproduction is the aura of the work of art."
Page 212-213, on pomo some more:
It may have looked like "metacommentary", but semioticians term it a "false metacommunication" because, through its production techniques, it pointed the viewer in a wrong direction - toward the preferred interpretation of freedom and license - in order to mask its covert purpose, selling mass-manufactured goods, which it did by the implicit linkage of the product with the message of independence. Robert Goldman and Steve Papson, sociologists who have studied this school of advertising, refer to it, with good reason, as "the postmodernism that failed."
Page 225, on conflicted creative direction:
And the truth was this: Jerry Cronin, the new creative director on Subaru of America's advertising account, despised cars. ... "I always hated cars," Jerry said one day in his office. "I didn't own a car until I was twenty-eight. We had no money when I was growing up. We always had these old Ramblers. I always heard the old man complaining about cars. Every time he left the house, he never knew whether the car would get him home." ... "People are far too attached to their cars. I want them to see that cars are a hunk of metal. Automotive advertising is the biggest lie of all time. You want to live better, look better - buy a grill, go to the gym!"
Page 230, on art direction influences:
Jerry was thinking. What he was looking for was inspiration. He had already decided that the look he wanted derived from the heroic Social Realism prevalent in public and commercial art during the 1930s - the "dawn-of-the-Machine-Age" style popularized in friezes by the Works Progress Administration and photographs in Life. That this look was also prevalent in the hortatory art of both Hilter's Germany and Stalin's Soviet Union did not escape the agency men. Larry sent his assistant to a local video store to pick up a copy of Leni Riefenstahls's Olympiad, a celebration of Nazi power, to review it for cinematographic stimulation.
Page 301, on Chait/Day and fighting clients:
Watching the agency win, and build, Apple Computer and Yamaha motorcycles and other prestigious accounts taught Luhr the essential lessons of account management in the era of postmodern advertising. To do good work was the purpose of advertising, he learned. And good creative people didn't operate by the same rules by which, say, good bankers do. And clients don't always recognize the value of good creative work or good, quirky creative people, so an account exec had to be prepared to fight the client, anger the client, even risk dismissal or fire the client if the going got too debilitating.
Page 309, on slow hiring:
Everything Wieden & Kennedy was grew out of a creative philosophy that required immersion in the convolutions of American culture, everything the agency could be depended on the collegial spirit of the men and women who filled its offices. Although hundreds of creatives at other agencies across the land would have overturned their lives for a chance to work, however briefly, at Wieden & Kennedy, Dan was not an easy mark. You can't just... just... hire people overnight! You have to talk to them, again and again and again, test them, tease them, scrutinize their work and their philosophies. Since it was difficult to schedule time with Dan (his insistence on approving everything that went on in the agency made him difficult to pin down) Wieden & Kennedy generally took months to hire even relatively junior copywriters and art directors. On the Subaru account, the delays took their toll.
Page 328, on faith:
Faith, while hard won, is easily lost. It can be shaken by many things: misguided words, obstinacy, an inability to grow along with one's partner, suddenly seeing the partner through eyes unblinded by desire. Relationships, of course, are maintained by faith. No matter how fervently contemporary ad agencies insist that they are entertainers or artists, advertising is still founded on relationships. So in advertising, as in marriage, a loss of faith can be debilitating. It is the only quality, really, that binds a client to an agency.
Page 415, on reading between the lines:
"And so this campaign really does explain the key features of the car," Walter said, "in a very simpleminded way, not unlike the way Lexus is doing it." (Features: That meant Wieden & Kennedy had learned to talk about engineering. Simpleminded: That showed the agency was not striving to be creative. Lexus: That proved the agency had learned to sell by overselling.) "It hits on something we learned in the research: Impreza considerers need to be sold." (Research: That meant the work wasn't the invention of artsy types. Sold: That spoke again to the agency's new willingness to huckster.) "It also has a new tactical element, a videotape that we'll send consumers and ask them to respond to, via toll-free number." (Tactical: That showed Wieden & Kennedy was ready to deploy gimmicks. Toll-free number: The kind of gimmicks used by the big, boring agencies in New York.)
Page 427, in conclusion:
Subaru of America had learned the lesson of advertising. Advertising did not work by entertaining or assaulting the intellect of its audience, as the company's previous agencies had believed. Nor did it work through subliminal manipulation, as so many Americans, ever on the lookout for conspiracies, misguidedly thought. Instead, advertising, as the great ad man Bruce Barton had acknowledged decades before, was "something big, something splendid, something which goes deep down into an institution and gets hold of the soul of it." To succeed, advertising cannot seek to invent a new soul. Instead, it must reinforce and redirect the existing image. It must serve as a form of mythology, providing the corporation's various and often competing constituencies - of which consumers are only one of many - heroes, villains, principles, rules of conduct and stories with which they can rally the faithful to remain true to the cause. Only then, with luck and effort, can they win new converts.
Oct 26, 2007 12:17am
animated gif theatre
Three good ones today:
Do Not Fall Down

(via Enough Of Your Borax, Poindexter)
So This Bird Walks Into A Store...

(via The Animated GIF Appreciation Society)
Animéted GIF

(also via Enough Of Your Borax, Poindexter)
Previously: Bunny Emoticons.
Oct 11, 2007 1:21am
atkinson dithering
Turns out Atkinson dithering is really easy, for that classic Mac look!

Here's a minimal Python implementation (requires PIL).
Oct 10, 2007 9:51pm
branding a fuckup
Errors in software used to just happen to one computer at a time.

Web applications mean that errors happen to lots and lots of people, all at the same time, often when they'd really rather be getting something done. Spurred on by Flickr, developers and designers have taken to adding a bit of personality to their branded error pages:
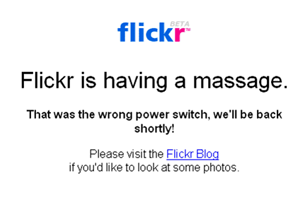

See more at: Who Has The Best Sorry Page?
"Sorry pages" are like a category of folk art unto themselves. They defuse a possibly difficult situation ("I can't get to my photos!") with humor, and help communicate expectations without overly technical jargon.
Keeping your applications on the web also means that moving your data around between apps is complicated. OAuth has jumped into the fray with a new standard for 3rd party API authentication. It's an extraction of several examples currently in the wild, and is designed to allow users of a service to grant temporary permission to a 3rd party to access their private data. It needs to be safe and revokable, and keep data consumers from having to ask users for their passwords. I've been watching this effort from a short distance, and I can honestly say that I have no desire to see politics, sausage, or technical specs get made. Especially when crypto-nerds get involved.
Read the OAuth page for an explanation of what they're on about, and what they've created.
OAuth mostly succeeds, but there's one new-to-me addition to the spec that dangerously interferes with meaningful, attributable Sorry pages like the ones illustrated above. I've written before about the niceties of Google Authsub, specifically the way it opens the door to experimentation without a pre-existing relationship with Google. OAuth has introduced a step into its specified flow that I think is a bad idea: instead of just sending the user to a service provider's authentication page, it's first necessary for the Consumer (the ones that want to access a user's data) to perform a little behind-the-scenes sleight of hand with the Provider (the app where the user's data lives) in order to juggle some keys back and forth. If this step fails, it's up to the Consumer to figure out what went wrong and report to the User that something has gone wrong, instead of letting the Provider do so themselves via their usual language / design: upside-down birds, Admiral Ackbar, massages, etc. There's a world of difference between a printer telling you "Flickr's not working" and you seeing it for yourself, and getting the comforting "massage" response that also tells you what's going on, whether it's unexpected, and when you might get to play with your toys again.
Sep 29, 2007 5:43am
remission
Even though they haven't released anything worth listening to since Dwayne Goettel died in 1995, Skinny Puppy has been a favorite band of mine since I first heard them 15 years ago.
Most of the ice-cold music I've posted here in the past has been, to my ears, directly descended from Skinny Puppy's 1984 EP, Remission. It's a perfect example of self-confidence absent the inflated expectations of a demanding fanbase, a trait also found in early Orbital records and Skinny Puppy's later albums Bites and Mind: T.P.I.

Sep 27, 2007 2:10am
whole foods
Oakland's first Whole Foods Market opened up today.
Here are some photos from when Gem and I visited in June, 2005:

Sep 24, 2007 12:53am
gefingerpoken
One of the core gestures in a multi-touch interface is the two-finger deforming drag, a descendent of the traditional mouse-driven drag and drop. The difference is that with two points of contact, interface elements such as windows can be moved, stretched, and turned. See what this would look like in a real interface five seconds into the big-ass table video. Implementing two-finger drag turns out to be less-than-obvious, but I've put together a short demo (see also a larger version with source code) that shows how to do it easily.
Drag the fingers and pretend they're your own:
There are two main difficulties: figuring out how precisely the two contacts should act on an object, and then translating those into the appropriate placement, sizing, and rotation of the object. We start with two rules: the object can be moved and turned, but not skewed, squashed, or otherwise deformed, and the fingers should stay in contact with the same points on the object throughout their movement.
Both troubles can be solved with the use of affine transformation matrices, the closest thing computer science has to a true, working hammer. I've described before how to derive a complete transformation from just three example points, so we need to figure out where to place a third point to complement the two fingers above. If we assume that the line between the two fingers is the hypotenuse of a right equilateral triangle, the we can guarantee a stable position for the invisible third finger by working out the two legs of the complete triangle. See it in action above when you drag.
Since version 8 or so, Flash has exposed proper matrix transformations on all clips in addition to the usual x, y, rotation, and scale. Unfortunately, the documentation leaves something to be desired, but it's possible to make Flash's Matrix class behave like it's supposed to by juggling a few of the arguments. After deriving a complete transformation from the movement of the two-finger triangle, we can apply it to the UI object and get something that moves properly.
Look out for two important functions in the source code:
- deriveThirdPoint() builds the triangle and adds a third ghost finger to the two physical ones.
- deformBox() applies the three fingers to repeatedly transform the photograph so that the fingers appear to be dragging it around the screen.
Sep 14, 2007 1:57am
blog all dog-eared pages: the structure of scientific revolutions

I first heard the term "paradigm shift" in high school (journalism camp, 1994, oh yeah). It gets used a lot these days, especially in the field of web technology, where every new web service, development framework, and business plan is a game changing paradigm shift. Curious where the term originated, I was led to Thomas S. Kuhn's The Structure of Scientific Revolutions, a 1962 essay seeking to explain changes in scientific belief over time. Kuhn's central argument is that progress does not happen by slow accretion of ideas over time, but by periods of stable work ("normal science") punctuated by crisis and rapid change ("paradigm shifts"). Crises are brought about by an accumulation of problems closed to normal scientific work, and are resolved through gestalt shifts that change research agendas and dominant theories.
The book also includes a 1969 postscript that flips the impact of the book on its head a bit. I've always seen the essay's argument as broadly applicable to other fields, but Kuhn says he developed it by applying the lessons of other fields to science.
Page 208, on applicability:
To one last reaction to this book, my answer must be of a different sort. A number of those who have taken pleasure from it have done so less because it illuminates science than because they read its main theses as applicable to many other fields as well. I see what they mean and would not like to discourage their attempts to extend the position, but their reaction has nevertheless puzzled me. To the extent that the book portrays scientific development as a succession of tradition-bounds periods punctuated by non-cumulative breaks, its theses are undoubtedly of wide applicability. But they should be, for they are borrowed from other fields. Historians of literature, of music, of the arts, of political development, and of many other human activities have long described their subjects in the same way. Periodization in terms of revolutionary breaks in style, taste, and institutional structure have been among their standard tools. If I have been original with respect to concepts like these, it has mainly been by applying them to the sciences, fields which had been widely though to develop in a different way.
On to the meat of the book...
Pages 2-3, on what is scientific:
The more carefully they study, say, Aristotelian dynamics, phlogistic chemistry, or caloric thermodynamics, the more certain they feel that those once current view of nature were, as a whole, neither less scientific nor more the product of human idiosyncrasy than those current today. ... Out-of-date theories are not in principle unscientific because they have been discarded.
Page 5, on normalcy:
Normal science, the activity in which most scientists inevitably spend most all their time, is predicated on the assumption that the scientific community knows what the world is like. Much of the success of the enterprise derives from the community's willingness to defend that assumption, if necessary at considerable cost. Normal science, for example, often suppresses fundamental novelties because they are necessarily subversive of its basic commitments. Nevertheless, so long as those commitments retain an element of the arbitrary, the very nature of normal research ensures that novelty shall not be suppressed for very long.
Page 20, on the coincidence of intelligibility and paradigm boundaries:
Both in mathematics and astronomy, research reports had ceased already in antiquity to be intelligible to a generally educated audience. In dynamics, research became similarly esoteric in the later Middle Ages, and it recaptured general intelligibility only briefly during the early seventeenth centrury when a new paradigm replaced the one that had guided medieval research. Electrical research began to require translation for the layman before the end of the eighteenth century, and most other fields of physical science ceased to be generally accessible in the nineteenth.
Page 55, on discovering:
Clearly we need a new vocabulary and concepts for analyzing events like the discovery of oxygen. Though undoubtedly correct, the sentence, "Oxygen was discovered," misleads by suggesting that discovering something is a single simple act assimilable to our usual concept of seeing. That is why we so readily assume that discovering, like seeing or touching, should be unequivocally attributable to an individual and to a moment in time. But the latter attribution is always impossible, and the former often is as well.
Page 76, on crisis and retooling paradigms:
So long as the tools a paradigm supplies continue to prove capable of solving the problems it defines, science moves fastest and penetrates most deeply through confident employment of those tools. The reason is clear. As in manufacture so in science - retooling is an extravagance to be reserved for the occasion that demands it. The significance of crises is the indication they provide that an occasion for retooling has arrived.
Page 88, on introspection during crisis:
It is no accident that the emergence of Newtonian physics in the seventeenth century and of relativity and quantum mechanics in the twentieth should have both been preceded and accompanied by fundamental philosophical analyses of the contemporary research tradition. Nor is it an accident that in both of these periods the so-called thought experiment should have played so critical a role in the progress of research. As I have shown elsewhere, the analytical thought experimentation that bulks so large in the writings of Galileo, Einstein, Bohr, and others is perfectly calculated to expose the old paradigm to existing knowledge in ways that isolate the root of crisis with a clarity unattainable in the laboratory.
Page 122, on the suddenness of paradigm shifts:
Paradigms are not corrigible by normal science at all. Instead, as we have already seen, normal science ultimately leads only to the recognition of anomalies and to crises. And these are terminated, not by deliberation and interpretation, but by a relatively sudden and unstructured event like the gestalt switch. Scientists often speak of the "scales falling from the eyes" or of the "lightning flash" that "inundates" a previously obscure puzzle, enabling its components to be seen in a new way that for the first time permits its solution.
Pages 150-151, on generational shifts:
How, then, are scientists brought to make this transposition? Part of the answer is that they are very often not. Corpernicanism made few converts for almost a century after Copernicus' death. Newton's work was not generally accepted, particularly on the Continent, for more than half a century after the Principia appeared. ... And Max Planck, surveying his own career in his Scientific Autobiography, sadly remarked that "a new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die."
Page 164, on choice of problem:
Unlike the engineer, and many doctors, and most theologians, the scientist need not choose problems because they urgently need solution and without regard for the tools available to solve them. In this respect, also, the contrast between natural scientists and many social scientists proves instructive. The latter often tend, as the former almost never do, to defend their choice of a research problem - e.g. the effects of racial discrimination or the causes of a business cycle - chiefly in terms of the social importance of achieving a solution. Which group would one then expect to solve problems at a more rapid rate?
Sep 6, 2007 12:16am
algebra 2.0
Wordie: Like Flickr, but without the photos.
FFFFOUND! is a web service that ... allows the users to post and share their favorite images found on the web.
wordie.org + ffffound.com = flickr.com
wordie.org = flickr.com - ffffound.com
flickr.com - wordie.org = ffffound.com
wordie.org - flickr.com + ffffound.com = 0
Sep 3, 2007 5:41pm
dave winer on twitter
By way of followup to that last post, can I say that Dave Winer has the best Twitter background image + user icon combination ever?


Sep 2, 2007 6:16am
uselessness
As one of the people responsible for Twitter Blocks (really it was Ryan and Tom who made it - on this project, I'm "management"), it's been interesting reading feedback to the project's launch. Tom summarized a particular strain of it as Criticism For Twitter Blocks. Go, read.
...
So we get this a lot: "Beautiful! But useless!". We've heard it in response to most projects we've done over the past few years (one exception has been Oakland Crimespotting, whose stock yokel response is: "no way am I moving to Oakland!").
By now, we're fairly accustomed to it. I've historically stayed mum, in the belief that this particular critique is best met with silence, because what is there to add? This current case rankles a bit, since a lot of those snarks are coming via Twitter, Pownce, and Jaiku messages. Twitter is practically the "fun, but useless, but oddly popular" poster child of the moment, so it's ironic to see people who've taken the leap to its particular brand of short-messaged-based playtime suddenly waxing utilitarian (for example, Dave Winer). Tom argues that it's worth focusing on fun once in a while instead of just utility, monetization, and features. I'm arguing that a lot of the people crowing "but useless!" have already taken that plunge, yet lack the self-awareness or humility to see it for what it is. There are plenty of but-useless things in the world that serve as emotional bonding points, amusements, attractions, and macguffins. Practically all of social media falls under this category for me, a form of mediated play that requires a suspension of disbelief in rational purpose to succeed.
There are of course legitimate reasons to find Twitter and Blocks annoying: Blocks likes teh CPU, not everyone enjoys frequent tiny updates from people, there are jerks in any social service, Blocks has a big Motorola ad next on it, and so on. Worries about Obvious Corp.'s business sustainability and freakouts that Blocks was launched (by us) despite the presence of bugs in Twitter are not legitimate reasons.
But, since we're on the topic, I'm going to suggest that Blocks is our hat in the ring for traversing the social graph. Unlike the friends views on the existing site, the only people who show up are guaranteed to be recently active, so there's no deadwood problem. Also unlike the existing friends view, we've introduced two dimensions to show a second degree of separation, leading to regular "I had no idea so-and-so was on Twitter" moments since the first experimental layouts were done and presented one month ago. Also, it doesn't look like some suck-ass sticks-and-rocks graph.
Sufficiently useful?
Aug 31, 2007 12:51am
digg arc history
I just posted a visual diary of Digg Arc development to the Stamen blog. Go check it out, and relive the glory...





Aug 29, 2007 1:53am
minilogue
Two Minilogue tracks doing it for me today:
- Inca (26.9MB)
- Certain Things About Us, Part 1 (15.2MB)
This is also not half bad:
- Audion: Fire (14.9MB)
Aug 21, 2007 6:53am
oakland crime maps IX: post-launch
Last week, we launched Oakland Crimespotting, capping off eight months of the occasional data sketching I've been recording on this site. I've covered a few speculative topics here that didn't graduate to the public version of the site, and there have been a number of interesting new things that were sure to add.
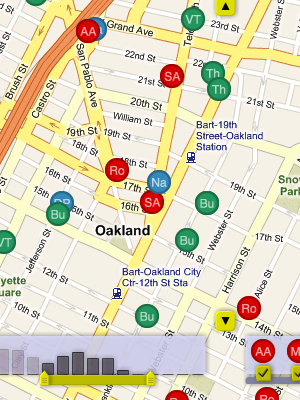
The initial work on scraping (post I, post II) is still in use. Thankfully, the city hasn't changed CrimeWatch much since December, so our nightly collection runs are still chugging along happily. We do four collections every evening: past four days, and then individual days a week, two weeks, and one month in the past. The overlap is because we've noticed that the Oakland PD amends and modifies crime reports, and the whole map site is frequently down altogether.
Two later pieces (post III, post IV) introduced an idea on time-based display, but ultimately it was effective to just drop in the dots and add live draggy/zoomy controls. This is something we've consistently found with other projects, too: it's so often the case that the "right" design is not the technically complicated one, but the one that gets feedback and interactivity just so.
Finally, I wrote up a few pieces (post VI, post VII) on public data indexing. This is something I continue to find interesting, but at the volume of traffic we're pushing, it's totally unnecessary. Turns out MySQL is kind of awesome at this sort of thing.
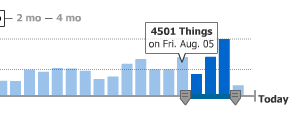
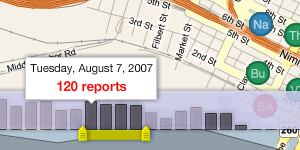
There are two big features on the map interface that only emerged when designing and developing it with Tom and Eric. The date slider is something that we shamelessly nicked from Measure Map, though we added the bit where per-day columns act as a display showing which data has been loaded. This part is still under active development. The idea is that the background should be draggable, to allow people to navigate back further in time than 30 days.
Measure Map:
Ours:
The second is the crime type picker, an interface whose affordances we borrowed from Newsmap. This one's quite simple, but it does trigger the visual spotlight effect that makes it possible to pick out crimes of a certain type throughout the map.
Newsmap:
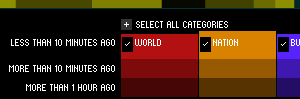
Ours:
It was important that every view of the map be linkable and sharable, so we imported a number of ideas that Tom developed for our last map project, Trulia Hindsight. The thing to watch for is how the URL of the page you're looking at changes as you pan and zoom around. It can be copied, shared in an e-mail, sent over IM to a friend, and posted in a blog.
An "official" API has not been described or announced, but it will most likely include the site's Atom / GeoRSS feeds. These implement a small subset of the OpenSearch request specification:
- bbox is a geographical bounding box in the order west, south, east, north.
- dtstart and dtend are start and end dates, in YYYY-MM-DDTHH:MM:SSZ format.
Look for these hanging off of the /crime-data endpoint.
The site is hosted on Amazon's EC2 service, on a 10 cent/hour virtual server running Debian Linux, MySQL, Apache, and PHP. The static maps are generated by Aaron Cope's recent addition to Modest Maps, ws-compose.py. It's a BaseHTTPServer that stitches tiles into map PNG's, and I've been running four of them (and caching the responses) for the past week with no troubles.
I've rediscovered the joys of procedural PHP4 with this project. EC2 has proven to be a real champ, allowing us to set up a test machine, deploy a living site, but always holding out the possibility of migration to a "real" server. At a total of $80/month, the virtual Debian machine may last for a while.
Next steps may include San Francisco and Berkeley.
Aug 15, 2007 11:16pm
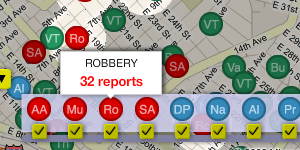
oakland crime maps VIII: first public launch
I promised we'd have something to show, right? In response to the red wave of homicides that swept Oakland two weeks ago, Tom and I published a visual map of crime reports in Oakland.
I'll write more later, but for now go and explore.

Aug 10, 2007 4:31pm
ffffound! updated
FFFFOUND! got some updates that seem to answer two of my comments from last week. I now know who my followers are, and whose images I consistently like. Something interesting I pay attention to when browsing the site: because it's Japanese there are a lot of obviously-Japanese usernames around. The list of my followers seems to be largely "western" names. I'm curious if a closer look at the site would reveal any clear difference in tastes between the U.S./Euro and Asian user populations? I do tend to post a lot of characteristically western images. I also consider it a feature that the site is so image-focused that there's not generally very much text around.

Aug 5, 2007 7:04pm
blog all dog-eared pages: the social life of small urban spaces

The Social Life of Small Urban Spaces is a brief book on urban plaza design from William Whyte, author of The Organization Man. Here, Whyte focuses on behavior in urban plazas of the sort generally found at the foot of corporate skyscrapers in New York, San Francisco, and other major cities. Various building ordinances and rules require that developers include such plazas in their design, but they are wind-blown and vacant as often as not. This book is the summary of an ethnographic study of these spaces, based on extensive filming of use patterns in 1980.
As with Organization Man, Whyte is a sharp observer and pithy commentator.
Social Life focuses on several topics in turn: crowds (and why people like them), sitting space, fountains, bums, food vendors, and filming techniques for study. The book argues that architects and developers imbue their developments with an emotional tenor that people instinctively pick up on, and shows how it affects use and health. There's a lot here that's directly applicable to social systems on the web, such as passages on distrustful design and "megastructures", the car-focused, inward-facing malls and complexes popular in cities over the past few decades. Whyte isn't optimistic about their future, and I think there are lessons to be learned by inward-facing online destinations such as Facebook.
In the same vein, Wired editor Chris Anderson recently gave up on Second Life because "if you're going to evoke real world conceits such as "places" that you "go to", then you've got to deal with real world expectations of those places. We don't like like empty buildings in RL; why should be more tolerant of them in SL just because there are traces of those who have been there before?"
Overall, Whyte's focus on describing use shows how optimistic architectural renderings break down in the face of natural human use patterns. I especially enjoyed the contrast between Whyte's choice of images for an example megastructure, the Detroit Renaissance Center. Here's an image typical of Google's image results for the center:

Here's Whyte's street-level view:

Bleak.
It's a hopeful book, though - no problem seems insurmountable in the face of realistic expectations and a hot dog stand or two.
Page 19, on crowds:
What attracts people most, it would appear, is other people. If I belabor the point, it is because many urban spaces are being designed as though the opposite were true, and that what people liked best were the places they stay away from. People often do talk along such lines; this is why their responses to questionnaires can be so misleading. How many people would say they like to sit in the middle of a crowd? Instead, they speak of getting away from it all, and use words like "escape", "oasis", "retreat". What people do, however, reveals a different priority.
Page 23, on similarity:
The strongest similarities are found among the world's largest cities. People in them tend to behave more like their counterparts in other world cities than like fellow nationals in smaller cities. Big-city people walk faster, for one thing, and they self-congest. ... Modest conclusion: given the basic elements of a center city - such as high pedestrian volumes, and concentrations and mixtures of activities - people in one place tend to act much like people in another.
Page 33, on benches:
Benches are artifacts the purpose of which is to punctuate architectural photographs. They're not so good for sitting. There are too few of them; they are too small; they are often isolated from other benches or from whatever action there is on the plaza. Worse yet, architects tend to repeat the same module in plaza after plaza, unaware that it didn't work very well in the first place.
Page 35, on chairs:
The possibility of choice is as important as the exercise of it. If you know you can move if you want to, you feel more comfortable staying put. This is why, perhaps, people so often move a chair a few inches this way and that before sitting in it, with the chair ending up about where it was in the first place. The moves are functional, however. They are a declaration of autonomy, to oneself, and rather satisfying.
Page 61, on distrust and "undesirables":
Many corporation executives who make the key decisions about the city have surprisingly little acquaintance with the life of its streets and open spaces. ... To them, the unknown city is a place of danger. If their building has a plaza, it is likely to be a defensive one that they will rarely use themselves. Few others will either. Places designed with distrust get what they were looking for and it is in them, ironically, that you will most likely find a wino.
Page 64, on guards and plaza mayors:
...it is characteristic of well-used places to have a "mayor". He may be a building guard, a newsstand operator, or a food vendor. Watch him, and you'll notice people checking in during the day. ... One of the best mayors I've seen is Joe Hardy of the Exxon Building. He is an actor, as well as the building guard, and was originally hired by Rockefeller Center Inc. to play Santa Claus, whom he resembles. Ordinarily, guards are not supposed to initiate conversations, but Joe Hardy is gregarious and curious and has a nice sense of situations. ... Joe is quite tolerant of winos and odd people, as long as they don't bother anybody. He is very quick to spot real trouble, however.
Page 85, on megastructures:
The ultimate development in the flight from the street is the urban fortress. In the form of megastructures more and more of these things are being put up - huge, multipurpose complexes combining offices, hotels, and shops - such as Detroit's Renaissance Center, Atlanta's Omni International. Their distinguishing characteristic is self-containment. While they are supposed to be the salvation of downtown, they are often some distance from the center of downtown, and in any event tend to be quite independent of their surroundings, which are most usually parking lots. The megastructures are wholly internalized environments, with their own life-support systems. Their enclosing walls are blank, windowless, and to the street they turn an almost solid face of concrete or brick.
Page 89, on the inevitable decline of megastructures:
And it is going to date very badly. Forms of transportation and their attendant cultures have historically produced their most elaborate manifestations just after they have entered the period of their obsolescence. So it may be with megastructures and the freeway era that bred them. They are the last convulsive embodiment of a time passing, and they are a wretched model for the future of the city.
Appendix A is a guide to using film in research.
Page 103, on research fatigue:
But, thanks to the long term time span of our study, we got our second wind and finally learned a few simple but important lessons. The crux is evaluation. Taking the film is easy. So is showing it. It's even fun. But when you start figuring out, frame by frame, what the film has to tell, and what it means, you will find the process can be enormously time consuming, and before long, tedious. That's where it all breaks down. Unless you master this phase, you will not stay the course. Happily, there are ways to shortcut the tedium, greatly speed up evaluation, and in the process make it more accurate.
Page 109, on being careful:
The real danger comes in photographing illicit activities, especially when you do it without realizing it. Our narrowest call was when we set up a perch on the fourth floor of a building in the middle of a block on 101st Street. The object was to observe the social life on the stoops and fire escapes. Before long, Cadillacs with out-of-state license plates began stopping in front of the building opposite, and there was considerable movement in and out of the basement door. A wholesale heroin operation was under way. ... At length it was discerned that a look-out with binoculars was alerting people to the impending arrival of police cars. The, one day, we saw on the film that the binoculars were trained directly on our camera. We withdrew.
Aug 1, 2007 12:24am
blog all dog-eared pages: sketching user experiences

Sketching User Experiences is Bill Buxton's new book arguing that the process of sketching is distinct from prototyping, and an integral part of design. Buxton opens with the canonical example of great design, Apple's iPod, to show that its "overnight" success actually came after 3+ years of development and updates, and moves on to talk about the lack of design in typical software organizations. These two topics are slightly out-of-tune with the remainder of the book, but I believe they were included to bridge the main thesis to Buxton's role as a Microsoft researcher. In particular, I like the argument for introducing an explicit design phase to the world of software development in accordance with Fred Brooks' opinion that mistakes caught early are mistakes fixed cheaply.
About 1/3rd through the book (see page 111, below), Buxton cuts to the chase with an 11-point definition of sketching as distinct from prototyping. Most importantly to Buxton, sketches are fast, cheap, and divergent. They develop quickly with only minimal detail to make a point, and are intended to communicate the essential ideas of a maximally-wide variety of design possibilities.
He also calls out the example of IDEO's Tech Box, a curated company library of technological toys and materials enabling rapid exploration and research in product design. This was the book's most explicit tie to Mike Kuniavsky's Sketching In Hardware conference series, demonstrating how the characteristics of a good sketch transcend pencil and paper.
Page 36, on wooden maps:

These are 3D wooden maps carved by the Ammassalik of east Greenland. The larger one shows the coastline, including fjords, mountains, and places where one can portage and land a kayak. The thinner lower maps represents a sequence of offshore islands. Such maps can be used inside mittens, thereby keeping the hands warm; they float if they fall in the water; they will withstand a 10 metre drop test; and there is no battery to go dead at a crucial moment.
Page 69, on the difficulty of making new things:
It suddenly occurred to me that our company was not alone in this situation. Rather, as far as I could make out, virtually ever other software company was pretty much in the same boat. After establishing their initial product, they were as bad as it as we were. When new products did come from in-house development, they were generally the result of some bandit "skunk works" rather than some formal sanctioned process (not a comforting thought if you are a shareholder or an employee). Across the board, the norm was that most new products came into being through mergers or acquisitions.
Page 73, on why:
My belief is that one of the most significant reasons for the failure of organizations to develop new software products in-house is the absence of anything that a design professional would recognize as an explicit design process. Based on my experience, here is how things work today. Someone decides that the company needs a new product that will do "X". An engineering team is then assigned to start building it. ... The only good thing about this approach is that one will never be accused of not conforming to the original design. The bad news is that this is because there is no initial design worthy of the term.
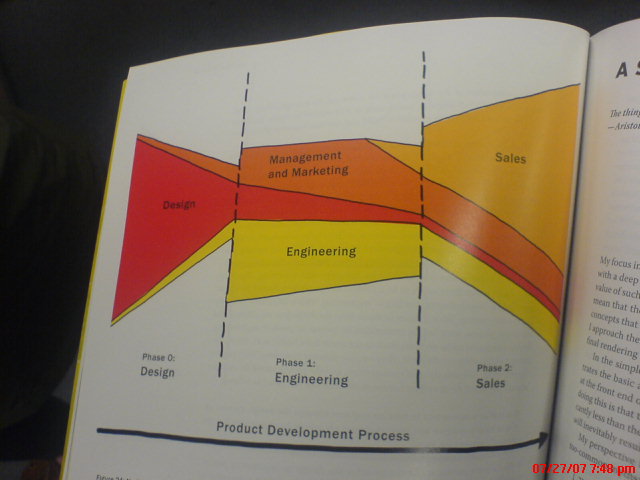
Page 76, on a suggested product development process:
Page 90, on the Trek Y-Bike:
The engineering prototype shown in Figure 28 works. If you look at the photo carefully, you will see that if you added pedals, sprockets, wheels, a chain, brakes, and handle-bars to this prototype it would be perfectly functional. You could ride it. ...it is almost certain that it would be a commercial flop. Why? Anyone can see that the bike is not complete. Not because of the missing parts, but because the design is not complete. What is obvious here with mountain bikes is not obvious with software. My impression is that what we see in Figure 28 relfects the state in which software products ship. They kind of work, but are as far from complete as this version of the bike is.
Page 108-109, some example sketches of bicycles showing speed and disposability:

Page 111, on a definition of sketching:
Quick: A sketch is quick to make, or at least gives that impression.
Timely: A sketch can be provided when needed.
Inexpensive: A sketch is cheap. Cost must not inhibit the ability to explore a concept, especially early in the design process.
Disposable: If you can't afford to throw it away when done, it is probably not a sketch. The investment with a sketch is in the concept, not the execution. By the way, this does not mean that they have no value, or that you always dispose of them. Rather, their value depends largely on their disposability.
Plentiful: Sketches tend not to exist in isolation. Their meaning or relevance is generally in the context of a collection or series, not an isolated rendering.
Clear vocabulary: The style in which a sketch is rendered follows certain conventions that distinguish it from other types of renderings. The style, or form, signals that it is a sketch. The way that lines extend through endpoints is an example of such a convention, or style.
Distinct gesture: There is fluidity to sketches that gives them a sense of openness and freedom. They are not tight and precise, in the sense that an engineering drawing would be, for example.
Minimal detail: Include only what is required to render the intended purpose or concept. Lawson (1997, p.242) puts it this way: "... it is usually helpful if the drawing does not show or suggest answers to questions which are not being asked at the time." Superfluous detail is almost always distracting, at best, no matter how attractive or well rendered. Going beyond "good enough" is a negative, not a positive.
Appropriate degree of refinement: By its resolution or style, a sketch should not suggest a level of refinement beyond that of the project being depicted. As Lawson expresses it, "... it seems helpful if the drawing suggests only a level of precision which corresponds to the level of certainty in the designer's mind at the time."
Suggest and explore rather than confirm: More on this later, but sketches don't "tell," they "suggest." Their value lies not in the artifact of the sketch itself, but in its ability to provide a catalyst to the desired and appropriate behaviors, conversations, and interactions.
Ambiguity: Sketches are intentionally ambiguous, and much of their value derives from their being able to be interpreted in different ways, and new relationships seen within them, even by the person who drew them.
Page 169, on the IDEO Tech Box:
It consists of hundreds of gadgets. Most are laid out on open shelf-like drawers. Some are toys, and are just there because they are clever, fun, or embody some other characteristic that may inspire, amuse, or inform (or perhaps all three). Others might be samples of materials that could be useful or relevant to future designs. ... Since the Tech Box is a kind of mini library or musem, it has someone from the studio who functions as its "curator" or "librarian." And like conventional libraries, all of the objects in the collection are tagged and catalogued so that supplementary information can be found on the studio's internal website. As an indication of how much store the company puts in having its employees have a shared set of references, there is a Tech Box in every one of their studios worldwide. Furthermore, even though anyone can add things to the collection, if you do, you must get one for the Tech Box in every on of the studios. These are circulated to the other studios by the local curator, who also makes sure that the appropriate entry is made into the associated web database.
Page 215, on the unevenly-distributed future:
Here we see the same thing. The period from concept to product is about 20 years in the industry in general, and in user interface technologies, specifically. So much for fast-changing technology! ... If history is any indication, we should assume that any technology that is going to have a significant impact over the next 10 years is already 10 years old!
Pages 350-351, on video sketches of matter duplication:

Page 413, on iconoclasm:
If you are going to break something, including a tradition, the more you understand it, the better job you can do. The same is true in classical art and design education. There are classes such as printmaking, life drawing, and water colour, whose purpose is to lay a solid foundation in technique. This underlies the complementary set of classes that focus on the content of the work - the art rather than the technique.
Page 418, in closing:
Like the word "mathematics," I think the word "future" should be pluralized, as in "futures." As long as it is singular, there is a bias toward thinking that there is only one future. That takes the emphasis, and attendant responsibilities, away from the reality that there are many possible futures, and that it is our own decisions that will determine which one we end up with.
Jul 30, 2007 6:05am
ffffound!
A lot of the links in my snippets feed are visual, but I only post a small portion of the images I encounter. Even then, context is a bitch. All of it gets fed into my Del.icio.us account, which is Flickr-aware but not otherwise picture-friendly. So, I was really happy to find FFFFOUND! last week, thanks to Lydia for the invite.
FFFFOUND! is a website for collecting and sharing images from the web, like Flickr for other people's pictures:
FFFFOUND! is a web service that not only allows the users to post and share their favorite images found on the web, but also dynamically recommends each user's tastes and interests for an inspirational image-bookmarking experience!!
I've been using it for the past week or so, and have really been enjoying the experience. It fills a niche that my other micro-bloggy services, Twitter, Pownce, and Reblog, can't. It also has some interesting borderline social features thrown in to boot.

First, the good:
The site provides a bookmarklet for importing images. The expectation is that you casually throw interesting images over to your account as you move about the web. Activating the bookmarklet adds a heavy yellow border to all page images, so that clicking on them imports them to FFFFOUND!. The source URL is sent along as well, to maintain the connection back to the original location.
It's possible to add other people's images on FFFFOUND! as well, by clicking the "I (heart) This!" button below each site image.
Recommendations branch from each image, via a collection of related thumbnails. Browsing the site is a many-tabbed experience, and I routinely follow a thread of interesting pictures every time I visit. There's a healthy population of users here with excellent taste, most of them Japanese. Images range from Processing screen grabs, to fashion photography, to architecture, to excerpts from graphic design portfolio websites. There's a heavy emphasis on inspiration among the pictures I've browsed. There are also personal recommendations behind the "New For You!" link in the navigation. Both seem to work just like your basic Amazon "people who liked this also liked..." feature.
The site has no tags, which makes me happy. All connections and content are purely visual.
The site also has a decent respect for animated GIFs, even in thumbnail and preview form.

There are a few bits that need work.
The only way to pull new images into the site is via the bookmarklet. I've found this limiting in two cases: many excellent images live on the web in thumbnail form, with links to full-size versions invisible to FFFFOUND!. Also, I spend a lot of time on an old computer with a slow-javascript-performance browser, and I'm aggressive with turning off JS and Ajax on many sites. The bookmarklet doesn't work on Flickr and certain other sites unless I make a special point of temporarily enabling javascript. This inhibits the flow.
The site's "followers" feature informs me that I have 8 followers, but it doesn't say who they are. I assume these are people who like the same images as me and find them after I do, but I can't see their identities to understand what it is they find interesting. It also doesn't tell me whose follower I am, so I can see whose tastes I tend to share. This part may actually be a feature, keeping a focus on the pictures instead of the users.
There's no way to deny recommendations. You can either love an image, or mark it as inappropriate, but you can't politely decline. This decreases the value of the recommendations feature, making it necessary to wait for uninteresting stuff to scroll off the bottom.
The site is in private beta, and each new user gets a single invitation to pass on. Mine's already accounted for, but it sure would be nice to see a more ambitious invite policy.
They offer a screensaver built with ScreenTime, but it totally crashes my shit and generally doesn't work.

Overall, though, FFFFOUND! is a joy to use. I've been introduced to a steady stream of beautiful work, and the "followers" count is a tiny nudge of positive social feedback. I love seeing the images that inspire me framed on a gallery wall like this. The domain is just a few months old, and the site seems to be in a sweet spot of growth, with quality users posting beautiful pictures, and not a lot of noise. It's interesting joining a service where I don't know anyone (yet).
The site is cagey about its source, but the WHOIS lookup says it's a project of Yugo Nakamura, designer of the freakishly awesome Uniqlock and this ball dropping thing that's become something of a joke around the office for its frequent appearance in conversation.









Jul 20, 2007 7:06am
slate's page navigation
These made me very happy:
They're the page navigation links at the bottom of Slate's multi-page stories, and each image shows how the set of links looks when the mouse if hovering on the 1, the 2, and the NEXT, respectively. I'm very much enjoying the fact that the yellow highlight on the rightmost link matches the vertical height of the other two, making the whole block a tightly coupled unit.
Jul 14, 2007 8:10pm
modest map tutorial
Heads up, new Modest Maps tutorial featuring Zoomify and AC Transit.
Jul 8, 2007 7:13pm
federal building
The new San Francisco federal building opens tomorrow, and there are a few details I like very much.
There's a sky garden on the 11th floor that overlooks SOMA, and is open to the public behind a security checkpoint:

The exterior has a nice, jagged look to it, with lots of energy-saving skin features:

The elevators only stop on every 3rd floor, "to improve worker health by nudging them to use stairways - and also create crossroads where employees run onto each other, since each three-story segment includes a lobby with art and a viewing platform."
Jul 8, 2007 6:52pm
transit data
I've been collecting Bay Area public transit schedules from 511.org. I have loose plans for them, but it's going to be awhile before I get around to doing anything.
Meanwhile, here's the data: transit.db.gz, 6.4MB compressed SQLite 3 database, ~84MB uncompressed. Contains all stops for SF MUNI, AC Transit, AC Transit transbay service, and BART, in the following format:
CREATE TABLE stops (
provider TEXT(16),
route_name TEXT(8),
schedule_name TEXT(32),
stop_location TEXT(32),
stop_time TEXT(16),
schedule_url TEXT(128),
PRIMARY KEY (provider, route_name,
schedule_name, stop_location,
stop_time)
);
Jul 6, 2007 7:07am
thither design camp!
A few days ago, I posted a question about "design camps", specifically, why don't they exist? The model I had in mind was the technology geek unconference scene, most visibly implemented as Bar Camp, and most famously as O'Reilly's Foo Camp. There's also a host of tech conferences with BOF (birds of a feather) sessions and other self-organizing nerdery going on.
My loaded question got me a few mails that mentioned events such as last year's DCamp, which even has "design" in the name (sort of):
Unlike traditional conferences, there is no program created by conference organizers. What happens at DCamp depends on you. Come share your work and ideas. Tell us about some interesting UX method, explain how design fits into agile development and open source, share your design dilemma, or tell us about your new and interesting design.
In the end, the event was heavily HCI-focused, as might be expected from a BayCHI-sponsored event.
Mark Rickerby pointed out that New Zealand is home to a few emerging "time limited design contests", focused on competition rather than conferencing. 48Hours is about filmmaking, while Full Code Press is a "geek olympics": Web teams take each other on to build a complete website for a non-profit organisation in 24 hours. No excuses, no extensions, no budget overruns. These events remind me strongly of the late-90's sport of photoshop tennis, and are quite close to the problem-solving aspects of design.
One big difference that I can see already is a focus on two different ends of the process: technology events are about inputs, design events are about outputs. In general, it's possible to abstract a creative solution or sweet trick out a technological problem, and have that be the focus of a talk or session. For example, at the most recent FOO Camp I participated in a session on API authentication, specifically the derivation of a new standard process for authenticating to 3rd parties for web applications. There were people from Flickr, Google, Verisign, Dopplr, and Twitter there, and it was possible to have a meaningful conversation about the problem domain without everybody having to expose their secret sauce. Inputs. As Kevin Cheng put it, it's "fun to talk with a mixed group of both engineers and designers to get energized about building stuff."
In contrast, the competitive design events above are output-driven. Participants are expected to use the event to make a thing, with the conversational parts expected at the end. Make something, then talk about it. Mike Kuniavsky's event Sketching in Hardware (see also '07) had a lot of this element, especially the afternoon wrap-up design-off that had teams converting found electronic junk into working prototypes (my team made a record/playback telegraph machine out of a lamp and a stepper motor, and I still managed to get a bit of Flash involved). Timo Arnall imagines more of these events, with "a room full of markers, spray cans, nice paper and lego... access to a laser cutter, RP machine, etc..."
The prime example of a successful design event in my mind is Andrew Otwell's Design Engaged, held once in 2004 and again in 2005. We attended the second one, and it was really something special: fairly ad-hoc, small group (~30 people), and an incredible amount of energetic participation. I think it's important that the attendees for these two events were mostly hand-picked, with DIY social events far beyond the usual eat+drink planned for attendees; you'd be hard-pressed to beat a walking tour of Berlin/Charlottenburg hosted by Erik Spiekermann. The best way I can think of to sum up the talks at DE is that every single one was delivered by a designer of some variety riffing on what they thought was personally interesting to them. Adam talked about peak oil, Jack showed comic books and alloys with low eutectic melting points, Liz described her research work in hospitals, and Malcolm threw out some ideas on the differences between access and mobility, to name a few of my favorite sessions. It was a difficult event to sum up, and takes on a special significance in retrospect because it was such a fragile, unlikely co-occurence. It was also probably one of the few TAZ's I've participated in:
The Temporary Autonomous Zone (TAZ) describes the socio-political tactic of creating temporary spaces that elude formal structures of control. ... A new territory of the moment is created that is on the boundary line of established regions. Any attempt at permanence, that goes beyond the moment, deteriorates to a structured system that inevitably stifles individual creativity. It is this chance at creativity that is real empowerment.
Jay Feinberg gets at this as well, in his description of geek camp events as:
...enthusiast clubs, e.g., computer clubs of the 1970s or BBS clubs of the 1980s. The clubby aspect is, IMO, expressed through an implicit or explicit hierarchy among "members." People are invited and anyone can participate, but, ultimately, there are core members and even a hierarchy of leaders who define the culture of who is really "in" and who is really "out." And, the activities at camp are, on one level, very much about being part of the club - doing things that prove one's value as a member or move one up the hierarchy of important people in the club.
I liked this description enough to go scurrying for an article that Nat pointed out a long time ago, Jo Freeman's Tyranny of Structurelessness. Freeman is a feminist scholar most active in the 1960s and 70s, and her essay describes the power dynamics of supposedly-unstructured movements:
Contrary to what we would like to believe, there is no such thing as a "structureless" group. Any group of people of whatever nature that comes together for any length of time for any purpose will inevitably structure itself in some fashion. The structure may be flexible; it may vary over time; it may evenly or unevenly distribute tasks, power and resources over the members of the group. But it will be formed regardless of the abilities, personalities, or intentions of the people involved. The very fact that we are individuals, with different talents, predispositions, and backgrounds, makes this inevitable. Only if we refused to relate or interact on any basis whatsoever could we approximate structurelessness - and that is not the nature of a human group.
...
Once the movement no longer clings tenaciously to the ideology of "structurelessness," it is free to develop those forms of organization best suited to its healthy functioning. This does not mean that we should go to the other extreme and blindly imitate the traditional forms of organization. But neither should we blindly reject them all.
Jay points out that the designers often come together out of existing, established structures (there's a rough taxonomy of job titles and professional organizations such as AIGA, if I understand what he's getting at), and don't need to do quite so much jockeying for "geek cred".
Oddly, I've begun to form a mental model of how the conference/camp ecology operates by analogy to a previous scene I was a member of, San Francisco's mid/late 90s rave underground (just think "dj is to party as speaker is to conference") There was a constant push-pull dynamic between the promoters of permitted (in the legal sense), for-profit parties, and the collectives responsible for a dizzying array of remote, hidden, and otherwise illegal events. Questions of credibility and legitimacy were a core focus, and it was always important to stay just on the bleeding edge of acceptability and risk. The trigger for this association was a talk on unconference planning given by Jo Walsh and Rufus Pollock at E-Tech 2006, effectively an hour's worth of advice on scouting, securing, and using out-of-the-way venues for ad-hoc technology events. Same damn thing as a party, with no ear-bleeding bass.
What made it all work was the same fragility that Design Engaged featured: "any attempt at permanence, that goes beyond the moment, deteriorates to a structured system that inevitably stifles individual creativity." Look to Burning Man for a long-running example of permanence stifling spontaneity. How does an event go from inspiring, utter fucking chaos to the flaccid, gormless prose of today's annual desert art social? I'm sure that being forced to worry about BLM permits and power-tripping DPW wonks cuts the tolerance level for rave camp and the drive-by shooting range.
Many of the designers I've met over the years share joy in short-lived coincidence and unlikely collisions, and I think this is a reason that the "camp" meme hasn't found a home among designers as it has among techies. Foo camp, Bar camp, Etech, and other technology events are fundamentally about repetition: geeks need a refuge to congregate in, and this refuge can be constructed and duplicated in a fairly reliable manner. Tech events focus on inputs to the creative process, tools and techniques that want to be tried and implemented. Design events focus on outputs, results of a creative process whose constituent parts are fly together at the last moment in unpredictable ways. Boris says design is "dictatorial"; how can you have a session about the last-minute flash of inspiration, except to share war stories?
(Thank you Jay Feinberg, Timo Arnall, Peter Merholz, Boris Anthony, Hillary Hartley, Mark Rickerby, Tom Carden, and Andrew Otwell for your replies)
Jul 4, 2007 5:34pm
new typepad design?
This is interesting:
Is it a new standard Typepad template? If so, I'm all for it.
Jul 3, 2007 6:38am
whither design camp?
The technology crowd has a range of social events to choose from where actual work often gets done: etech, xtech, foo camp, bar camp, etc. For the most part, designers don't do this. Why not? I have my ideas, but I'm curious to hear yours. Mail me if you have something to say, I'll post a followup later.
Jun 29, 2007 2:49am
foo, pownce
Right, so I feel totally swamped right now, mostly by e-mails and a general feeling of not enough time in the day.
Two big interesting things have happened in the past week: Tom and I went to O'Reilly's FOO Camp in Sebastopol, an invitation-only hootenany attended by a variety of nerds. Among other talks and sessions, Kevin Slavin gave an understated, epic rundown of Area/code's relationship to that one meme about how kids don't roam nearly as far from home as they used. Kevin neatly tied up a bunch of threads about location, technology, television, and media, and my life is the richer for it.
The other thing is that Pownce launched. Our own Shawn Allen built the Adobe AIR desktop client for this messaging application, and large chunks of the project were conceived and perfected in our office. I've been close to the work and participated in a number of API design discussions. There's a bunch of noise about how it's like-Twitter-this, and isn't-it-just-email-that, but it's a stake in the ground, fun to use, and has a bright future.
Jun 27, 2007 6:23am
six web comics
Scott McCloud promised that the web was going to make distribution of lone-creator comics work, and he was right. The way to keep up with these things is via RSS feeds, and the artists generally seem to understand I've never in my life paid attention to comics, but now there are a few that I check up on regularly.

Wondermark is David Malki's bi-weekly (Tuesdays and Fridays) strip with artwork yanked from old-timey expired copyright illustrations, funny captions appended.

Perry Bible Fellowship is sometimes a bit raw, but Nicholas Gurewitch also uses it to experiment with a variety of drawing styles.

Cat And Girl is a long-running series featuring snarky literary references. I own an apparently-no-longer-in-print CnG Rube Goldberg t-shirt.

Penny Arcade is mostly about video games. I don't really play any games, but the strip is consistently awesome. I wish they'd fix their stupid RSS feed.

Wonderella is a comic book hero spoof, a little bit Cathy but generally funny.

I don't fully understand the cast of characters from Achewood, perhaps this is okay.

Also, the New Yorker Cartoon Anti-Caption Contest doesn't fully count as a web comic, but it's close. Each week the real drawings from the New Yorker cartoon caption contest are posted, and readers are encouraged to submit aggressively unfunny captions.
Jun 15, 2007 2:08am
notes on api authentication
We've been thinking a lot about authentication recently, both as consumers and designers of web API's. Although certain best practices in this area are being solidified, I still think it's a wide-open field for experimentation. This post is a run-down of various patterns we've encountered for authenticating applications and users, and has been greatly helped along by conversations with Shawn, Steve, Matt, and others.
Keys
The simplest application authentication method is the developer key. Flickr has been using these since day one, and they mostly help in monitoring usage. Generally, the idea is that a site issues a unique key to each application consuming the interface, and then requires that this key be passed along with every request. Keys are not expected to remain secret or be subject to rigorous control, but they do help Flickr keep tabs on how applications use the API, and provide a way to find someone to blame when requests with a given key cause problems. We used to routinely get mails from Stewart about Mappr's (ab)use of expensive search parameters.
Flickr's API keys are explicitly connected to Flickr accounts, and are issued via an application form that asks for a description of your intended use and a promise to abide by the terms of use. There's also a monitoring page that displays your own API usage:
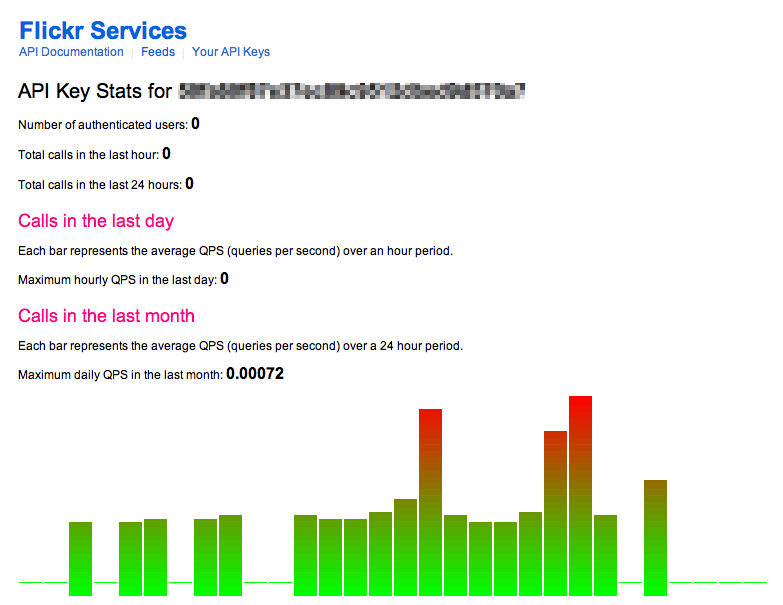
When we designed the Digg API, it was decided that key enforcement was not a high-enough priority to warrant the overhead of administration, so we went with a simple form of consensual disclosure. Digg application keys must be provided, must be in the form of a valid absolute URI, and should point to a page that describes the application. The URI isn't checked for normal usage, so it's possible to experiment and play with the API with minimal hassle.
Tracking keys is enough of a hassle that companies like Mashery have popped to provide this as a service.
Usernames, Passwords
Authenticating individual users is more sensitive, especially when an API provides read/write methods for posting new information to a user's account. The easiest way to authenticate this is to require that a user's account name and password be attached to requests.
The original Del.icio.us API required HTTP basic authentication for all methods, including the ones that returned information available on public, anonymous web pages in the application. Basic auth is well-understood and reasonable well-supported, so this made it quite easy to write tools that used the API. The major drawback of this method is that account passwords can be sniffed on every request, making them wildly insecure. At some point last year, Del.icio.us began requiring that all API requests be done over HTTPS. This solves the problem of password exposure, but introduces a new problem: HTTPS is a considerable resource hog, and is expensive to serve. Cal estimates that the cryptographic overhead of HTTPS can cut a web server's performance by 90%. It is useful for HTTPS to keep the contents of an interaction secret where the data is sensitive, as with banks and medical records, but it's total overkill in the case of a typical web API.
A more subtle problem with asking for usernames and passwords is the inherent phishing risk. An API that can be operated with a user's permanent password is a magnet for potential abuse, because something you know might also be something someone else knows. Flickr's early approach to this problem was to ask for the user's e-mail address in the request, not their Flickr username. A sniffed API password would be useless for logging into the main website, and knowing a username and password wouldn't get you into the read/write API.
Digests
One way to deal with the risk of password exposure without touching HTTPS is digest authentication. This is a pattern that uses one-way hashing functions such as MD5 or SHA to hide a password in transit, while still allowing it to be verified by the API server. Generally, an API client will send the server a hashed combination of username, password, and possibly other details. The server can't deconstruct the hash, but it can make one of its own and ensure that the two are identical.
At one point, the Atom Publishing Protocol defined WSSE as its preferred form of authentication. A visitor from the miserable world of SOAP, WSSE defines a simple way to hash up the user's password, the creation date of the message, and a nonce ("number used once") for a bit of randomness. The hashed tokens are difficult to pry apart, and the method helps prevent replay attacks by enforcing recency (via the creation date) and randomness (the client makes up a new nonce on every turn). WSSE has come under a great deal of criticism due to its requirement that the password be part of the hash. No sane application developer stores passwords in cleartext, but WSSE requires that this be the case in order for the server to re-create the hashed token for comparison.
Amazon's web services define their own authentication protocol that borrows a number of advantages from WSSE. First, the value that the client hashes includes HTTP headers, the request body, the URL, and the date, among other details. Second, the instead of asking for an account password, Amazon assigns each API user a secret key for use in such hashes. The secret cannot be used to retrieve API user account details, and it can be invalidated and re-generated if the user thinks it's been leaked. Third, Amazon offers several ways to attach the authorization signature to requests, from packing it into special-purpose HTTP headers to tacking it onto the request CGI parameters. The latter method makes it possible to generate limited-use URL's for private data, allowing an Amazon API user fine-grained control over public access to stored data. Because use of Amazon's API is billed, these features add up to a sane way to ensure that it's difficult to rack up excessive costs on user's account.
Tokens
A useful response to the phishing risk of passwords is a limited-user token, a pattern I'm starting to see used more often in authentication schemes.
Flickr switched to this model some time ago, adding the concept of a secret key to be shared between an application developer and Flickr. The general pattern is that authenticating as a Flickr user to a 3rd party web application involves having that application send you to a page on Flickr.com, which accepts your user credentials and asks whether the requesting 3rd party application should be allowed to read/write data on your behalf. The application and Flickr share a secret key which is checked at this time. If you agree, Flickr will redirect you to the 3rd party application's authentication handling page along with a freshly-minted frob. The 3rd party application can then convert this frob to a token, which can then be used to perform actions on that user's account.
There are a few significant things going on here. First, only Flickr needs to see your username and password, which is great security. Second, the frobs and tokens are tracked by Flickr, so the permissions you've granted to the 3rd party can be revoked at any time. Third, the secret key means that an intercepted frob is not useful to an interloper.
Unfortunately, this also means that Flickr's authentication process is (in my humble opinion) a total fucking hassle (sorry Aaron).
Google's AuthSub is a similar approach that I believe dispenses with some of Flickr's complications. Unlike Flickr, AuthSub does not require a pre-existing arrangement between the 3rd party application and Google, and there is no secret key. Instead, Google displays the authentication handler URL and domain name, and lets users determine whether they trust that application by name. The token sent by Google at this point (what Flickr calls a frob) is valid for a single-use, but can be exchanged for a session token if the user explicitly allowed this to happen. Tokens issued by Google can only be used for a limited subset of their applications, e.g. just gmail or calendars. AuthSub also agreeably allows for experimentation: it's possible to request a valid token without a publicly-viewable web application.
Google's access confirmation page looks like this:
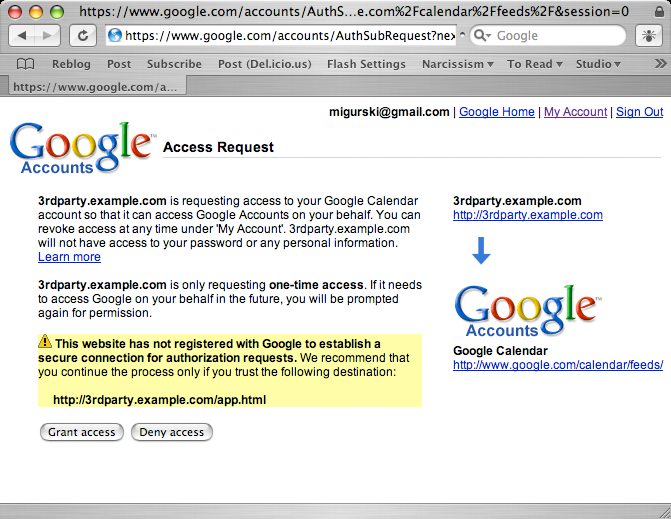
Google rounds out AuthSub by providing a page in each user account that lists the currently-valid tokens and the web applications to which they've been granted. These can be revoked by the user on an individual basis, and offer a granular level of control over how their data is exposed and manipulated.
One potential security weakness in AuthSub is that the token may be intercepted and used. I'm not clear on how Google's web services use these tokens, though - it may be necessary to pair the token with some other piece of information that's harder to intercept, such as the user's Google account name.
An approach to keeping tokens secret that I've not yet seen in practice, but one that looks promising, is Diffie-Hellman key exchange. D-H uses a property of modular arithmetic that allows two parties to agree upon a shared secret over an insecure channel. The algorithm is roughly analogous to two people exchanging a box with two padlocks on it, keeping the box locked while in transit but not requiring either person to give up the key to their own lock. With a few extra round trips, the contents of the box can be exchanged securely.
This means that it should be possible to replace the open token transmission above with a secure exchange, resulting in a temporary secret shared between the API client and server, highly-resistant to sniffing.
Summary
I'm seeing a clear progression in API authentication from a two-party relationship between the application developer and the application user, to a three-party relationship between the application developer, the user, and the 3rd party needing temporary access to the application on the user's behalf, no doubt driven by the way popular applications are starting to treat themselves as platforms to be extended and built upon. One major recent entry that I haven't yet touched at all is Facebook.
Links mentioned above:
- Flickr API
- Flickr API developer key application form
- Flickr API terms of use
- Digg API
- Digg API application key requirements
- Mashery
- Del.icio.us API
- HTTP basic authentication
- Cal Henderson's book Building Scalable Websites
- Cornell CS 153 lecture notes
- Atom Publishing Protocol
- Amazon Web Services REST Authentication
- Google AuthSub
- Diffie-Hellman key exchange
Jun 13, 2007 5:21pm
blog all dog-eared pages: soul of a new machine

Soul of a New Machine is Tracy Kidder's vicarious account of the design and creation of Data General's Eagle minicomputer in the early 1980's. The project was a classic skunkworks operation, developed in competition against a more prominent, better-funded 32-bit project named Fountainhead ("North Carolina", below). I first heard of this book in Bruno Latour's Science in Action, an account of the codependence between science and technology, "the role of scientific literature, the activities of laboratories, the institutional context of science in the modern world, and the means by which inventions and discoveries become accepted".
"West", below, refers to Eagle project head Tom West, an eccentric manager who brought out the best in his team by creating a barrier between them and the rest of the company, while driving them hard from above.
Update: Jason Kottke says that Tom West is Metafilter moderator Jessamyn West's dad, and has a website. The way Soul ends, it felt a bit like Shane. Closure!
Page 57, on hiring:
North Carolina's leaders had assembled a large crew mainly by luring experienced engineers away from Westborough and other companies. But around this time a videotape was circulating in the basement, and it suggested another approach. In the movies, an engineer named Seymour Cray described how his little company, located in Chippewa Falls, Wisconsin, had come to build what are generally acknowledged to be the fastest computers in the world, the quintessential number-crunchers. Cray was a legend in computers, and in the movie Cray said that he liked to hire inexperienced engineers right out of school, because they do not usually know what's supposed to be impossible. Moreover, using novices might be another way to disguise his team's real intentions. Who could believe that a bunch of completely inexperienced engineers could produce a major CPU to rival North Carolina's?
Pages 119-120, on doing things well:
On the magic marker board in his office, West wrote the following: Not Everything Worth Doing Is Worth Doing Well. Asked for a translation, he smiled and said, "If you can do a quick-and-dirty job and it works, do it." Worry, in other words, about how Eagle will look to a prospective buyer; make it an inexpensive but powerful machine and don't worry about what it'll look like to the technology bigots when they peek inside. ... To some the design reviews seemed harsh and arbitrary and often technically shortsighted. Later on, though, one Hardy Boy would concede that the managers had probably known something he hadn't yet learned: that there's no such thing as a perfect design. Most experienced computer engineers I talked to agreed that absorbing this simple lesson constitutes the first step in learning how to get machines out the door.
Page 177, on dumb jobs:
It did not work out he planned. "I thought I'd get a really dumb job. I found out dumb jobs don't work. You come home too tired to do anything," he said. He remembered a seemingly endless succession of meetings out of which only the dullest, most cautious decisions could emerge.
Pages 208-209, on naming:
The solution takes the form of a circuit called a NAND gate, which reproduces the "not and" function of Boolean algebra. The part costs eight cents, wholesale. The NAND gate produces a signal. Writing up the ECO, Holberger christens the signal "NOT YET." He's very pleased with the name. Schematics he's seen from other companies use formal, technical names for signals. The Eclipse Group, by contrast, looks for something simple that fits and if they can't come up with something appropriate they're apt to use their own names. ... It's the general approach that West has in mind when he says, "No muss, no fuss." It's also a way - a small one, to be sure - of leaving something of yourself inside your creations.
Pages 227-228, on skunkworks:
Alsing came away convinced, however, that West had an important strategy. "We're small potatoes now, but when Eagle is real, he'll have clout and can make nonnegotiable demands for salary, space, equipment and especially future products." Rasala came away with the same idea: "Maybe it's ego. But West has some interesting notions, ahhhhhnd, I kinda believe him. His whole notion is that he doesn't want to fight for petty wins when there's a bigger game in town."
Page 232, on staving off post-delivery depression:
West stubbed out his cigarette, lit another, and went back to looking at whatever it was he saw in the ceiling. "The postpartum depression on this project is going to be phenomenal. These guys don't realize how dependent they are on that thing to create their identities. That's why we gotta get the new things in place."
Page 242, on invisible computers:
Wallach and I retreated from the fair, to a cafe some distance from the Coliseum. Sitting there, observing the more familiar chaos of a New York City street, I was struck by how unnoticeable the computer revolution was. ... Computers were everywhere, of course - in the cafe's beeping cash registers and the microwave oven and the jukebox, in the traffic lights, under the hoods of the honking cars snarled out there on the street, in the airplanes overhead - but the visible differences somehow seemed insignificant.
Page 280-281, on pinball:
Their group, as they saw it, was the most dogged, hardworking, practical, productive and dangerous in the company, a bastion of the old successful ways, a paradigm of the company as it had been when it was small. The believed in the rule of pinball: if you win, you get to play again; but failure is unthinkable, so you'd better let no one get in your way.
Jun 11, 2007 6:31am
summer jam
Via Ben and Junk Charts, Andrew Kuo's blog emo + beer = busted career:

How awesome is this?
Andrew also gets paid and written up for his visual snarkery, by The New York Times.
Jun 8, 2007 6:14am
london 2012
Answering Jeff's question about sports logos made me realize how much I like the new London 2012 identity. Seeing it made me recoil at first, but a few things have changed my mind about the identity.
The Saved By The Rave Olympic Remix totally nails the retro aesthetic the brand is tickling. The official brand video even makes some of the same covert references with its sinister electronic soundtrack: new rave is a "thing" and by 2012, we should be just about ready for a 20 year bounce of late 80's/early 90's pop cultural nostalgia. Speak Up calls out two other obvious references: Money For Nothing and MTV.
There's also some incredible stuff going on at the end of that brand video (fast-forward to ~1:50):

The logo defines a basic visual grammar that will survive reproduction in print, video, web, etc., and the use I'm seeing so far crackles with energy. In contrast to Jeff's two other contestants for worst sporting event logo (2006 World Cup and Tour de France), 2012 is the only one that has any sort of life in it. World Cup is flaccid and committee-drenched, while Tour is conservative.
London 2012 is absurd and wants to be shown around, so ridiculous that it spawns a wave of derision for maximum exposure.


May 29, 2007 11:21pm
trulia hindsight
Trulia Hindsight launched today. I can't claim credit for the gorgeous time interface, but I can say that this is the second reasonably high-profile project that uses Modest Maps as its tile display engine.

May 28, 2007 1:49am
oakland crime maps VII: public indexes redux
Earlier this month, I described a way of publishing a database in a RESTful, static form. Since then I've been tweaking the data into a more presentable state, which I'll describe in this post.
Also I promise that next time, there'll actually be something to look at beyond of me noodling with computer pseudo-science.
When I first opened up the Oakland crime index, I published data in two forms: data about crime was stored in day/type resources, e.g. May 3rd murders or Jan 1st robberies, while binary-search indexes on the case number, latitude, and longitude were published with pointers to the day/type resources. As I've experimented with code to consume the data and kicked these ideas around with others, a few obvious changes had to be made:
First, the separate b-trees on latitude and longitude had to go. Location is 2-dimensional, and requires an appropriate index to fit. I had initially expected to use r-trees but found that quadtrees, a special case, made the most sense. These are closest in spirit to the b-tree, and unlike the r-tree each sub-index does not overlap with any other.
Second, space and time are intricately related, so spatiotemporal index was an obvious next step. I chose an oct-tree of latitude, longitude, and time. Again, this is a simple extension of the b-tree, and provides for simple answers like "show all crimes that are within a mile of a given point, for the following dates..."
Third, I was being too literal with the indexes, insisting that traversing the trees should ultimately lead back to a link to a specific day/type listing. Although this is how a real database index might work, in the context of an index served over HTTP, a large number of transactions can be avoided by just dropping the actual data right into the index. To understand what this means, compare the CSS-styled output of the various indexes to the HTML source: the complete data for each crime is stashed in a display: none block right in the appropriate node.
Finally, my initial implementation used the binary tree lingo "left" and "right" to mark the branches in each index. I've replaced this with more obvious "before", "after", "north", "south", "east", and "west" for greater ease of human-readability and consumption.
I'm still hosting the data on Amazon's S3, but a recent billing change is making me re-think the wisdom of doing this:
New Pricing (effective June 1st, 2007): $0.01 per 1,000 PUT or LIST requests, $0.01 per 10,000 GET and all other requests.
Eep.
In one week, S3 is going to go from a sensible storage/hosting platform for data consisting of many tiny resources, to one optimized for data consisting of fewer, chunkier resources; think movies instead of tiles. I can see the logic behind this: S3's processing overhead for serving a million 1KB requests must be substantial compared to serving a thousand 1MB requests. Still, it makes my strategy of publishing these indexes as large collections of tiny files, many of which will never be accessed, start to seem a bit problematic.
The obvious answer is to stash them on the filesystem, which I plan to do. However, there is one feature of S3 that I'm going to miss: when publishing data to their servers, any HTTP header starting with "X-AMZ-Meta-" got to ride along as metadata, allowing me to easily implement a variant of mark and sweep garbage collection when posting updates to the indexes. This made it tremendously easy to simulate atomic updates by keeping the entire index tree around for at least 5 minutes after a replacement tree was put in place, a benefit for slow clients.
When I move the index to a non-S3 location before my Amazon-imposed June 1st deadline, I will no longer have the benefit of per-resource metadata to work with.
For next time: code to consume this, code to show it.
May 27, 2007 5:55pm
data bill of rights
I'm de-cloaking for a moment here to mention John Batelle's excellent Data Bill of Rights, published about a month ago. It popped into relief again for me with the announcement of Google's purchase of FeedBurner, and all the RSS traffic data that rides along.
The rights, enumerated:
- Data Transparency. We can identify and review the data that companies have about us.
- Data Portability. We can take copies of that data out of the company's coffers and offer it to others or just keep copies for ourselves.
- Data Editing. We can request deletions, editing, clarifications of our data for accuracy and privacy.
- Data Anonymity. We can request that our data not be used, cognizant of the fact that that may mean services are unavailable to us.
- Data Use. We have rights to know how our data is being used inside a company.
- Data Value. The right to sell our data to the highest bidder.
- Data Permissions. The right to set permissions as to who might use/benefit from/have access to our data.
I like where this is going, but I believe that it's a bit toothless unless the ownership of that data is clarified. As long as the legal owner of personal data is assumed to be the company in possession (Google, FeedBurner, Facebook, etc.), the enumerated rights will be considered the responsibility of P.R. and marketing. If it were somehow possible to push the bill of rights into the legal department, this idea would gain some serious traction. It would also have the possibly-beneficial side effect of depressing valuations for data collection companies like FeedBurner or DoubleClick, or even Google itself. It might also have a similar effect on the financial world, giving companies such as ChoicePoint a well-deserved kick in the teeth.
May 12, 2007 2:25am
blog all dog-eared pages: organization man

The Organization Man is a classic by William Whyte that was first recommended to me by Abe almost two years ago. It took me until just recently to pop it off my Amazon stack and give it a read. It's a major critical investigation of American society in the 1950's, written from deep inside that era in 1956. Whyte covers work, education, religion, and suburbia in his sharp description of what he believes to be a problematic development: the post-war emergence and celebration of groupthink and conformity in all forms of corporate and organization life.
Half the fun of this book is Whyte's sharp prose. He has a lot of data, a good eye for observation, and a clear opinion he's not interested in holding back.
Sorry that this is kind of a long post, but it's a great read full of worthwhile passages.
Page 19, on the qualitative difference between small business and the corporation:
Out of inertia, the small business is praised as the acorn from which a great oak may grow, the shadow of one man that may lengthen into a large enterprise. Examine businesses with 50 or less employees, however, and it becomes apparent the sentimentality obscures some profound differences. ... The great majority of small business firms cannot be placed on any continuum with the corporation. For one thing, they are rarely engaged in primary industry; for the most part they are the laundries, the insurance agencies, the restaurants, the drugstores, the bottling plants, the lumber yards, the automobile dealers. They are vital, to be sure, but they essentially service an economy; they do not create new money within their area and they are dependent ultimately on the business and agriculture that does.
Page 34, on Hawthorne and economic man:
In the literature of human relation the Hawthorne experiment is customarily regarded as a discovery. In large part it was; more than any other event, it dramatized the inadequacy of the purely economic view of man.
Page 35, on social discipline:
In the Middle Ages people had been disciplined by social codes into working together. The Industrial Revolution, as Mayo described the consequences, had split society into a whole host of conflicting groups. Part of a man belonged to one group, part to another, and he was bewildered; no longer was there one group in which he could sublimate himself. The liberal philosophers, who were quite happy to see an end to feudal belongingness, interpreted this release from the group as freedom. Mayo did not see it this way. To him, the dominant urge of mankind is to belong: "Man's desire is to be continuously associated in work with his fellows," he states, "is a strong, of not the strongest, human characteristic."
Page 78, on education:
How did he get that way? His elders taught him to be that way. In this chapter I am going to take up the content of his education and argue that a large part of the U.S. educational system is preparing people badly for the organization society - precisely because it is trying so very hard to do it. My charge rests on the premise that what the organization man needs most from education is the intellectual armor of the fundamental disciplines. It is indeed an age of group action, of specialization, but this is all the more reason the organization man does not need the emphases of a training "geared for the modern man." The pressures of organization life will teach him that. But they will not teach him what the schools and colleges can - some kind of foundation, some sense of where we came from, so that he can judge where he is, and where he is going and why.
Page 150, on executive aspirations:
We have, in sum, a man who is so completely involved in his work that he cannot distinguish between work and the rest of his life - and happy that he cannot. ... No dreams of Gothic castles or liveried footmen seize his imagination. His house will never be a monument, an end in itself. It is purely functional, a place to salve the wounds and store up energy for what's ahead. And that, he knows full well, is battle.
Pages 157-158, on the loneliness of authority:
Just when a man becomes an executive is impossible to determine, and some men never know just when the moment of self-realization comes. But there seems to be a time in a man's life - sometimes 30, sometimes as late as 45 - when he feels that he has made the irrevocable self-commitment. At this point he is going to feel a loneliness he never felt before. If he had the toughness of mind to get this far he knows very well that there are going to be constant clashes between himself and his environment, and he knows that he must often face these clashes alone. His home life will be shorter and his wife less and less interested in the struggle. In the midst of the crowd at the office he will be isolated - no longer intimate with the people he has passed and not yet accepted by the elders he has joined.
Pages 194-195, on personality testing:
Few test takers can believe the flagrantly silly statement in the preamble to many tests that there are "no right or wrong answers." There wouldn't be much point in the company's giving the test if some answers weren't regarded as better than others. Telling the truth about yourself is difficult in any event. When someone is likely to reward you if you give answers favorable to yourself the problem of whether to tell the truth becomes more than insuperable; it becomes irrelevant.
"Do you daydream frequently?" In many companies a man either so honest or so stupid as to answer "yes" would be well advised to look elsewhere for employment.
Pages 196-198, on strategies for personality tests:
When in doubt about the most beneficial answer to any question, repeat to yourself: I loved my father and my mother, but my father a little bit more. I like things pretty much the way they are. I never worry much about anything. I don't care for books or music much. I love my wife and children. I don't let them get in the way of company work.
Jacques Barzun says in his Teacher in America, "I have kept track for some ten years of the effects of such tests on the upper half of each class. The best men go down one grade, and the next best go up. It is not hard to see why. The second-rate do well in school and in life because of their ability to grasp what is accepted and conventional. ... But first-rate men are rarer and equally indispensable. ... To them, a ready-made question is an obstacle. It paralyzes thought by cutting off all connections but one. ... Their minds have finer adjustments, more imagination, which the test deliberately penalizes as encumbrances."
Pages 208-209, on pure vs. applied research:
The failure to recognize the value of purposelessness is the starting point of industry's problem. To the managers and engineers who set the dominant tone in industry, purposelessness is anathema, and all their impulses incline them to highly planned, systematized development in which the problem is clearly defined. ... In pure research, however, half the trick is finding out that there is a problem - that there is something to explain. The culture dish remained sterile when it shouldn't have. The two chemicals reacted differently this time than before. Something has happened and you don't know why it happened - or if you did, what earthly use would it be? By its very nature, discovery has an accidental quality. Methodical as one can be in following up a question, the all-important question itself is likely to be a sort of chance distraction of the work at hand. At this moment you neither know what practical use the question could lead to nor should you worry the point. There will be time enough later for that; and in retrospect, it will be easy to show how well planned and systematized the discovery was all along.
Page 250, on the organization man in fiction:
But this does not mean that our fiction has become fundamentally any less materialistic. It hasn't, it's just more hypocritical about it. Today's heroes don't lust for big riches, but they are positively greedy for the good life. This yen, furthermore, is customarily interpreted as a renunciation of materialism rather than as the embrace of it that it actually is. ... After making his spurious choice between good and evil, the hero heads for the country, where, presumably, he is now to find the real meaning in life. Just what this meaning will be is hard to see; in the new egalitarianism of the market place, his precipitous flight from the bitch goddess success will enable him to live a lot more comfortably than the ulcerated colleagues left behind, and in more than one sense, it's the latter who are less materialistic. Our hero has left the battlefield where his real fight must be fought; by puttering at a country newspaper and patronizing himself into a native, he evades any conflict, and in the process manages to live reasonably high off the hog. There's no Cadillac, bu the Hillman Minx does pretty well, the chickens are stacked high in the deep freeze, and no doubt there is a hi-fi set in the table which he and his wife have converted. All this may be very sensible, but it's mighty comfortable for a hair shirt.
Page 279, on transience or purpose:
Their allegiance is more to The Organization itself than to any particular one, for it is in the development of their professional techniques, not in ideology, that they find continuity - and this, perhaps, is one more reason why managerial people have not coalesced into a ruling class. "They have not taken over the governing functions," Max Lerner has pointed out, "nor is there any sign that they want to or can. They have concentrated on the fact of their skills rather than the uses to which their skills are put. The question of the cui bono the technician regards as beyond his technical competence."
Page 282, on suburbia:
Looking at the real estate situation right after the war, a group of Chicago businessmen saw that there was a huge population of young veterans, but little available housing suitable for people with (1) children, (2) expectations of transfer, (3) a taste for good living, (4) not too much money. Why not, the group figured, build an entire new community from scratch for these people?
Page 302, on anomalies in the suburbs:
One court was thoroughly confounded by the arrival of a housewife who was an ex-burlesque stripper and, worse yet, volubly proud of the fact. She never learned, and the collision between her breezy outlook and the family mores of the court was near catastrophic. "They're just jealous because I'm theatrical folk," she told an observer, as she prepared to depart with her husband in a cloud of smoke. "All these wives think I want their husbands. What a laugh. I don't even want my own. The bitches." The court has never been quite the same since.
Page 335, on the roots of soul and the importance of initial conditions:
It is much the same question as why one city has a "soul" while another, with just as many economic advantages, does not. In most communities the causes lie far back in the past; in the new suburbia, however, the high turnover has compressed in a few years the equivalent of several generations. Almost as if we were watching stop-action photography, we can see how traditions form and mature and why one place "takes" and another doesn't. Of all the factors, the character of the original settlers seems the most important. In the early phase the impact of the strong personality, good or otherwise, is magnified.
Page 343, on the communications value of children:
With their remarkable sensitivity to social nuance, the children are a highly effective communication net, and parents sometimes use them to transmit what custom dictates elders cannot say face to face. "One newcomer gave us quite a problem in our court," says a resident in an eastern development. "The was a Ph.D., and he started to pull rank on some of the rest of us. I told my kid he could tell his kid that the other fathers around here had plenty on the ball. I guess we fathers all did the same thing; pretty soon the news trickled upwards to this guy. He isn't a bad sort; he got the hint - and there was open break of any kind."
Pages 359-360, on the downside of group activity:
Perhaps the greatest tyranny, however, applies not to the deviate but to the accepted. The group is a jealous master. It encourages participation, indeed, demands it, but it demands one kind of participation - its own kind - and the better integrated with it a member becomes the less free he is to express himself in other ways.
Page 362, on the tyranny of involvement:
Well? Fromm might as well have cited Park Forest again. One must be consistent. Park Foresters illustrate conformity; they also illustrate very much the same kind of small group activity Fromm advocates. He has damned an effect and praised a cause. More participation may well be in order, but it is not the antidote to conformity; it is inextricably related with it, and while the benefits may well outweigh the disadvantages, we cannot intensify the former and expect to eliminate the latter. There is a true dilemma here. It is not despite the success of their group that Park Foresters are troubled but partly because of it, for that much more do they feel an obligation to yield to the group. And to this problem there can be no solution.
Is there a middle way? A recognition of this dilemma is the condition of it. It is only part of the battle, but unless the individual understands that this conflict of allegiances is inevitable he is intellectually without defenses. And the more benevolent the group, the more, not the less, he needs these defenses.
May 8, 2007 5:44pm
billg at mix07
Bill Gates borrows a page from Dion while presenting at Mix '07:
(With apologies to Presentation Zen)
May 7, 2007 5:24pm
oakland crime maps VI: public, indexed data
Things have been generally quiet on the Oakland crime scraping front since we released Modest Maps and I demonstrated some potential display ideas for the crime report records I'm borrowing from the Oakland PD. Here, I describe how I've chosen to make the data public in a purely-RESTful way with indexes.
The small demo at that second link above hooks up to a quick database-driven web service written in PHP, and making it live drove home the point that hosting live databases is tedious and unsatisfying.
Meanwhile, Tom Coates is drumming away about natives to a web of data, Matt Biddulph is telling information architects about RDF and API's, and Mark Atwood is releasing S3-backed MySQL storage engines. Putting these threads together suggests an interesting, or at least more durable, way of publishing pure data on the web. The MySQL engine is an interesting stake in the ground, but it hides its data and its index (the two primary components of a relational database) behind the usual MySQL server process. The contents of storage aren't open to data consumers, ditching many of the cost and scale advantages of a service like S3 by piping it all through your annoying old DB server. Tom and Matt already have the data-on-the-web bit covered, so I'm going to do something about the index.
Indexes to a database table are exactly what they are to anything else: a faster way to look up information than scanning through it all in order. It's how you jump straight to the "M's" in the phone book without a lot of paging back and forth. The most popular style of index is something called a binary tree. Imagine looking for a particular word in the dictionary: you open the book up to some page in the middle of the book, check to see whether your word is before, on, or after the current page, and then move back and forward in the book in large chunks of pages until you've found what you're searching for. This is generally much faster than starting at "A" and turning single pages to find your word. A binary tree works the same way.
Indexes are rarely exposed, even on good web-of-data citizens. Both Flickr and Twitter make it somewhat difficult to move through giant lists, though not anymore difficult than other sites. Meanwhile, the databases quietly running these services are wildly denormalized and indexed like crazy, making it possible to rapidly generate those long, long lists.
For the crime reports, I started by just getting the data up and public. It's at predictable URL's, like these:
- http://data.crimespotting.org/ Oakland-2007-05-03-MURDER.html
- http://data.crimespotting.org/ Oakland-2007-05-01-VEHICLETHEFT.html
- http://data.crimespotting.org/ Oakland-2007-01-01-ROBBERY.html
If you are looking for crimes on a particular date with a particular type, you just ask for a guessable URL. This is in effect the primary key: the natural, internal storage format for the data. Most common types of crime happen on most days, so the majority of date/type combinations should Just Work, and a simple HTTP 4XX error tells you when there is no match. I've chosen to publish in XHTML format for two reasons: the markup is highly semantic, making it simultaneously machine-readable and human-readable. Realistically, I'll be adding JSON and POX pages soon.
Unfortunately, if you're looking for a particular case number, or crimes at a particular location, it would require hunting through every page of crimes. In database terms, this is known as a table scan, and is something to be avoided at all costs. Instead, I've created a set of indexes to the data, demonstrating the key trade-off: an index helps you find what you want, but takes space to store and time to calculate. Following the Case Number link above takes you to a page with a long, nested list on it, a binary search tree. The idea is that you enter looking for a particular case number or range of case numbers. You start by comparing the one you want to the one at the top of the page. If they match, you're done. If yours is smaller, you proceed to the first nested list. If it's larger, you proceed to the second. Eventually, you arrive at the number you want and get back a pointer to one of the date/type pages above where that particular case number can be found. For example, searching for case number 07-015248 gets you Oakland-2007-02-22-ROBBERY.html.
I've also chosen to use b-trees for latitude and longitude, but these will soon be replaced: r-trees are a similar format more suitable to two-dimensional information used by geographic systems such as PostGIS.
In a database, this link-following and tree-climbing process happens very quickly on a single server, ideally in RAM with a minimal number of disk hits. In the scheme I use, a lot of the processing overhead is offloaded to smarter clients: Flash or Ajax apps that know they're looking at an index, and understand a thing or two about traversing data structures. Disk access is replaced by network access. The information is chunkier (longer lists, fewer requests) to minimize network overhead as much as possible, but it's certainly not going to be as speedy as a connection to a real database. There's a short list of reasons to do this:
- A "database" that offers nothing but static file downloads will likely be more scalable than one that needs to do work internally. This architecture is even more shared-nothing than systems with multiple database slaves.
- Not needing a running process to serve requests makes publishing less of a headache.
- I'm using Amazon Web Services to do the hosting, and their pricing plans make it clear that bandwidth and storage are cheap, while processing is expensive. Indexes served over HTTP optimize for the former and make the latter unnecessary. It's interesting to note that the forthcoming S3 pricing change is geared toward encouraging chunkier blocks of data.
- The particular data involved is well-suited to this method. A lot of current web services are optimized for heavy reads and infrequent writes. Often, they use a MySQL master/slave setup where the occasional write happens on one master database server, and a small army of slaves along with liberal use of caching makes it possible for large numbers of concurrent users to read. Here, we've got infrequently-updated information from a single source, and no user input whatsoever. It makes sense for the expensive processing of uploading and indexing to happen in one place, about once per day.
I'm reasonably happy with this so far, but I haven't yet written a smart client to take advantage of it. The near-term plan is to replace the two latitude/longitude indexes with a single spatial index, and then revisit the whole thing after I have an idea of how complicated it is to consume.
May 3, 2007 5:40pm
cathedral tour
We gave a talk about our work at SOM on Tuesday, and in return they offered a tour of the Oakland Cathedral construction site. This was a special treat for Gem and I, because we live a few blocks away from the site, and have been jealously plotting to sneak in ever since they broke ground last year.
A few things we learned: the Cathedral sits atop a crypt, whose contents are a major source of revenue for the Diocese. They refer to the spaces they sell as "product". There is space planned for an organ, but organ design is something that has to take place after the space is built, because acoustics are so touchy. Fortunately, their organ designer happens to live in Oakland. The reliquary itself is seismically isolated from the ground below and the remainder of the site, and is spec'd to stand for 300 years.
Here are my photos, starting with Dapper Tom:














































May 1, 2007 10:06pm
blog all dog-eared pages: shock of the old

Shock of the Old is a technology book by David Edgerton that focuses on use in favor of invention, illustrated with examples of under-the-radar technologies (e.g. corrugated iron, DDT, etc.) that make a larger social impact than more visible, highly-touted inventions. These are a few interesting passages I've marked.
Pages 75-76:
As one philosopher of technology noted in the 1970s: "In almost no instance can artificial-rational systems be built and left alone. They require continued attention, rebuilding, and repair. Eternal vigilance is the price of artificial complexity." He noted too, that in a technological age we should ask not who governs, but what governs: "government becomes the business of recognising what is necessary and efficient for the continued functioning and elaboration of large-scale systems and the ration implementation of their manifest requirements."
Page 83:
So concerned were Ford with maintenance and repair that they investigated and standardised repair procedures, which were incorporated into a huge manual published in 1925. ... However, this plan did not work - it could not cope with the many vicissitudes and uncertainties of the car-repair business. The Fordisation of maintenance and repair, even of the Model T, did not work. As the British naval officer in charge of ship construction and maintenance in the 1920's put it: "repair work has no connection with mass-production."
Page 89, on jet engines:
Typically, there is at first a slight rise (because of unanticipated problems) and then a fall over ten years to 30 per cent of the original maintenance cost. This is due to increasing confidence in the engine itself and increasing knowledge of what needs maintenance. In other words, the maintenance schemes, programmes, and costs are not programmable in advance. In these complex system a great infrastructure of documentation, control, and surveillance is needed, and yet informl, tacit knowledge remains extremely important.
Page 114-115:
In the early 1930's there were all sorts of suggestions for the creation of an "international air police" along these lines, and similar thinking continued into the 1940's, usually with the British and Americans as that international police force. In more recent years the atomic bomb, television, and above all the internet and world-wide web have featured in this kind of techno-globalism. As we have seen, it was generally the older technologies which were crucial to global relations - today's globalisation is in part the result of extremely cheap sea and air transport, and radio and wire-based communications.
Page 169, on food production and slaughterhouses:
To understand the uniqueness and significance of these reeking factories of death, it is illuminating to cross ... the Mediterranean a century later, against a new tide of migration into Europe. In late twentieth-centure Tunisia, on several main roads through the desert there were concentrations of nearly identical small buildings lining each side of the road. Tethered next to many were a few sheep; hanging from the buildings were the still fleece-covered carcassas of their cousins. For these were the butchers' shops and restaurants. As the heavy traffic roared by one could dine, on plastic tables, without plates or cutlery, on delicious pieces of lamb taken straight from the displayed cadaver and cooked on a barbecue crudely fashioned from sheet metal. Clealy this spectacle was not a left-over from the past, or the sort of thing which attracted tourists. It was something new; a drive-in barby for the Tunisian motorist and lorry-driver in a hurry.
Page 189, on belief in technical progress:
There is an old Soviet joke which goes to the heart of the issue: an inventor goes into the ministry and says: "I have invented a new button-holing machine for our clothing industry." "Comrade," says the minister, "we have no use for your machine: don't you realise this is the age of Sputnik?" Such sentiments shaped policy, not only in rockets, and not only in the Soviet Union.
May 1, 2007 5:51pm
digg api, followup
Almost two weeks ago, Digg launched the API that we helped design. Since then, a few interesting uses have popped up that deserve a mention:
- Alex Bosworth created Who's Digging You?, a javascript-based app that cralws over your list of submitted stories and finds the people who've dugg them the most. Also throws in the usernames of submitters whose stories you digg the most for good measure.
- Derek Van Vliet made the Smart Digg Button, a Firefox browser extension that checks with Digg for every page you visit, and inserts a tiny display of digg counts for that URL from Digg. If this were Google, I'd be worried - the extension necessarily sends Digg a record of every page you visit, so it raises some privacy alarms. Still really neat though.
- Diggest is a player that shows popular videos and the Digg comments attached to them. It's the first comment-based API use I've seen, and has a great MST3K/peanut gallery feel.
- Derek Van Vliet also wrote PyDigg, one of many language-specific API toolkits. I've seen others for .NET, Ruby, Java, and so on, but Python is the language closest to my heart so I'm linking to this one.
Apr 30, 2007 6:59am
cameras, twitter, style sheets
Three things that are making me happy right now:
- My Sony/Ericsson w810i phone camera.
- The page layout on Twitter.
- display: in-line and background-color in CSS.
I got the new phone after my going-on-four-year-old Nokia was stolen in February. It was the only decent candybar phone being offered by any of the local providers, and I switched from Verizon to Cingular just to get it. In addition to accepting MP3's of P+B as ringtones, it has a camera on it that totally beats the pants off the Nokia N90 that I tried out last year.
I also recently came crawling back to Twitter, after leaving in a huff in four or five months ago. This time, I'm being less profligate with the friends feature and I'm posting mostly pictures instead of words. I like the idea of Twitter as a constrained medium for short bursts of communication, and the fact that a few of the people I know using it don't make an extra effort to page back into posts they've missed. It's a very in-the-moment style of update, and I think it's far more appropriate to camera phone snaps than Flickr. They give you a permalink for your "tweets", but it's not a focal point like on the photo-sharing sites. This makes Twitter a better home for throwaway shots, albeit one that has no built-in photo upload mechanism.
This is where twitter-pic.php comes in, a stupid-simple PHP script that accepts e-mails on STDIN and pushes their image contents to Twitter. Images too fleeting to post here belong there.
Technology aside, I very much like Twitter's page layout. Their default is a giant, statically-placed, user-defined background image with blocks of text-filled color in the foreground. It's quite elegant, and very CSS-appropriate. I keep noticing these little technology-driven design details being celebrated and even jumping media boundaries. Tom showed me a UK magazine the other day that's using text block backgrounds directly nicked from the default rendering of an in-line element with a defined background color. This particular detail has a cultural resonance as well, after six years' worth of popping up in the news in the form of redacted government documents (see New York Times and John Emerson).
This has really been a long way of saying that I just redesigned my website incorporating phonecam pictures, giant backgrounds, and blocky text backgrounds, and that you should let me know what you think.
Apr 20, 2007 7:46pm
blog all dog-eared pages: the box

When I read, I often mark interesting pages and then forget about them. This is an effort to note what I found interesting about non-fiction books I've finished, starting with The Box, Marc Levinson's excellent book about the containerization of the shipping industry. I read it about two months ago.
Pages 12-13:
The importance of innovation is at the center of a second, and rapidly growing, body of research. Capital, labor, and land, the basic factors of production, have lost much of their fascination for those looking to understand why economies grow and prosper. The key question asked today is no longer how much capital and labor an economy can amass, but how innovation helps employ those resources more effectively to produce more goods and services. ... Even after a new technology is proven, its spread must often wait until prior investments have been recouped; although Thomas Edison invented the incandescent lightbulb in 1879, only 3 percent of U.S. homes had electric lighting twenty years later. The economic benefits arise not from innovation itself, but from entrepreneurs who eventually discover ways to put inventions to practical use.
Page 53:
Malcolm McLean's fundamental insight, commonplace today but quite radical in the 1950's, was that the shipping industry's business was moving cargo, not sailing ships. That insight led to a concept of containerization quite different from anything that had come before. McLean understood that reducing the cost of shipping required not just a metal box but an entire new way of handling freight. Every part of the system - ports, ships, cranes, storage facilities, trucks, trains, and the operations of the shippers themselves - would have to change. In that understanding, he was years ahead of almost everyone else in the transportation industry.
Page 184:
"Containerization cannot be considered just another means of transportation," Besson told Congress in 1970. "The full benefits of containerization can only be derived by logistic systems designed with full use of containers in mind."
Apr 20, 2007 6:59am
digg's api is public
Digg launched their API this evening, something that's been a long time in coming. We first worked with Digg to help design it back in mid-2006, in support of the Digg Labs project that launched in late summer. Since that time, and among other work, we've been slowly expanding its range and working out kinks and inconsistencies. Today, I'm proud to say that the new Digg API totally kicks ass.
Available endpoints include lists of stories, users, diggs, topics, and comments. The whole thing is available in four flavors: XML, JSON, Javascript, and serialized PHP. We designed in a few niceties for site owners, like being able to search for stories based on URL or domain, and added awareness of friends, users, and comments. We did not design any read/write endpoints, because the jury is still out on how to support digging and submission via an API without letting in all the crazy hackbots. Stay tuned on that one.
Also included in today's announcements are the contest and the Digg Flash Development Kit, the latter developed by Shawn. Although we're not releasing the display code used to run Stack or Swarm, everything else used to build those tools is included: API support, call scheduler, object model, etc. It's quite a bit to get my head around.
Apr 20, 2007 1:29am
disinfographics
Dion Hinchcliffe is a blogger responsible for an intimidating volume of writing on web 2.0, ajax, service-oriented architecture, and other such topics. To accompany his articles, he creates a torrent of infographics that are a clear example of muddled thinking. Arrows point this way and that, boxes sit inside boxes, and labels abound: consumption, viral feedback, REST, engagement. Fortunately, they're all served up from an open directory, so here are a selection of my all-time faves. Click on each to see the full-res original!
This is the first Dion Hinchcliffe infographic I ever saw. Things that struck me: the "mutual sense of community" label under the people (oh, that's where that goes), the arrows labeled REST, HTTP, JSON, and SOAP, and the public edge of the enterprise peeking into the cloud from the right:

I assume there are sentences containing the following words in the accompanying article:

This one has the obligatory internet web cloud:

The important part of this chart is the five blobs to the right, yet the full internal structure of an AJAX application is shown to the left:

"You can't make requests to servers other than the one the page is from":

I like the little thread pinwheels here:

The people consume, create and consume, and socially consume:

The Einsteinian gravity-sheet here is awesome:

The cloud has been upgraded to "2.0":

"The web is growing":

I thought for sure the fall trend for 2006 was open platforms closing up in response to the lure of acquisition:

Apr 12, 2007 7:32am
people as pixels: arirang
I've seen photos of North Korea's Arirang Festival before - it's the archetypal mass calisthenics, card stunts, and gymnastics you've seen in many news photos for years. Still I don't think I was quite prepared for everyoneforever's pointer to an official TV ad for the event. (Could also be the Faithless talking) Go watch it.

It's the same kind of scary-wonderful as UVA's LED displays (1, 2, 3) and Triumph Of The Will. Leni Riefenstahl and UVA both let you see their pixels; they emphasize the large scale of what you're seeing by revealing the tiny elements that compose it. Arirang is powerful, because each one of those moving, jumping, swaying dots is a human being bent (literally, figuratively) into shape as part of a single performed piece. There are a few super-intense shots near the middle/end that alternate between close-ups of color-coded dancers and long shots of massively-parallel synchronized acrobatics. A few of our projects, such as Digg Labs and MoveOn, give me the shivers when I look at the data collections we're working with and see the individual, emotional decisions through all the pixels, rows, and elements. With Labs in particular, the last time we pushed a major update was right around the time that James Kim and his family were lost in Oregon. Our testing data was live, and constantly threw reminders to the surface in the form of hopeful and later tragic headlines.
Apr 10, 2007 6:48am
global voices online relaunches
Boris got a fresh overhaul of GVO out the door this morning, and it looks fantastic. The entire site has been updated, with swooshy drop-down tab areas for the previously-weird tag clouds, and just a general sprucing and buffing throughout. The site aggregates an epic volume of content from blogs around the world, with special focus on bloggers from outside Western Europe, North America, and Australia.
I helped in a small way, by implementing the contextual maps on the site's country and region pages. Boris saw the need for these things to provide some framing for local issues by showing their relationship to news from neighboring places. This was the project I worked on when I visited Tokyo last month. This project is one of a short list of early applications for Modest Maps, an ActionScript library I've been working on with Darren, Shawn, and Tom since January. We used satellite imagery courtesy of NASA's Blue Marble and country borders from the Mapping Hacks data collection.
The maps currently fit in the sidebar, but a week's worth of tonkatsu-fueled brainstorming had us thinking about a few other possibilities:
- Five minutes of playing with the Nintendo Wii's geographical news globe made it obvious that a full-screen version made sense.
- A little bit of geocoding applied to GVO's extensive backcatalogue could lead to stories linked to specific cities instead of just countries.
- It should be possible to drag, pan, and zoom these, but not in their current tiny sidebar home.
The maps have two states, roll over them on the GVO site to see both:
Apr 2, 2007 8:00am
sunday ride
We rode 14.8 miles through Oakland, Berkeley, and Emeryville this afternoon. Stopped for a Zywiec near mile 12, site of this totally sweet kid-trap playground.
Mar 30, 2007 6:24am
browser shims (lazyweb)
Last week I tried out Cocoa Dev Central's One Line Of Code Browser. It's an Xcode tutorial that shows how to create (from scratch) a Mac OS X standalone application with a text entry field, a fetch button, and a WebKit view - a complete browser in just one line of code. It's actually one line a code and a fuckton of clicking around in Xcode and Interface Builder, but their point roughly stands. I opened the tutorial when I got on BART, and had a running browser six stops later despite never having used Xcode before.
The promise of WebKit is that it makes possible a range of hybrid, web-on-the-desktop applications for prototying and deploying. Matt has tread this ground before, but it's worth repeating. Tom and I kicked around a few ideas for such applications over beers, but they hinge on the existence of open source browser shims for Mac, Windows, and Linux. This should be possible with WebKit, Explorer, and Konqueror or Firefox, but it's outside of my area of expertise. Does such a thing exist? Can it? I'm picturing and application kit that lets you specify width and height of the final window, pack in some html, css, and javascript, and pop out an executable for any platform that runs the resulting browser-in-a-box as a first-class application.
Mar 28, 2007 7:31am
space needle
Peacay has some amazing architectural renderings of the Seattle Space Needle and other attractions at the Century 21 1962 World's Fair.
I can't help but feel terrible for this guy, trapped deep in his dull office, hundreds of feet in the sky with no windows:

Mar 23, 2007 11:44pm
stamen in pingmag
We're heavily name-checked in Pingmag today, Infosthetics: the beauty of data visualization.
Mar 23, 2007 8:02am
oakland crime maps V: modest maps
One of the main tasks I needed to handle for my project with Oakland's CrimeWatch application (previous: I, II, III, IV) was a Flash-based display for maps of criminal events. Darren, Shawn, and I banged out what has now been released as Modest Maps. As it turns out, a whole bunch of other current projects needed the same thing, so development has been rapid over the past few months and we're now at a point we feel comfortable calling 1.0 beta.
![]()
Modest Maps is a BSD-licensed display and interaction library for tile-based maps in Adobe Flash 7+, written in ActionScript 2.0.
Our intent is to provide a minimal, extensible, customizable, and free display library for discriminating designers and developers who want to use interactive maps in their own projects. Modest Maps provides a core set of features in a tight, clean package, with plenty of hooks for additional functionality.
Future releases may include display layers in ActionScript 3.0 and WPF (Windows Presentation Foundation), but for now it's a kick-ass tile-display engine that can pull in map layers from a variety of sources.
Mar 13, 2007 5:02am
what to do when they don't
Someone in our building left a copy of How Things Work In Your Home (And What To Do When They Don't) sitting out on the "free" table. Gem brought it in before anyone could get their paws on it. It's a 1975 Time-Life book on repairing household items, and features detailed cutaways and exploded views of any kind of machine, gadget, or appliance typically found in a 1970's home.

Each chapter is identified by a single spot color that unifies it as plumbing, electrical, air conditioning, etc. The illustrations are detailed with a characteristic 70's "fat outline", and describe inner workings of motors and septic tanks.
Clocks:
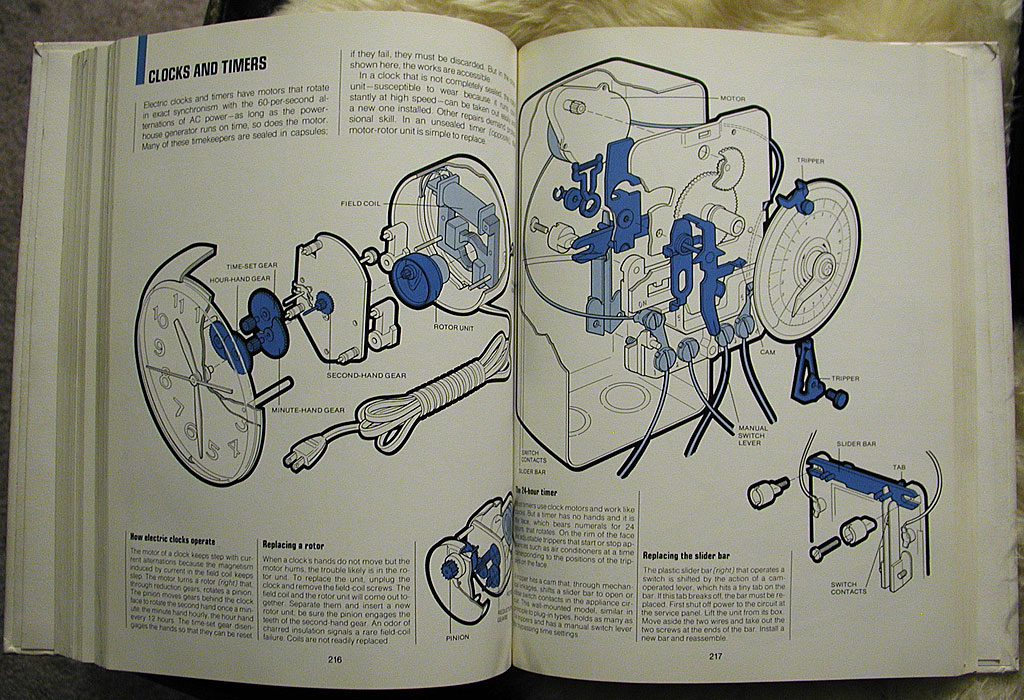
Faucets:
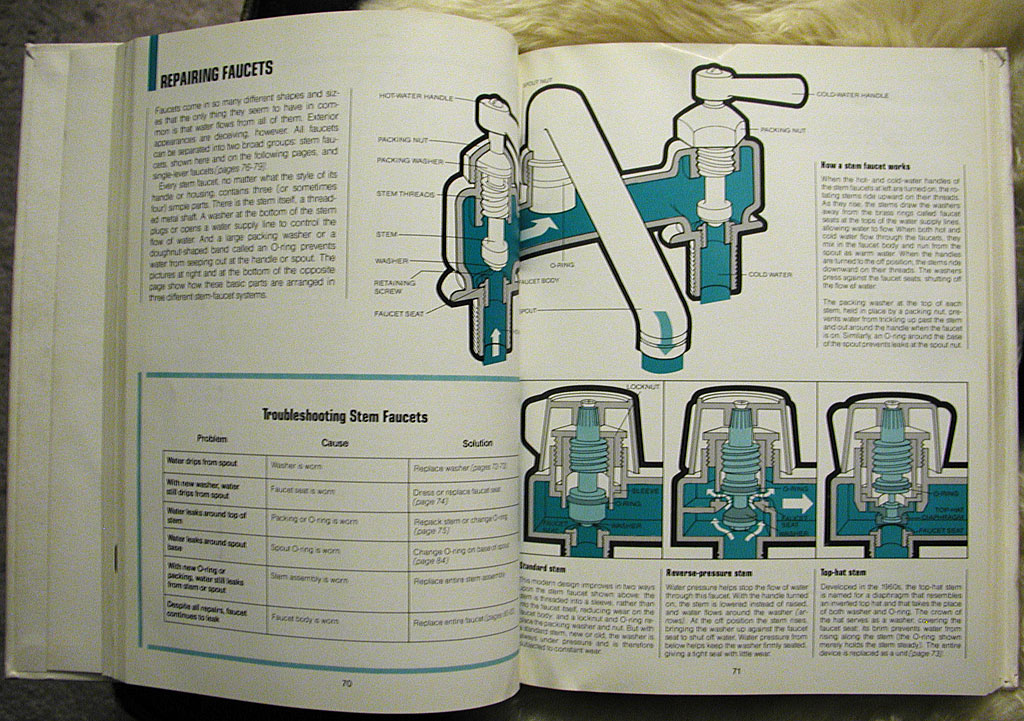
Toilets:
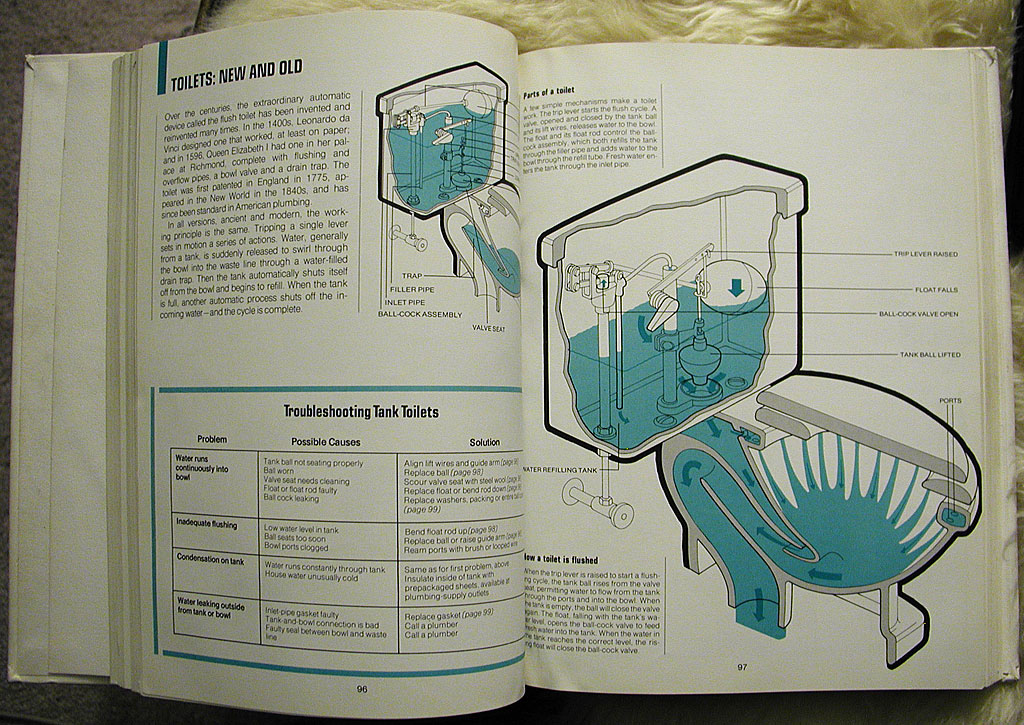


Mar 7, 2007 1:32am
that was the winter of my discontent
After an overly-long, sucky winter, I'm back on my bike as of this past weekend. The leg still bothers me but it's nothing like the misery of December and January, when I slept on the floor for two months and was forced to scrape JPEG's to take my mind off the pinched nerve.
Mar 5, 2007 7:55am
more against openID
(This post is an expanded version of a comment I left on Josh Porter's blog)
I expressed my reservations about OpenID last month, and here I am doing it again. A recent post from Josh Porter made me think some more about why I believe OpenID is such a stillborn concept.
I'm actually pretty impressed with the technology behind OpenID, especially its distributed design and lack of dependence on any one point of failure. The core promise for users is the ability to coordinate sign-on credentials between sites, so you only need to remember one username/password combination. It does this by treating your URI (the location of your blog, or whatever) as your identity, and authenticating against that. The site to which you're trying to prove your identity (the consumer, I guess) contacts the URI that stores your identity (the provider), some encrypted magic takes place, and you get to leave a comment or upload a photo without having to remember another set of login details. So far, so good.
The problem with OpenID is that it violates one of the longest-runnings stories we tell ourselves about the Internet, from the famous New Yorker cartoon:

They do a great job of arguing that it's a legitimately open protocol, with no patent encumbrance or vendor sports involved. I have no reason to disbelieve them, but I also don't believe the openness of the protocol matters. The point where it fails is that your proof of identity is only as good as its perceived strength. When I was younger, getting into bars or buying booze for the under-21 people I knew meant having a fake ID, and it was commonly known that some states has shittier licenses than others. I forget which was which, but you were supposed to pretend to be an out-of-state student from a place where they used cheap laminate, no holograms, and common fonts on the ID itself. These were the ones you'd try to fake, and it was up to the bouncers and bartenders to decide whether your scuffed-up, delaminated card was a fraud.
OpenID suffers from this same problem, but I can see it leading to a chain reaction of lameness that brings us right back to where we are now, in terms of identity on the web:
- Let's say you set up your own OpenID provider, littleguy.example.com. This is the core of OpenID's openness: anyone can set up their own provider. They have a list, or you can make your own. The account or server where your provider lives may be compromised, but OpenID consumers have no way of knowing it. How can they be informed that littleguy.example.com is actually a wolf in sheep's clothing?
- Because it's difficult to know whose identity provider is secure and trustworthy, smart identity consumers who actually let you do stuff with your identity will exercise caution in choosing the OpenID's they accept. SomeBigCo might decide to not accept identities from littleguy.example.com, treating it like an easily-faked drivers license. This is the point where OpenID's openness stops being important: the protocol may be pure, but participants still have to decide whom they can trust.
- It's kind of a crapshoot to figure out why SomeBigCo refuses to accept your provider, so you follow Simon's advice and set up a SomeBigCo identity. The point of OpenID is to have just one, so that's the one you decide to stick with. Now, every time you use that identity to authenticate someplace, SomeBigCo gets to know. It knows about your SomeBigCo accounts, your OtherBigCo accounts, and all your LittleOrg accounts, which is immensely valuable marketing information. If SomeBigCo knows that I have a $50/month Twitter Pro account, I start to look like the kind of person who might pony up for other services. Maybe SomeBigCo sells this information because its shareholders demand it be monetized, or an employee with a meth addiction and a vendetta decides to sell it on the black market. Maybe SomeBiggerCo buys SomeBigCo to get their hands on it. The point is that it's worth money.
- Meanwhile, OtherBigCo is unhappy that SomeBigCo knows all this stuff about when its users log into their OtherBigCo accounts, so it decides to stop accepting any non-OtherBigCo identities. All the value in OpenID is in being a provider, as Microsoft discovered when Passport got nowhere with non-MS companies who didn't like the idea of giving all their user information to Microsoft for free. This is square one: Yahoo!, Google, and Microsoft will happily provide OpenID, but see no long-term sense in consuming it. Your "identity" becomes useless anywhere outside those walled gardens, except in its original use case: leaving comments on blogs.
This is as it should be. People who know me know that I like to kill off old accounts as often as I start new ones, so the permanence of a global identifier has no attraction for me. People who read Danah on teens and social software know that kids happily put tons of time and effort in creating, maintaining, and destroying online identities, so I don't put a lot of faith in the tech consultants whining about how miserable they are having to recreate their LinkedIn buddy lists on last.fm. People who use Mac OS X know that the whole "ZOMG too many passwords!!1!" issue can be dealt with cleanly and elegantly by client-side keychain software that stores your valuables on your own machine, where no one is tempted to sell them for marketing purposes except you (Root's big idea in 2005).
The ridiculous thing about OpenID is that it has no value unless loads of people buy in, which I assume is why there have been so many "we will support OpenID mumble-mumble" announcements in recent months. If it gains any traction at all, it's going to be just like the consumer credit system without all that pesky government oversight getting you a free personal report once a year and going after abusers. It's a cute technical approach to a big, hairy social status quo, and I'm sitting here writing a big-ass diatribe about it because I don't want to find myself forced into signing up for a SomeBigCo account two years from now and getting all my shit stolen or sold, ChoicePoint-style.
Mar 2, 2007 12:47am
oakland crime maps IV
Last month, I posted a few notes on possible displays of crimes in time. This post shows the small amount of headway I've made towards implementing the competing ideas of spherical vs. conical fields around crime events.
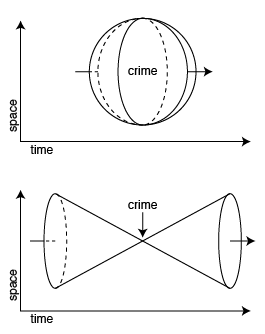
The difference between the two boils down to the shape of the three-dimensional field (two dimensions of space, one of time) that surrounds a criminal event. The sphere is centered on the event, and is largest in space when closest in time to the crime. The cone is smallest in space when closest in time, but ripples forward and back.
These are the results so far:
Spherical Fields
This was the initial idea, and it makes visual sense when animated. Drag the small gray slider at the top of this image back and forth to see how it works:
See a larger version of this view.
Red circles show a crime that is yet to happen, while blue circles show a crime that has already happened. The black dot in the center is visible only inside the sphere.
Conical Fields
Cones were the second idea, inspired by a conversation with Adam Greenfield which suggested that a ripple or light cone was a better visual metaphor. Here, the red circles start out large and converge or focus down to the crime before expanding again in blue:
See a larger version of this view.
The most confusing aspect of the conical version is that it still reads as big = close, which is not quite right. It should read as focused = close, so Eric and I experimented with a blurs to better suggest that the event is coming into and out of focus as you slide back and forth in time:
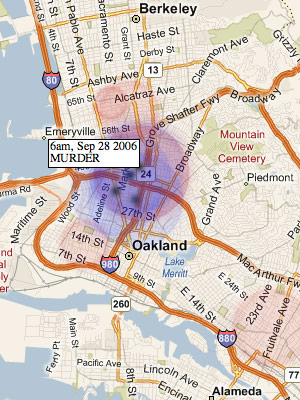
There are two versions of this interactive piece to play with full-screen, showing murders and prostitution. The second one is interesting, because it shows that prostitution arrests in West and East Oakland (along San Pablo and International Boulevards) occur in waves. The two areas are relatively quiet for days or weeks, then suddenly get hit with a block of arrests. I'm guessing this is due to planned and coordinated OPD vice squad activity. You can see examples of such waves on February 15, January 18, December 20, and December 14.
Mar 1, 2007 7:50pm
ichat san franciscoes
It took three people five minuets of staring and comparing to realize that the top image was upside-down, and needed to be flipped:
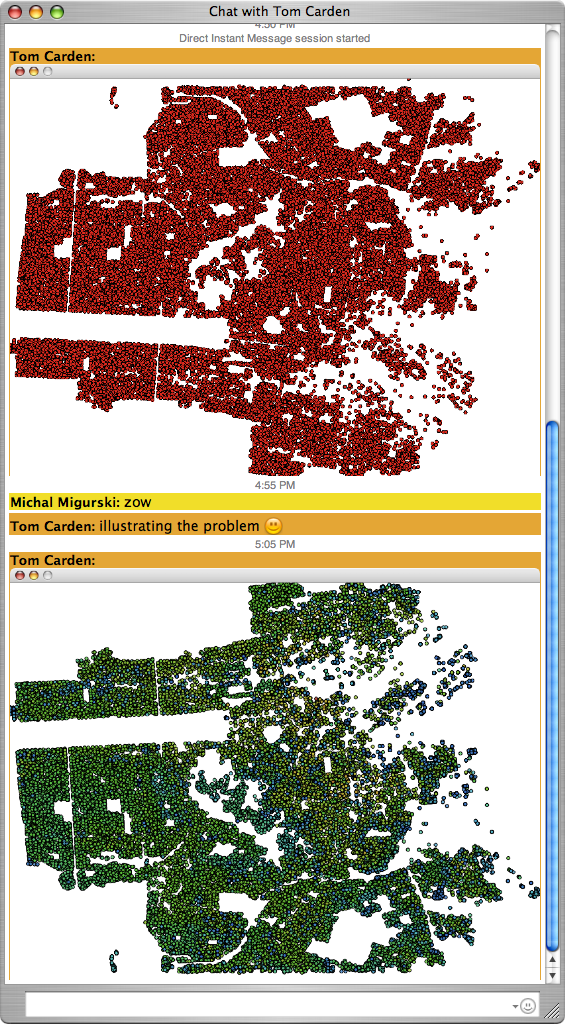
"What's that big blank spot in Cow Hollow?"
Feb 28, 2007 8:02am
transparency codes
I went to hear Michael Pollan (author, Omnivore's Dilemma) and John Mackey (CEO, Whole Foods) converse on the Zellerbach stage in Berkeley tonight. Peter has more notes. One thing really struck me. Actually, two things really struck me, but I don't want to talk about the fucked-up video depicting graphic abuse of animals at dairy, poultry, and hog farms that was part of Mackey's talk.
Pollan brought up a service offered in selected Danish supermarkets:
Packages of meat and poultry carry a bar code that, when scanned by a machine in the store, calls up pictures of the farm where the animal was raised, as well as information about its diet, living conditions, the date of its slaughter and so on. Imagine how quickly this sort of transparency would force a revolution in our food chain. (Produce Politics, scroll down)
Two years ago, Patrick told us about a service offered in Japan, where your store-bought bananas come with a code printed on the label that can be used to find a web page featuring the grower of that particular banana, and (I think) some details on when it was grown and where it came from.
It's too late to make an informed buying decision about a banana when you're back near a computer, and installing special reader hardware in supermarkets is expensive. Both ideas could be easily handled by cameraphone-readable QR codes like this one:

They're big in Japan, not so much in Europe or here. It'd be wild if an upcoming generation of mid-range mobile phones supported these dumb things. I'm told they're easy, and Aaron has been doing some smart stuff with codes and little folded-up paper printouts. They'd be an everyday vehicle for the kind of environmental information overlay that would make Pollan and Mackey's desire for food industry transparency remotely possible - where else would you want to make the decision, than right in the store when you're staring at two kinds of stilton trying to guess which cow suffered less?
Feb 22, 2007 10:02am
(no longer) big in japan
I returned from Japan yesterday, where I spent a week hanging out with Boris, helping with part of the redesign effort for Global Voices Online.
I didn't take a camera with me, so this is a collection of photos from Flickr that are better than any I would have taken.
My first stop off the train from the airport was Shibuya (渋谷) Station, where I was supposed to meet Boris. I mistakenly expected the European experience of meeting on the platform, so I spent about 40 minutes pacing around as wave after wave of people finishing work boarded their evening trains. The platform was constantly this crowded, with a fresh rotation of passengers every five minutes or so:

(photo by halonfury)
Eventually, I figured out that a ticket was required to get to the platform in the first place, so I used my piddling 50¥ to call and make everything okay. Next time, better arrival preparation.
I stayed at Joilab, in Jiyugaoka, an apparently ritzy part of town with extremely narrow streets.

(photo by shibo)
Bananas often come individually wrapped. I saw my first $4 apple.

(photo by A is for Angie)
Adam warned a bunch of people I was coming, but I got to meet them anyway. This is Craig and Chris, of AQ:

(photo by cpalmieri)
Both were wearing normal shirts when I met them. Chris wrote the excellent guide to mapmaking for Tokyo I linked the other day.
AQ's office is in Co-Lab, a shared office space where designers of various sorts rent tiny cubicles and ethernet connections. It's partially a rent-reduction move, but also a way to squeeze with like-minded people. The space houses AQ's other project, Tokyo Art Beat. Paul showed me their use of QR codes on venue pages, which is interesting. This is probably old hat to anyone with any experience of mobile phones outside the US, but the idea of a commonly-readable 2D barcode for transmitting snippets of information via stickers or posters is just great.

Weekend was all work-work-work and food-food-food, including these oysters:

(photo by bopuc)
Then we took a quick trip up Mori Tower. The view from the top of this beast is just insane, and especially worthwhile when your visit can straddle the sunset. We didn't see Fuji, but it was still quite a panorama.

(photo by Koninho)

(photo by Urban|nexus)

(photo by /\ltus)
While in Tokyo, I kept seeing bikes like this one around town. They're made by Muji, a sort of Japanese general store that sells well-designed stuff ranging from ice cream to stationery to bicycles. The frame design with single horizontal post is great, everyone rides them around town, and I almost bought a new one for $150 but decided it was silly to drag a bike home.

(photo by ihateanarchists)
My other shopping experience while there was Tokyu Hands, a "Creative Life Store" that sells an unclassifiable range of everything. The Shinjiku branch I visited was about eight floors of stuff. I bought some Tabi that ended up not fitting very well.

(photo by antimega)
Now I am home, it's late, and I'm mildly jetlagged.
Feb 14, 2007 12:50pm
work with me
We're hiring again, this time for a visual designer:
This is a hands-on web design position. You'll be working with a team of designer/engineers who will be looking to you to help make their ideas sing. You should be the kind of person who can rework and iterate an idea until it's perfect.
Let us know if you think you fit the description.
-
Also, I'm typing this from Japan. Woot!
Feb 13, 2007 2:05am
special on NASA blue marble tiles, aisle six
My iMac spent the weekend tearing through NASA's Blue Marble satellite imagery set, projecting the 500m/pixel base map to Mercator, chopping it up into tiles, and uploading it to S3.
Here's the root-level tile:

I took care to ensure that the slices match those in use by Google, Yahoo!, Microsoft, and OSM for cross-compatibility among any code that uses tiles from those providers.
The general procedure took three steps:
- After downloading the full-resolution imagery from NASA and converting the PNG's to VIPS .v format, I extracted tiles at the highest zoom level to individual 256x256 images. This step had to include the mercator projection, which meant extracting squat rectangles near the poles and stretching them vertically to 256 pixels. I used VIPS for this step because its random-access file format is specially designed to support fast region selection from very large bitmaps (eight 21600x21600 pixel images).
- For each lower zoom level, groups of four tiles were combined with ImageMagick. This turned out to be a very basic recursive function that spit out a series of ImageMagick commands as text. God bless sh.
- Finally, every tile was uploaded to S3 and given a standard name: {zoom level}-r{row number}-c{column number}.jpg. The numbering scheme should be familiar to anyone who's worked with tile providers or Zoomify before.
S3's cheap bandwidth and the public domain status of these images means that you should feel free to use them in your own applications. If you plan to do anything unusually demanding with them, please go easy on my wallet and take a moment to sign up for an AWS account and use the following Python script to copy the complete tileset to a fresh S3 bucket of your own:
Feb 11, 2007 6:25am
simple video service
If I were YouTube, I'd think long and hard about a business model based on cats flushing toilets and flatulence flambe. Anyone with any kind of professional interest in their video content will soon realize that YouTube's platform is increasingly a comodity, and that if your content is 1) really good, and 2) embedable, you're pretty much good to go, regardless of which platform you use.
Amazon's S3 (simple storage service) has been amazing for me, and I think that two of the three things YouTube and other video services provide (embedding, hosting, but not socializing) could be covered by S3 and a cheap conversion and uploading application. Local software would reformat video files to .flv, upload them to the user's specified S3 account along with the necessary .swf file for playing them, and spit out the HTML required to embed the video on your site. This feels like a week's worth of late night programming to anyone even marginally accomplished in Windows or Mac development. Amazon's web services account signup is probably not streamlined enough for this to be a widespread thing, largely because they're still thinking of it as a tool for developers, rather than public storage for the internet.
Feb 10, 2007 1:48am
last.fm leaderboard
Shawn is a dedicated user of last.fm, and he's the one usually in control of the speakers here. Last.fm makes it easy to shoulder-surf what he's listening to:
I'm really in love with their leaderboard design, notably the pale gray arrows that show chart movement from week to week. The screenshot above shows that between now and last week, Of Montreal and The Flaming Lips have exhanged #1 and #2 spots, while Broadcast has jumped 14 spots to #4. The charts are just HTML, but every piece of information is linked up, and the display as a whole is quite pretty.
Feb 8, 2007 5:07pm
polite loops
A recent message to the Yahoo JSON user group got me thinking about social norms as programming techniques. The question was about iterations over long sets of data:
I am trying to iterate through a big JSON variable (about 1500 nodes). It works but FF pops up with the message saying the script is not responding (A script on this page may be busy... do you want to stop the script, debug, continue). If I select continue, it works fine. It is just that the iteration takes a bit of time to go through all the nodes. Is there a way to avoid the above? (Carl Harroch)
There's a handy technique I picked up from Twisted Python that I like to call polite loops. Polite, because sharing resources in an environment like a browser takes tact. When you're at a party with an open bar, you don't hog the bartender's attention, downing pint after pint while he's force to wait on you to have your fill. You're polite; you get your Newkie Brown and walk away so someone else can order.
I've found a similar approach especially useful in languages typically used in web browsers, like Actionscript and Javascript. A greedy loop in a typical web browser affects not only the page it's on, but any other page open at the same time. There are usually allowances for this, such as messages that offer you the ability to kill a script in progress. These only appear after a prolonged period of uselessness, so relying on them is a bad idea.
Twisted's built-in event loop, the Reactor, is single-threaded but built to handle asynchronous events such as network traffic or user input. It does this by encouraging finely-grained function calls that hand control back to the Reactor frequently. For example, this recursive function:
def perturbItems(items):
if len(items):
item.pop().perturb()
perturbItems(items)
...might be rewritten like this:
def perturbItemsPolitely(items):
if len(items):
item.pop().perturb()
Reactor.callLater(0, perturbItemsPolitely, items)
It continues to do exactly the same thing: perturbItems() takes the last item, perturbs it (perturbation might be a lengthy and expensive procedure), then passes the remainder of the list back recursively. Instead of calling itself directly, it schedules a call with the Reactor so that other pending or more urgent tasks can be handled in the meantime. The Javascript analogues could look like this:
function perturbItems(items)
{
if(items.length) {
items.pop().perturb();
perturbItems(items);
}
}
...and the polite version:
function perturbItemsPolitely(items)
{
var perturbItem = function()
{
if(items.length) {
items.pop().perturb();
window.setTimeout(perturbItem, 100);
}
}
perturbItem();
}
This function sets up a closure and uses the Javascript window.setTimeout() method to introduce a 100 msec delay between calls. The short delay greatly increases the amount of time the function needs to run, but is also enough of a breather to allow other scripts or user input to have an effect. It prevents the "this script is running slowly..." issue.
Another way to write the same function does it by chunks:
function perturbItemsPolitely(items)
{
var perturbChunk = function()
{
var start = new Date();
while(items.length) {
items.pop().perturb();
if(start.getTime() + 100 < new Date().getTime()) {
window.setTimeout(perturbChunk, 100);
break;
}
}
}
perturbChunk();
}
Same function, same closure. This time, the function perturbs as many items as it can (note the while loop) before reaching 100 msec and introducing a 100 msec rest. Best case, it's no slower than the original recursive loop. Worst case, it takes twice as long with plenty of rest stops. Going back to the original post above, I'd solve the problem by introducing two polite loops: one to request the 1,500 element data set in chunks of a hundred, and a second to iterate over those hundred-element chunks with occasional rest stops.
Feb 8, 2007 3:31am
desk
Ever since visiting BMW's design strategy group in Germany two years ago, I've been thinking about switching to a standing desk (that's a photo of former Secretary of Defense Donald Rumsfeld using his!). I've also more recently been suffering from sciatica, which makes sitting for any length of time kind of an ordeal.
So, my friend Bryan helped me design a new desk that would fit on a typical 30-inch tabletop, let me type at a natural height, and place my computer monitor at eye-height. We decided on maple hardwood legs and a Richlite surface, and I've been using it here for the past two weeks. He's an enormously talented carpenter and cabinetmaker, and the finished piece feels solid and indestructible.

I couldn't be happier with my new non-seating arrangement. It helps my leg feel better, but it's also a more comfortable work surface overall. Two things not visible in these photos make it workable: An anti-fatigue mat on the floor keeps my feet from hurting (though they do, a little), and Synergy on the two computers lets me use the one keyboard & mouse to control the laptop.

Feb 4, 2007 8:28pm
housekeeping
Did a little blog-housekeeping this weekend. Pair hasn't been particularly CGI-friendly for several months now (shared environment, limits on memory usage by scripts) so I translated the parts of Blosxom I was interested in to PHP, and moved away from Perl permanently. The only change you should see is that single-digit dates (like today, February 4) are now displayed without the leading zero, thanks to PHP's excellent date support. I cleaned up the RSS and Atom outputs a bit, and switched to Atom 1.0 as the default feed output. I have no plans to ditch the RSS feed, I just think that Atom's syntax is more aesthetically pleasing.
All links should continue to work as before, but obviously please send me a mail if you see any problems or find broken links.
Feb 3, 2007 7:25pm
openID
Help me understand why OpenID is worth paying attention to. Smart, respectable alpha-geek Simon Willison has focused on pretty much nothing else for the past few weeks, but I can't picture why this is an interesting or desirable technology. It's being touted as an example of "light-weight identity", an adjective I don't think should be applied to any proposed standard suggesting an entirely new kind of identifier. I'm still having trouble with the difference between URL and URI, so what is an XRI for? The protocol may be "drop dead simple", but this sounds like a deal-breaker for any non-wizard looking to understand how it works:
Now, in practice there will probably be concerns about spoofing, so Consuming sites will have whitelists, and which is why you may need multiple Providers to ensure they have one that works everywhere they need it.
My gut feeling is that OpenID is this year's architecture aeronautics moon shot. This ZDNet article makes the case for OpenID, but it lists only three proposed benefits for the "internet user", the only actor whose opinion actually matters in the long haul. Personally, all of the suggested OpenID uses (starting with: "I don't want to remember a long list of usernames and passwords for every site I visit") I've seen are already handled elegantly by KeyChain, Mac OSX's client-side password and secret storage program. "Identity" is itself a fairly abstract concept - I suspect that most people think of it in concrete terms, using wallet-compatible tokens like their drivers license or gym membership card as stand-ins. For internet stuff, my token is my laptop, under my personal control at all times with copies of all those usernames and passwords. If the iPhone spurs US carriers to open up WiFi or bluetooth on phones, my token might be my cell phone. Either way, it's going to stay a physical object with predictable real-world properties.
Feb 2, 2007 7:38am
oakland crime maps III
I haven't been neglecting my Oakland Crime work, just quietly plugging away at it in my off hours. I'm getting to a point where I can start to think about visual presentation, which I'm hoping will be an improvement on the traditional pins-in-a-map GMaps mashup style. I'm moving on two fronts: designing a possible display metaphor for the crimes, and writing software so I can do this in Flash and continue to take advantage of the highly-available, highly-detailed map tile collections from Google, Yahoo!, and Microsoft.
First, interface display. Crime leaves an imprint on the place and time it is committed, and a visual representation should reflect this. I've been thinking about this in terms of residual hauntings:
A residual haunting is a playback of a past event. The apparitions involved are not spirits, they are "recordings" of the event. Video and audio tapes capture sounds and images on a film of special material that has been oxidized or rusted. Certain building materials, such as slate used in older castles and stone structures and iron nails used in many older buildings, have properties similar to that of the tapes. When a traumatic event occurs or a time of heightened emotions, these materials record the event for future playback.
Any personal experience in a crime-prone neighborhood underscores this characteristic: the feeling of fragile safety, heightened alertness, and sensitivity to rumor or hearsay. There are places in Oakland and San Francisco where few non-residents dare to visit. These tend to be on the wrong side of the freeway, and even the brave or foolhardy artists and warehouse hipsters from "outside" who move there do so in packs, hiding inside secured buildings and staying separate from the local street life. The aura of street crime in these areas is strong, and daily movements feel like travels through hostile territory. Entire cities can take on the coloration of their most dangerous parts, leading to generalizations about Oakland being an inherently dangerous place. Sometimes, gentrification may set in and dull the impact of past crime.
In thinking about how to represent these halos on a map, my first idea was to calculate a linear relationship between space and time, and model them as spheres. For example, a mugging or burglary may impact the neighborhood for a few blocks in each direction and linger in memory for a few days. Car break-ins and petty theft can go entirely unnoticed, while homicides make the evening news in neighboring towns. It should be possible to establish a correspondence like "one block equals one day", and assign various influence radii to classes of crime.
This has a direct usability benefit: when selecting a time range to view on a visual map of crime incidents, Crime Watch shows only the crimes that occurred within that span. With spherical halos around each event sized proportionately to their severity, it should be possible to display pins on a map along with some indication that major events may have happened near the selected range, providing a backplane of additional information. Overlapping spheres would give a dynamic, shifting sense of how dangerous a given area is and help in time navigation by hinting at incidents just beyond the selected parameters.
Crime has a social weight, which should be represented by the effect it has on its spatial and temporal neighborhood. Dan Catt brought up this same concept as it relates to geo-aware mobile phone apps and Flickr's new machine tags feature, suggesting an application that gives your handset a light buzz when you pass over a place where some emotional event took place. I fully expect Aaron to have something like already running on one of his Python-and-GPS-enabled Nokias.
Adam clued me in to a slightly different way of thinking about this problem:
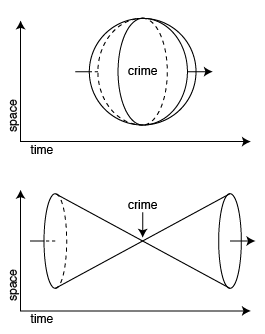
On top is my original, spherical zone of influence. On the bottom is a set of radiating cones suggested by a few of his comments. Each event still has a mass, but in the sense of general relativity rather than campfire ghost stories.
Adam:
Think of the "light cone" of a murder spreading ... it should be additive. Two murders on my block is more than twice as bad as one, because it tips my block into another region of possibility space.
The difference leads to the second picture, where the crime remains a localized event as it happens, but sends ripples through time and space. The forward influence is obvious, the backward influence less so. I think that both directions are necessary for two reasons: just one wouldn't have the interface navigational advantage of seeing around the horizon in each direction, and there are often social preconditions that lead to disturbing events happening in a given place and time. Jane Jacobs likes to talk about "border vacuums" in urban spaces, places such as open plazas that normal people avoid because the emptiness feels intuitively dangerous.
"Violence is a force acting on a place" (Adam again).
Visually, the radiating circles would need to be outlined rather than filled, to suggest the pond ripple connection and minimize clutter. Scrubbing time in one direction or another would expand and contract these ripples, hinting at the direction of their cause. The open question I have is about limits: spheres have an obvious limit, their radius, but cones do not. Do lower-intensity crimes simply have a shorter cone with an identical slope?
The second thing I've been hammering away at is a Flash-based, open source tile display engine for maps or large images. My friend Darren has been plotting a map-based application that would need to run on mobile phones and I want to do sparkly vector graphic overlays, so working with him to target Flash and FlashLite was a no-brainer. Expect to see this sometime in the coming weeks, since we're nearing completion.
Jan 24, 2007 6:36am
spatial vision
I was recently reminded of one of my major "ah ha!" moments from my undergrad years at U.C. Berkeley.
It was in Russell De Valois' class on the biological basis of vision, and concerned Hubel and Wiesel's work on information processing in the visual system. It was one of those end-of-semester lectures where huge chunks of material from previous lessons slide around and sort of lock into place, suddenly making sense as a complete body of work. It was not the other kind of end-of-semester lecture, where animal rights activists pie your professor in class because of his past experimentation on live cats and monkeys.
The majority of the course had focused on how the eye and the primary visual cortex in the brain convert incoming light signals into higher-level information. Not quite recognizing faces or reading letters, but enough to pick out basic visual features such as edges, colors, and movement.
In general, the retina at the back of the eye is spotted with light-sensitive neural cells called rods and cones. Each of these cells is connected to further cells in the eye and later in the brain. Signals from each cell can excite or inhibit the cells that it's connected to: make them fire strongly, or prevent them from doing so. It turns out that simple combinations of cells in groups yield receptive fields (visual patterns) that have a center-surround shape, like this:
The left field responds positively to a bright spot of light surrounded by darkness, while the right field responds positively to a dark spot surrounded by bright light. Importantly, neither field responds much at all to large areas of unvarying brightness or darkness - detection of change turns out to be pretty much the one thing the visual system does, in varying combinations. You can imagine a group of light-sensitive cells feeding a single cell further back in the chain with a combination of positive and negative connections, maximizing the response when the exact center/surround pattern is seen.
These images show typical readings from neurons under various conditions, showing how excited they get when they see the pattern they're sensitive to:

This image shows how massively-redundant and parallel connections between neurons might work to get the results above, driving input from each receptor in the retina to a growing network of visual neurons deeper in the brain:

Hubel and Wiesel's work sticking electrodes into cat brains while they (the cats) looked at moving patterns showed how specialized brain cells in the visual system are. Almost by accident, they discovered that one cell might be responsive to a short, bright horizontal line, while another might prefer a long, dark vertical stripe. Many cells also showed sensitivity to movement. A combination of delayed connections among all those neural pathways might cause a cell to respond just to a bright line moving diagonally up and to the right. The primary visual cortex in the back of your brain is full of such cells, all with a narrowly-defined job to do.
...people often complain that the analysis of every tiny part of our visual field - for all possible orientations and for dark lines, light lines, and edges - must surely require an astronomic number of cells. The answer is yes, certainly. But that fits perfectly, because an astronomic number of cells is just what the cortex has. Today we can say what the cells in this part of the brain are doing, at least in response to many simple, everyday visual stimuli. I suspect that no two striate cortical cells do exactly the same thing, because whenever a microelectrode tip succeeds in recording from two cells at a time, the two show slight differences - in exact receptive field position, directional selectivity, strength of response, or some other attribute.
The bright line drawn around all of this evidence is that this same inhibitory/excitatory structure, made of the same cells with a small variety of connections, can be responsible for a lot of selective patterns besides just dots:
- Spatially, the center-surround fields in the first image see spots.
- Connected in combinations such as long rows or areas, they see lines and edges at various orientations.
- When short delays are introduced, they see movement of spots, lines, and edges in specific directions over time.
- When limited wavelengths are taken into account, they see color in the form of red/green, green/red, yellow/blue, and blue/yellow opposites. Experiments show that people use only limited information from edges and changes to perceive color anyway.
- When signals from each eye are combined, they do basic stereoscopic vision, helping to fuse images into a coherent whole.
De Valois' work tied all of this together, and ultimately showed how all of these neural combinations weren't just detecting simple patterns, but could actually be made to compute Fourier transforms. If the center-surround structure varied in size, it could be interpreted as a spatial frequency detector, rather than just a line or dot detector. All this, in eight or so layers of dense cellular connections. The repetitiveness of neural connections is what makes this possible - calculations performed in a few milliseconds in the brain are much more expensive using computers, which must process pieces of information one at a time, in serial.

{kind=link}
Jan 5, 2007 7:29am
hiding in plain sight
I'm reading Malcolm Gladwell's latest for The New Yorker, and thinking about why visualization, network analysis, data mining, and graph theory are rapidly becoming interesting to a growing number of people right now.
From the article:
Of all the moments in the Enron unravelling, this meeting is surely the strangest. The prosecutor in the Enron case told the jury to send Jeffrey Skilling to prison because Enron had hidden the truth. ... But what truth was Enron hiding here? Everything Weil learned for his Enron expose came from Enron, and when he wanted to confirm his numbers the company's executives got on a plane and sat down with him in a conference room in Dallas. Nixon never went to see Woodward and Bernstein at the Washington Post. He hid in the White House.
In a nutshell, I think this passage captures what's different about corruption now vs. corruption then, which the article refers to as the difference between a puzzle (missing information must be found, e.g. Watergate's Deep Throat) and a mystery, characterized by excessive information and lots of noise. I'm seeing a lot of pushing in this direction from a bunch of smart people: Jeff Heer created Exploring Enron, a visual analysis application for corporate e-mail, while Adrian Holovaty thinks that newspapers need to fundamentally change and better adapt to DBA-thinking.
I think Jeff's more on-target than Adrian, mostly because Jeff is working on the analysis side of things, rather than the data creation side. I don't think the value of a newspaper is in its ability to populate a SQL table of obits or mayoral appearances, especially if the meat of the news is in the margins. Read the article for some finance-geeky details of Enron's accounting showing how hard it is to see a clear picture through the fog of hype, even when all the relevant facts are right there in front of you. The comments on Adrian's post ("microformats!" "semantic web!") reduce reporters to glorified UPS guys, waving their little hand-held journo-data-collectors around instead of asking insightful questions.
Jan 3, 2007 5:46am
oakland crime maps, part II
Last week, I described my first steps towards extracting usable location and crime detail information from Oakland's CrimeWatch II application. I showed how to access maps for specific times, places, and crimes in Oakland, and how to parse those maps for crime icons using simple visual feature extraction.
Since then, I've moved on to extracting more detailed information for those matched crime icons, and roughly geocoding them to within an acceptable distance of their true location. I'll describe more of the process in this post.
Linked downloads:
- Current python client: Crime.tar.gz (40K, requires additional libraries PIL, Numeric, and Twisted)
- SQLite 3 database of Oakland crimes, September through December 2006: crime.db.gz (732K)
My initial image parsing script, scan-image.py, could only extract crime locations from a single map. In order to get a full picture of events throughout the city, I would need to be able to access over a hundred maps for every day: eight city council districts (including Piedmont, where nothing ever happens) and fourteen types of crime ("arson", "alcohol", etc.), so the next step was to construct a client script that would be able manage a large number of map downloads. The first iteration of this client was a simple shell script, which placed JPEG files into a directory. After I ran this a few times, it became obvious that the long response times from the CrimeWatch server (20-40 seconds) were going to make testing tedious.
Instead of spending a lot of idle time waiting for requests to return,
I turned to Twisted Python for
an asynchronous framework that would manage multiple pending requests,
servicing each only as responses became available. I started by making
several modifications to the twisted.web.client.HTTPClientFactory
and twisted.web.client.HTTPPageGetter classes that would support
a persistent cookie jar, to make each request appear to be originating
from a single browser session. New map requests are dispatched every few
seconds, and the JPEG responses inspected immediately upon return.
This first iteration used a single cookie jar, and worked well up to the
map-parsing step.
I quickly discovered that retrieving details about individual crimes was going to require a different approach. The initial map requests result in an image map-like response, and details on individual crimes must be retrieved by clicking on map hot spots:

For each crime detail, a complete round-trip to the server must be made, a new map JPEG must be downloaded (it includes a mark showing the clicked spot), and two separate iframes (the first displays a "loading" message) must be requested to access the table of detailed information. My first attempt to get to these deeper details was done asynchronously, and I quickly noticed that I was seeing incorrect results due to a server-side session model that assumed each browser was accessing a single map at a time.
So, the final downloading agent begins a new session for each map. These are requested in parallel, but the resulting crimes for each are requested in serial, like this:
----+- map A, crime A1, ..., crime An
|
+--- map B, crime B1, ...
|
+----- map C, ...
|
+------- ...
The primary tool that makes this process tolerable is Twisted. It supports an asynchronous programming model that makes it a breeze to set up dozens of simultaneous browser sessions, and spread their requests out over time to avoid overloading the CrimeWatch server. It has been persistent fear of mine that this process would be nipped in the bud as soon as a CrimeWatch admin noticed my relentless pounding of their service from a single IP. That, and getting a knock on the door from the Oakland PD.
Scraping the crime detail table is performed by BeautifulSoup, another Python wonder-tool. This one is a loose HTML parser written by Leonard Richardson, and its handling of badly-mangled, invalid markup is truly heroic. Not everything in CrimeWatch's responses could be parsed out of HTML, unfortunately: several important details, such as the URLs of the iframes above, has to be regexped out of embedded javascript.
The next step in the process is geocoding each crime, assigning it a latitude and longitude based on its map location. CrimeWatch publishes no geographical information beyond the map images themselves, so this part is necessarily an approximation. Fortunately, CrimeWatch also promises that the data is only accurate to within the nearest city block, so the fudge-factor of geocoding events from an image is probably acceptable.
I'm taking advantage of the fact that the City Council District base maps remain static across requests, covering the same area regardless of the crime or time I'm searching for. This allowed me to search for reference points on each map that I could geocode manually. This was probably the most tedious part of the project, because I had to find three widely-spaced, well-rendered reference points for each district map. To find the location of map points, I used Pierre Gorissen's Google Map Lat/Lon Popup, a simple javascript application that places markers on Google Maps and reports their exact latitude and longitude. I chose three widely-spaced reference points for each district, such as these District 3 locations:
- Near Portview Park
Point on map, according to Photoshop: 466, 607
Latitude, longitude, according to Google Maps: 37.805775, -122.342656. - 14th St. & East 20th St.
Point on map: 1861, 862
Latitude, longitude: 37.793211, -122.240968. - Broadway & 51st St.
Point on map: 1719, 132
Latitude, longitude: 37.834429, -122.252373.
Using three such points and the assumption that the map is a linear projection (or close enough), determining the geographical positions of each crime placed on the map is a short bit of algebra. Cassidy tipped me off to the fact that the linear system can be represented by this pair of equations, where x and y are icon points on the map:
latitude = (a1 × x) + (b1 × y) + c1 longitude = (a2 × x) + (b2 × y) + c2
Finding the a1, b1, c1, a2, b2, and c2 is possible by solving the following two systems, based on the three known points:
37.805775 = (a1 × 466) + (b1 × 607) + c1
37.793211 = (a1 × 1861) + (b1 × 862) + c1
37.834429 = (a1 × 1719) + (b1 × 132) + c1
-122.342656 = (a2 × 466) + (b2 × 607) + c2 -122.240968 = (a2 × 1861) + (b2 × 862) + c2 -122.252373 = (a2 × 1719) + (b2 × 132) + c2
This is described and implemented in some detail in the notes for a talk that Darren and I gave at Flash Forward NYC last year, Putting Data on the Map.
Finally, each named, dated, geolocated crime is written to a small database. SQLite has been a major godsend for this purpose, because it requires no configuration and is implemented as a simple library that reads and writes static files.
The end result of this process is a SQLite 3 database file containing crime incidents for all of Oakland from September, October, November, and December of 2006. I did a rough pass (14-day samples, with high risk of overlaps for common offenses, i.e. probably not as accurate as it could be) for those four months just to get the data, and I will be re-examining them in greater detail and retrieving additional data over the course of January.
Jan 2, 2007 7:10pm
digg swarm screens
I've encountered two Digg stories in the past few days that are no more than pointers to interesting views of Swarm:
"Watching the diggs go up and up on Digg.com was insane. I switched to Swarm and this is what it looked like."

"This is what happens when a digger does nothing but digg every new link that pops up."
Jan 2, 2007 4:26am
3000
The New York Times has published 3000 Faces, an interactive infographic of U.S. military casualties in the Iraq War, to-date:
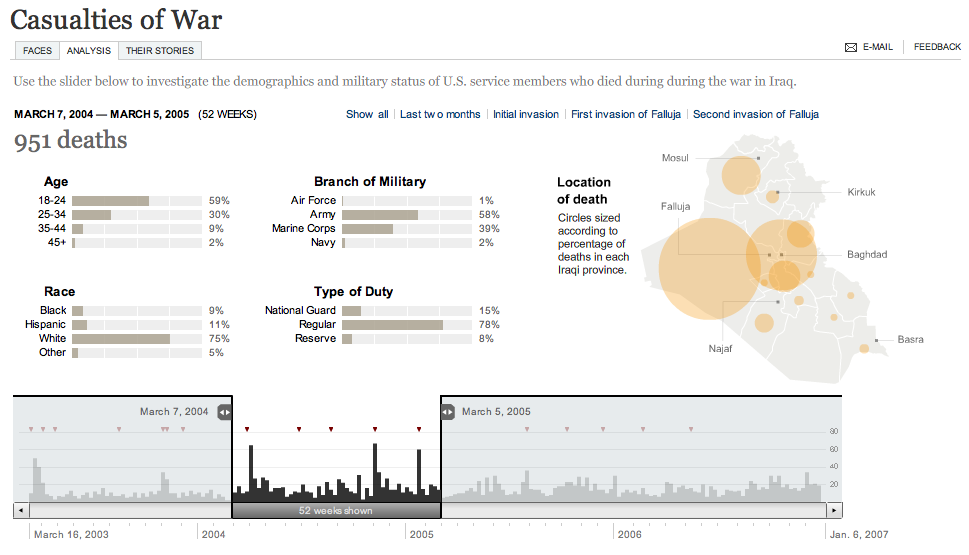
Try the application at nytimes.com.
Casualties are classified according to age, race, service, duty, and time and location of death. The primary control for the graph affords selection of a variably-sized slice in time, for example the 52 weeks I have chosen in the screenshot above, between March 2004 and March 2005. This is the heaviest continuous one-year stretch of the war, encompassing the beginning of the campaign against al-Sadr, the second invasion of Fallujah, and the January 2005 Marine helicopter crash that killed 31.
All aspects of the chart react to the time slider: the date at top changes, breakdown charts in the middle adjust themselves, and location circles in the map on the right scale accordingly.
The time interface serves three functions:
- It's a bar chart displaying the casualties per week over the almost four-year course of the war.
- Small markers at the top note significant events, e.g. "Constitution approved" or "Saddam Hussein captured."
- Input widget, for modifying the remainder of the graph.
The combination of display and interface in the time slider is strongly influenced by Google Finance:

Google Finance's central line graph also serves the same three functions: stock price display, news event markers, and input slider.
The entire casualty analysis application makes liberal use of tooltip-style information displays, which display detailed statistical information above the looser, less-detailed graphics:
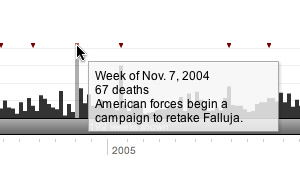
Daniele Galiffa of Mentegrafica compares it to Minard's Napoleon's Retreat chart made famous by years of magazine advertisements for Edward Tufte seminars. He also says that improved understanding would result from additional data-mining features ("what was the worst day for white men?"), but I disagree. The tooltips demonstrate how selective hiding of information helps increase the overall information density of the graph, and the single input mechanism makes it a more accessible browsing tool for historical information. The pertinent information here is event-based, answering questions about the spikes in the chart, and offering direct links to significant points in the upper-right-hand corner. The one significant feature missing is the capacity to bookmark views into the data. Fortunately, there are only two possible variables for each view (start date, end date), but it would be interesting to provide a direct URL to the 52 weeks of heaviest casualties, above. For comparison, Google Finance also offers no way to link to a particular view that I'm aware of. Yahoo's new beta Finance charts do offer the fragment-style direct links first demonstrated by Kevin Lynch (e.g. this view of the same HAL data as the Google screenshot above), at the cost of an otherwise heavily over-featured application.
Martin Wattenberg and Fernanda Viegas's group at IBM is also doing some work in this direction, with their forthcoming Many Eyes project (look for "democratizing visualization" on this page). The two central features of Many Eyes that pique my interest are thumbnails and direct links to application states, simple technical additions that greatly multiply the usefulness of the application as a vehicle for argumentation or simple sharing.
Overall, I think the New York Times application is an example of serious, cutting-edge journalism, offering readers (?) a way to make and test theories about the progress of a long-term event. It's valuable in the same way as the terror alert vs. approval rating chart, and for many of the same reasons. The barrage of noise generated by the 24-hour news cycle is desperately in need of simplifying views that help illustrate co-occurence and possible causality of news events.
In contrast, John Emerson offers his own take on the latest milestone.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski