tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Dec 28, 2005 6:15pm
kittinger
At Hill and Knowlton, we were in the habit of naming our various machines and hosts after satellites. I haven't worked there in over three years, but I've named my new Powerbook Kittinger.
Dec 21, 2005 7:39am
ocean store
OceanStore is neat:
OceanStore is a global persistent data store designed to scale to billions of users. It provides a consistent, highly-available, and durable storage utility atop an infrastructure comprised of untrusted servers. Any computer can join the infrastructure, contributing storage or providing local user access in exchange for economic compensation.
Well, except the economic compensation bit. If well-handled, this idea could take off like its close cousins DNS and Bittorrent. If poorly handled, someone else will do it because it feels like an idea whose time is close at hand. Google's already deployed something like it with Google Base, but they're blindly focused on its utility for "content owners" (They sound like the MPAA jackass on NPR this morning braying about "entertainment product").
OceanStore is touching on the same attitude towards storage I'm seeing in projects such as Atop Axiom, namely a slight distancing from SQL towards purer object stores. This move loses the big advantage of SQL's indexes and searches in favor of distributability and fuzzy degrees of confidence. Your credit card company isn't about to switch (SQL solved their problems neatly almost 30 years ago), but projects like ForwardTrack could play.

Dec 11, 2005 1:15am
pressthink groks bob woodward
In theory we send these people out to report back to us. Some of them penetrate the secret worlds of national security and government policy-making on our behalf. But if they keep going into the secret world they can come under the gravitational pull of another planet--the people in power, the secret-makers themselves. They're still sending back their reports, but have left our universe, so to speak.
It's a fascinating essay about the effects of access on insight. In this case, Bob Woodward comes under heavy scrutiny for his unique combination of top-level access and personal incuriousity. Arianna Huffington calls him "the dumb blonde of American journalism, so awed by his proximity to power that he buys whatever he's being sold." It's easy to forget that Woodward's big break in the Watergate case came at a time he was a lowly Metro desk writer, an unexpected source of pressure.
A few things occured to me as I read this:
- The cyclical (or pendular?) nature of access. Yesterday's outsider is today's insider. Today's bomb-throwing bloggers at the gates of the mass media are going to be tomorrow's establishment commentators. Lee Gomes describes this change in a recent WSJ article.
- The value of independents. Yesterday's announcement of Yahoo!'s purchase of Del.icio.us is a bit of a bummer. It'd be nice to have strong web firms that aren't part of the GYM, but right now everyone's getting bought. Like Bob Woodward's investigative journalism, enclosure within Yahoo! can't possibly be doing much good for anyone connected to Del.icio.us except its employees and investors.
- The value of independence. Keeping out means keeping perspective. How many fantasy & sci-fi stories are based on the premise that power corrupts, and diving too deeply into black magic affects your ability to reason? This is tremendously important (in my industry, anyway) at this moment that all the little guys are either bought, or trying hard to be. I ought to try to keep this in mind as I head for the lions' den this March.
Dec 7, 2005 7:57am
tagging on the rocks?
In How Tagging Could Gain Ground, Philipp Keller laments a lack of "new, visionary, inventive articles on tags."
Keller argues that he's missing a "middle-distance" view of information, somewhere between folksonomic free-for-all of tags and the hieratic temple of DMOZ. His graph puts Google at the far-left, on the assumption that the search engine rewards recognition rather than novelty searches:

I have a few resopnses to this argument:
First, I think the results of Keller's quick survey of Google vs. Del.icio.us (using the search term cryptography) aren't representative. Del's audience skews heavily geekward, so it feels natural that links about math, technology and secrecy would be represented well. Picking another topic out of a hat, the results aren't so clean-cut. Google's results for organic farming lie at about the same level of generality as its results about cryptography. There are a lot of them, many fairly basic. Narrowing searches by adding terms (e.g. politics, how-to) helps squeeze the volume down a bit. Meanwhile, Del returns just 10 links, total. Hope they're good. Conversely, the quality of results for terms like web or blog in Del.icio.us is also generic and fairly undifferentiated. Google maintains a middle-distance from the user in more situations, while Del.icio.us swings wildly based on the composition of its user base.
Second, I'm losing faith in the potential for staying informed from tagged web content alone. I've been subscribed to several Del tag searches via RSS (e.g. attention, maps, infographics), and today I unsubscribed from the last of them. The data was far too general: I was either getting a very slow trickle of information, or a torrent. Attention in particular picked up sharply from fewer than a half-dozen items per day a few months ago, and accounted for a substantial percentage of my RSS volume. Many of these items were repeats or pointers to the Attention gang's own writings. Interesting, but I get this stuff via other channels, and wasn't learning enough new stuff.
Third, I think these two points show that a social bookmarky whatchamacallit like Del.icio.us has a population sweet spot. The quality of the links was highest when the system was populated by hardcore early adopters, and dropped when middle of the bell curve moved in. In particular, the quality drop was characterized by echoes and repetitiveness. I would argue that Folksonomy Helps Me Stay Informed On a Given Topic best when the diversity of a given tag/user/resource population is high and the headcount low.
Fourth, Keller is seriously on-target when he says that the "missing in-between view can be won by analyzing tags" - his love cluster example is like a textbook example of aspects in linguistics, showing the nuances of social meaning in a term as general as love. I expect that Del.icio.us could do something like this too, but the API terms are too limiting for external experimentation, and the math is hairy. If anyone had the gall to do this on a large scale, it'd be Google - they're already treating link text as a de-facto tag on a page, so they're arguably the oldest tagging outfit on the block.
In general, I don't think that tags as a concept are sliding into irrelevance, as Keller seems to suggest. I think the bigger picture is that tags are (currently) one kind of intentional choice that can be expressed digitally. There are other such choices that may aid in search, and I imagine they won't be called "tags". There is also the approaching time when tags stop being reflective of human choices, as automated others-tagged-this-with schemes become prominent, and spammers decide that Del.icio.us Popular is a good place to be.
Dec 1, 2005 2:14am
things fall apart
I've been reading this brilliant essay by Philip K. Dick in small pieces all day: How To Build A Universe That Doesn't Fall Apart Two Days Later. There's a lot of meaty conjecture on the appearance of truth in fiction, and Dick's own run-ins with quasi-religious coincidences arising out of his books Flow My Tears, The Policeman Said and Ubik. It's a lot to digest, so I won't bother interpreting.
Q. What are science fiction writers "good at?"
A. Dick:
I can't claim to be an authority on anything, but I can honestly say that certain matters absolutely fascinate me, and that I write about them all the time. The two basic topics which fascinate me are "What is reality?" and "What constitutes the authentic human being?" Over the twenty-seven years in which I have published novels and stories I have investigated these two interrelated topics over and over again. I consider them important topics. What are we? What is it which surrounds us, that we call the not-me, or the empirical or phenomenal world?
Nov 26, 2005 5:32am
seceding from googlistan
While in Europe, I decided to secede from Google.
I'm starting to get creeped out by the volume of information they're hoarding, influenced by the rhetoric of the AttentionTrust, and doubtful of the longevity of the "Do No Evil" company motto. Someone smarter than I said: "When all the good-guy founders have left the company, Google still has your data."
I thought of a few ways to accomplish this:
- Use robots.txt to disallow Google's search bots. This is the naive approach that relies on search engine trustworthiness.
- Use some variant of khtml2png or ImageMagick to render all text content on my site as GIF text, making it opaque to bots but usable for humans. This is a more difficult approach that will work until the day Google merges their book-scanning project with their search engine.
- Stop blogging.
Ultimately, I decided it was a silly idea. I don't get a ton of search engine traffic (except for "giant ass") and I don't much care. The stuff I write here is public by definition, and HTTP responses aren't an aspect of Google data retention I'm afraid of. What I'm really worried about is the correlation between searches pegged to my browser cookies, mail processed through the GMail account I don't use, instant messages transmitted through the Google Talk account I don't use, and usage information about my website culled from Google Analytics and Google Web Accelerator.
Meanwhile, the proprietor of WebmasterWorld has seceded for real. Black Hat doesn't get it. It sounds to me like Brett is trying a controlled experiment, to see how traffic on the site is affected by dried-up search engine hits. The site in question is a conversation forum, and I can imagine that it would be desirable to exercise some control over the kinds of people walking into your salon. If you want to keep the conversation on the level, you discourage casual participants and bias in favor of dedicated readers and writers. If I were in his position and made this decision, that might be my rationale.
Nov 24, 2005 7:45pm
strange decision from 37S
This is currently old-news, but I'm still playing catch-up after my travels. 37 Signals has disabled comments on their weblog. Can't say I'm their biggest fan, but I always made a point of reading their blog, mostly for the discussion in the comments. I do this with Slashdot, and I'm starting with Digg, too. Sites with vocal and frequent feedback are like the watering holes of the internet, useful more for the other visitors they attract than the inherent local value they provide. Given that 37S had just recently started up their Deck advertising network (...if you want to reach the influencers, buy a card...), I can't understand why they would remove a major traffic driver to their site. Now, there's nothing on the website that's not already in my RSS reader, and the quality of the Signals' own postings have show a marked deterioration lately anyway. I really don't have a reason to swing by anymore, which makes ads purchased in the Deck less valuable. Eric has also noticed that more NYTimes articles are beginning to disappear behind their Times Select "pay wall," another instance of forum owners sabotaging their own relevance.
Nov 22, 2005 3:46am
drang nach oakland
I'm back home in CA.
Last week I had the good luck to attend Design Engaged in Berlin. It was a mind-expansively great time. Thirty-five designers from Europe, Asia and the U.S. converged on Andrew's second micro-conference. I heard so much good stuff about last year's Amsterdam event that I just had to beg or steal my way into this one. The reward was a weekend-long series of talks and directed conversations which covered a much wider range of topics than your typical tech/nerd conference. My own interest was piqued by design for our post-cheap-energy future (Adam read a little Jacobs and Kunstler), exercise machines as a joy (Dance Dance Revolution) instead of a chore (24Hour Fitness), mechanizing thoughtwork, metals which snap into liquid form at low temperatures, and Malcolm McCullough's musings on ambience and uniformity. I don't recall a single official invocation of wiki's, long tails, or anything-onomies (though Thomas was there).
My favorite aspect of the whole affair was the design of the conference itself. Despite an inauspicious beginning with chairs arranged in neat rows, the scheduled 20-minute presentations frequently evolved into conversations once Q and A got started. The conversation-starter sessions were overall the most engaging for me - these were talks on the short side that presented a few themes or arguments (or fun crafts projects) and then yielded the floor to the rest of the group. They had a call and response feel to them that I greatly enjoyed, with just enough structure to keep the thing flowing but not so much that I was ever forced to travel to the laptop-planet for a break. Two participants planned events instead of presenting - Matt designed a button-trading game which won us (Stamen) a Nokia N90, and Mike set up a series of neighborhood walks that bagged us (myself, Gem, Anne, Andrew, Joshua, Liz) a personal tour of Schoenburg from Erik Spiekermann.
I find it interesting that every time I detour to Poland, I fly back with another Norman Davies tome in tow. This time it's Heart Of Europe AND Rising '44, but I've only had time to crack the first. Adam's talk Design For Decline seriously hits home with me, because when I visit Wroclaw (the town, the book) I'm constantly made aware of the fact that 60 years ago the city was a Dante's Inferno of post-war terror. Buildings are riddled with bullet holes. Neighborhoods where family members live were attack vectors of the Red Army. Expelled Germans come back to check out their old homes. For all my good-O'Reillyite optimism about our Google-Wikipedia future, it's only been a few years since the last time Europe convulsed into total war. It's hard to trust in unfettered progress when you're from a country that blinks into and out of existence every few generations.
Nov 6, 2005 2:23pm
polish podcasting
Right now, Polish radio station Tok FM is finishing up an informational broadcast about podcasting and internet radio. It's interesting (to me) that they make an effort to demystify the process - rather than the "for wizards only" take I often hear in American descriptions, they're getting into specific technologies, advantages and drawbacks of various streaming and distribution methods. I think it may be a result of all the English terms ("podcast", "stream") and the need to explain them without relying on existing metaphors.
Neat.
Nov 6, 2005 12:41am
less is crap
What's with the glorified self-balkanization of software?
I'm in Poland, running through my feeds for the first time in a week. Half the stuff I'm reading from Paul Graham, 37 Signals and a million others is undigested "less is more" zen-of-development hoo-hah. It may just be that I'm tired and jetlagged and supposed to be sleeping, but this stuff is majorly rubbing me the wrong way. It's like job #1 for all these guys is gleefully cutting down their workload by proclaiming philosophical opposition to planning, preparation, or listening to their users. I realize this is a great way to get a wee startup out the door, but the approach has no apparent respect for software with more than ten users and developers. Some jobs, like disaster relief or administering a country or designing a car are big by nature. I'll never forget our two visits to BMW's design & engineering center in 2004 and 2003, when I witnessed for the first time a large, highly synchronized operation manned by hyper-competent individuals acting synchronously towards a central goal. It was poetry in motion, a sad counterpoint to the incompetent bumblefuckery of FEMA and other federal agencies botching wars and rescues.
The real problems of the 21st century are worlds-apart from the American business press' sudden obsession with autonomous smallness, agile and open source software. I'm curious to see the focus of small, distributed teams pointed at big problems with inherently big solutions.
Nov 1, 2005 5:59pm
arrrrgh, firefox (redux)
A few weeks ago, I decided to take the Attention Trust Recorder for a spin. The extension only works in Firefox, so I changed over from my beloved Safari for almost two weeks.
I had a few complaints about the switch from the start, some of which haven't haven't faded wih time.
- I'm less flummoxed by Firefox's tab-switching keyboard shortcut. After a few days, I grew accustomed to the control-tab combination, though I still find it somewhat uncomfortable. It's definitely no longer alien to me.
- I stopped noticing the Keychain lack after a few days of being bothered for passwords I couldn't remember. Fortunately, I use the same username/password combo for my unimportant accounts (newpaper logins, etc.) and Keychain provides a way to read my stored passwords. It would be better to keep these all in the system-level store (what do I do next time I switch browsers?), but for now it's fine.
- I sort-of dealt with the stable browsing history issue by adding cache persistence headers to Reblog's output. Unfortunately, this causes the browser to fetch pages from disk instead of network, but makes no difference to the browser scripting engine's lack of stored state. I've seen a number of people write javascript libraries for storing Ajax state - I thought this was a ridiculous idea until I saw that Firefox made it necessary to engage in such repulsive hacks.
- General "macness" is still a problem. Firefox feels like it's been brainlessly ported from Win/Linux land. Camino has more promise in this area, but I doubt it can use the same extensions that Firefox can. Meanwhile, a new annoyance crept up in Firefox focus handling: certain actions caused my browser to lose focus on elements or windows, especially when I did anything with tabs. I have't been able to discern a reproducible pattern, but I've started to develop a sixth sense around the browser quirks. I find myself engaging in technological coping behaviors, which helps the symptom but really shouldn't be necessary in the first place. Boo, Firefox.
Meanwhile, Ed from Attention Trust wrote a short post basically agreeing with my frustrations, so maybe we'll see a Safari version of the recorder. My personal preference would be to skip the browser consideration entirely, and write a local HTTP proxy that's browser-agnostic.
Back to Safari!
Oct 31, 2005 11:52pm
boom-boom-boom
Eric:
We're quietly sitting in the office, and hear a BOOM, which is not that big a deal in the sunny Mission. Then another, and then another, and then another, in rapid succession, followed by sirens and helicopters and then more BOOM BOOM BOOM, and finally we turn down the techno and Mike says to me "um... do you think we should go take a look?" We head to the roof and it's not quite the giant robot stomping on buildings that we had imagined, but pretty close - smoke belching from a building on South Van Ness & 16th (about two blocks away) & periodic BOOM BOOM BOOM accompanied by huge balls of flame.

Oct 31, 2005 1:50am
rassafrassin'
Totally forgot to catch Burtynsky when his photographs were shown at Stanford, and again at 49 Geary.
Oct 28, 2005 4:45pm
mixing metaphors
There's a spirited debate winding down at 37 Signals about Flickr and user-generated content. A lot of the comments seem to be dangerously mixing metaphors and points of view to obscure the non-issue at hand.
Jason: "Now, hundreds of thousands of people are taking photos, uploading them to a site like Flickr, making Flickr better, and Yahoo is reaping the financial rewards, not the photographers. That's a pretty big shift. Yahoo is making money off the backs of the collective camera."
Jason, contradicting himself: "I'm not saying there's anything wrong. I'm just saying the whole user-generated content model is an interesting one one where the public does the work and the company gets the financial reward."
The Marxist revolutionary tone sure makes it sound like something is wrong, no? Content-uploaders of the world, you have nothing to lose but your chains.
Steve, contradicting Jason: "What Flickr (and others) have done is shown that photographs are cheap. They're not paying you because if you left, there'd still be thousands of other people who are willing to send in free photographs."
Benvolio, later: "Jason is hinting at a new business model. something like: users sign up to flickr, flickr makes cash from ads hosted on said users images, flickr gives a cut (between 1-10%) of the cash from these ads to that user. not only is this sharing the love but it provides an incentive to flickr users to create, load and promote great content."
Cripes.
I'm seeing a few problematic metaphors in this thread:
- Money is love.
- Photos are content.
- Flickr is a community.
Jason's position in this debate basically boils down to: "Flickr should pay their users for their participation, so users will have a greater incentive to upload quality photos. Uploading quality photos imroves Flickr, which translates into higher advertising revenue for Flickr and Yahoo." Terms like "better" and "share the love" are applied to ad revenue and micropayments, which strikes me as innappropriate.
I believe that Flickr has been successful because of the simplicity of their idea: provide quality plumbing for sharing photographs, in return for non-intrusive advertising or old-economy money. No new-new-economy language about content, community or peer-production, just sharing photos with your friends. The specificity here is important, and Flickr has always seemed to avoid describing their service as a marketplace, a platform, or a community. Of course it is all those things (and many more), but I suspect that is so because their eye rarely strays from the ball. The fundamental reason people join is to share photograhs, while everything else is a nice bonus. Steve (above) is right - there are thousands of people sending in photographs, but they aren't sending them "to Flickr", they're sharing them with their friends. Photographers who want some scratch for their work sell to Corbis or arrange for licensing on other channels.
The last thing Flickr users need is an incentive to upload - a year's worth of frequent massages proves it. People don't need to be convinced to act socially, all they need is a supportive and malleable environment to act in. Flickr can ignore that at their peril.
Oct 26, 2005 6:33pm
keeping change
There's a connection between BofA's Keep The Change program and the Attention Recorder, but at the moment I can't articulate it.
Oct 26, 2005 4:30pm
reblog 2.0
Reblog's 1.0 announcement promised "push-button republishing for the masses", and we've been doing pretty well following that track for the past year or so. Last night, we pushed the button on Reblog 2.0. The concept behind the software has always been a form of attention cagefight: many feeds go in, one feed comes out. Reblog closes the loop between piqued interest and publishing by making the act of marking a link for publication a one-step affair. We've long thought this was a pretty interesting addition to the standard functionality of an RSS reader, and I'm surprised to see that in late 2005, there's not a lot of other software that performs the same task.
In the meantime, Reblog has started to see slow but steady growth. Eyebeam and Rhizome both use the software to publish net art blogs, and Eyebeam has an explicit "curator" role in the fortnightly reblogger. Global Voices Online has expressed strong interest in adapting the project to their multitiered reblogging operation, and Reblg from Broadband Mechanics borrowed the term for a similar idea based on microformat republishing from within the browser. A lot of these uses place Reblog in the role of plumbing: like the mixer in your shower, it's there behind the wall but you never see it. Reblog's output is typically meant to be fed into a MoveableType or WordPress plugin, where it surfaces as a series of blog posts on an HTML site annoted with "Originally by so-and-so from..." attribution notes.
We've been thinking a bunch about expanding this role a bit, so that the RSS output from Reblog carries more weight. What happens when you chain a bunch of Reblog installations together, so that the output of one person's attention stream becomes fodder for the next? You get an omnidirectional passive e-mail substitute, great for washes of "FYI" type information and general interest sharing. In a lot of use cases there's no reason for the output to ever make it to a regular blog. Small, distributed groups can use the software to share information among themselves, and only escalate to the relatively disruptive e-mail level when action or response is required. Alternatively, chaining feeds together could result in a progressive-filtering mechanism, reducing the complexity of a thousand feeds into a few pertinent pieces of information through a pyramid of editors.
So, with the interest of making Reblog a more flexible sharing tool, we worked on version 2.0 with a few broad goals in mind:
- Usability: Reblog's user interface needed to help the end-user manage large numbers of feeds more effectively. Tagging feeds & entries has proven to be the most flexible way to accomplish this. We were also interested in ways of making the interface look less... dorky. There was a lot of techno-cruft that just had to go.
- Extensible Input via a public API: Greasemonkey is pretty damn cool, so we thought it'd be useful to provide for a way to perform common Reblog editing actions via a programmable API. XML is boring to parse, so Reblog now has a JSON-RPC API exposed.
- Extensible Output via support for plug-ins: We were strongly interested in seeing some sort of plug-in ecosystem evolve around Reblog. If the software's useful, it makes sense to provide for a way to adapt it to specific uses. My own guide for this has been Blosxom, a simple blog engine written in Perl.
One huge change that became apparent as we wrote 2.0 was the need to post your own entries, independent of any particular feed. Historically, Reblog 1.x assumes that the target blog would be used for this purpose. In 2.0 we've added a "post item" feature, which acts as stripped-down Blogger or Del.icio.us analogue, and handles one of the primary uses cases suggested by Reblg. This idea has been gaining some traction recently, most conspicuously in Mark Pilgrim's microformat atom store concept. Mark decribes the idea as "having your own private database", but my own takeaway from Del.icio.us has been the value of making such micro-information public. Reblog is built to share. Bud Gibson has been referring to this idea as the xFolk Veg-o-matic, a slice & dice greasemonkey-based browser augmentation that trawls websites for microformatted links and posts them into Reblog for you.
We believe this is pretty cool.
Oct 25, 2005 3:58pm
social vulnerabilities
The always-interesting SEO black hat writes:
There are so many vulnerabilities in Media 2.0 applications that our heads are spinning trying to decide the best 10 to exploit. The problem? People are not designing systems with the black hat / spammer in mind. Its like setting a democracy and saying vote as often as you like. WTF do you think is going to happen? ... We in the BlackHat community often throttle how abusive we are on certain exploits. Part of the min/max game is knowing how hard you can ride an exploit before you break the underlying application. (Word Inventor Mark Cuban on Splogbombs)
Oct 24, 2005 8:56pm
dumb 2.0
Here we go again:
...a new startup called Go BIG Network wants to one-up LinkedIn by focusing on transactions over a network, rather than the network itself. ... The service helps entrepreneurs broadcast needs across their personal networks for free, and across the whole network for a fee (yet to be implemented). (Linking Startups to VC, Red Herring)
This idea didn't work when it was called Vencast, and it's probably not going to work now. Social networks (the meatspace kind) and recommendations work because they're personal, out-of-band, serendipetous. Formalizing such connections into a "Craigslist for businesses" will hit the wall hard. The kinds of people who have good ideas and the smart people who recognize them keep a step ahead of this sort of factory commoditization of the creative process. Last time around, the appearance of such "marketplace" meta-companies was a sign of the impending crash - what does it mean in 2005, when the declaration of Bubble 2.0 is only a month old?
UPDATE: Vencast was not the first: "By compressing the time frame of the typical VC-entrepreneur dance, VC.COM reduces the lamb-to-slaughter cycle to days rather than months."
Oct 24, 2005 4:18pm
"zak001"
My brother's first published article was just posted at Palantir. If you are interested in painting Haradrim, read on.

Oct 22, 2005 6:42pm
irony defined
I keep finding links to Meet The Life Hackers, a New York Times article about attention and interruption, but I can't seem to scrounge up ten minutes to read the damn thing.
Oct 21, 2005 6:26am
arrrrgh, firefox
I'm taking a week to test Attention Trust's extension with a vanilla (for now) installation of their toolkit. I'm excited - the idea of recording a live stream of all my browsing activities to a location I control is super interesting.
So far, so good - all of my "clicks" are being recorded along with HTTP response code and cookie status (not cookie content). I'm using the default ACME-style display to show my browsing behavior, but it's going to be time to modify it to show some difference between recent activity and overall activity. The extension logs all "normal" website visits. It skips subrequests such as XHR, images or stylesheets, and I had to dig around a little to figure out why I wasn't seeing logs of my secure browsing activity - these are disabled by default.
The extension only works in Firefox, and an Internet Explorer version is planned, with no announced release date. I can't possibly recommend a Safari version strongly enough. I've had to switch to Firefox for the duration of my experiment, and I'm really homesick.
A few things that Safari does well, which Firefox does not:
- Comfortable between-tab navigation keyboard shortcuts. Firefox has chosen a finger-bending combo of ctrl-shift-tab.
- Keychain integration - I'm not interested in Mozilla's password storage ghetto, I want to use the system-wide one that already has all of my passwords stored.
- Stable browsing history - when I use Reblog to read my feeds (all day, every day) I like being able to return to the feeds view in Safari without a required page reload. Firefox hits the server every time, which takes time and loses my keyboard-controlled focal spot on the list. This may just be a matter of hacking out some more informative cache-control headers in Reblog.
- General "Macness" - Firefox looks out-of-place, with its own non-Aqua button designs and interface elements, presumably intended to minimize differences between Mac, Linux and PC implementations. Fuck that.
I'll return to these four gripes as the week progresses - some of them may be simple acclimation issues. For now, I'm continuing to give Firefox a try because the attention recorder is the first strong reason I've had to do so.
Oct 15, 2005 7:01pm
painting videos
Duane Kaiser of A Painging A Day has complete videos showing the making of several paintings available on his site.
I wrote a little about time-lapse views of art production last month.
Oct 14, 2005 7:41pm
radii are beatiful
I find these images both significantly more pleasing than splines:

The diagrams in The Shape of Song display musical form as a sequence of translucent arches. (Martin Wattenberg, The Shape Of Song)

Flight density during one week between international airports. Herdeg, Walter. Graphis Diagrams. 4th Expanded ed. Zurich, Switzerland: Graphics Press Corp., 1981. (Visual Complexity)
Oct 14, 2005 12:14am
ends vs. means
From a comment on The Decembrist (scroll down):
Mature people who actually care about the world don't ponder the question "do the ends justify the means," because they know that there IS no end.
Oct 13, 2005 11:49pm
e-mail 2.0
According to Tim O'Reilly, Web 2.0 is about collaboration, data control, participation: warm and fuzzy up-with-people sentiments. I think E-Mail 2.0 will be very different: automation, delegation and other efficiency-oriented goals.
If GTD is any indication, I bet e-mail is about to see an automation renaissance. I've experimented with mail client customization before, and this week I've set up a toy system to experiment with transposing certain GTD ideas (trusted system, ticklers) into automated e-mail actions. My memory for responsibilities and appointments is notoriously awful, and I've not had the best luck with personal-organization tricks such as the hipster PDA - turns out they require a minimum amount of self-discipline.
I want to be able to completely forget about my responsibilities until a specific time in the future when they become important, so I'm playing with the idea of automated e-mail assistants. I've set up remind@teczno.com as a time-delay mail helper. Any message sent to that address is checked for a date and time on the first line - I use PHP's strtotime() function, and it happily accepts inputs such as "tomorrow 1pm" or "november 1 8:00am" (note that this only works as-expected in the U.S. Pacific time zone). A response is immediately dipatched to the sender, with a promise to send a reminder at the specified time in the future. When that time arrives, the original mail is returned.
Combined with the conversations hack, my mail client is starting to take on the character of a diligent yet stupid personal assistant. I've become more confident in my forgetfulness, now that I know I can remind "future mike" of his responsibilies. The reminders take on the context of their sender, so requests from my mobile phone return to my phone. The script is CC:-aware, so any addresses included in the CC: field are in on the reminder. I can imagine expanding this system to be secretly social - there are other needs suitable for mail that could benefit from delegation. For example, GTD relies on "projects" being decomposed into "next actions", which is significantly difficult. A decompose-bot could accept mails with to-do items in the body, and delegate them anonymously to other system users for decomposition into discrete actions. Users of the system would periodically receive mails asking them to decompose someone else's projects into actions, spreading the difficulty of introspection out to disinterested strangers. It's tit-for-tat meets Bittorrent meets porn-incentives for CAPTCHA-cracking.
Until then, feel free to try out Remind-O-Bot. Remember:
- Date and time on the first line of the message
- Sender gets the reminder
- CC: anyone else you may wish to pester
Oct 12, 2005 2:57pm
microsoft's RSS icon
Microsoft is trying to figure out how to represent RSS with an icon.
Their criteria for success are:
- Convey newness, activity, subscription, continuity
- Build on the orange rectangle
- Avoid text
I'm just surprised that they managed to fit a new economy swoosh into the mix:
![]()
Oct 10, 2005 4:25pm
the uncool classes
via Kottke:
From London and Berlin to Sydney and San Francisco, civic authorities agree that the key to urban prosperity is appealing to the "hipster set" of gays, twentysomethings and young creatives. But the only evidence for this idea comes from the dot-com boom of the late 1990sand that time is over.
... the lure of "coolness" leads cities to ignore the fundamental issues - infrastructure, middle-class flight, terrorism - that have so much more to do with their long-term prospects. Cities once boasted of their thriving middle-class neighbourhoods, churches, warehouses, factories and high-rise office towers. Today they set their value by their inventory of jazz clubs, gay bars, art museums, luxury hotels and condos.
(Uncool Cities, by Joel Kotkin)
I'm finally reading Jane Jacobs and this article resonated strongly with me. A few other data points:
- San Francisco mayor Gavin Newsom has warned that recovery from a major earthquake may be more difficult, because most of SF's firefighters live outside city limits, many of them across the still-vulnerable Bay Bridge.
- While walking with Eric near 20th and Guerrero, I was surprised to see a cobbler's shop in a neighborhood otherwise full of boho coffee shops and gourmet groceries. I was subsequently surprised by my surprise, because such businesses ought to be plentiful in a well-populated neighborhood, and the lack made me wonder where the locals actually go to take care of such everyday errands as fixing shoes. The cobbler's storefront wasn't exactly booming.
- Still-devastated holes in the ground on the sites of buildings razed to make room for office space at the tail end of Bubble 1.0. Development in the Bay Area seems to occur at the block level, rather than the building level. I was happy to see an apartment building in Berkeley this weekend that had been injected into an oddly-shaped lot, but the general pattern I see in SF and Oakland is for a developer to buy an entire city block, knock down existing business, and put in a "mixed-use" monster.
Oct 9, 2005 3:24am
Noguchi Filing System
Found today via Vox:
A book I read recently has prompted me to try a rather unconventional filing system, the system proposed and used by Noguchi Yukio, an economist and writer of bestselling books about such things. Implementation of the system requires the user to discard many conventional notions about how to store paper documents. (The Noguchi Filing System)
The basic method is to stick your papers to be filed into letter-size envelopes, and store them vertically in order of filing. Any pair of items on the filing shelf will always be in newest-on-the-left order:

A detail that escaped me at first was that folders removed from the shelf don't go back where they came from, but back to the beginning. I'd like to say that I should give this a try, but I've already been beta-testing a spatially enhanced version for most of my adult life: any mail, papers, or books that I wish to file get put down right where I'm standing. Spatial memory is preserved through location, and temporal cues build up over time in the form of stacks of paper and envelopes and crap. My dad uses a limited spatial version, based on the surface area of the kitchen table. It's augmented with a primitive sort of "wiki", in the form of doodles, notes and sketches on most of the white envelopes.
Kidding aside, I like the temporal memory aspect. It's worth noting that an early decision I made with Vox was to organize by first-appearance from the left. Old stuff hovers on the left, new things fly in from the right. When the project was looking at Google News, this choice was strongly accentuated for the longstanding big names such as Powell, Bush, or Blair.
I also like the no-brain feature. "Filing" is divorced from all categorization costs, simpler even than the free associations of tagging. This could probably work very well for small-to-medium organizational needs, but would grow maddening above a certain point. I can imagine that the system would work optimally with a very small set of predefined categories implemented as separate shelves, though all of this raises the question: how to implement something like this for digital files?
Oct 8, 2005 1:17am
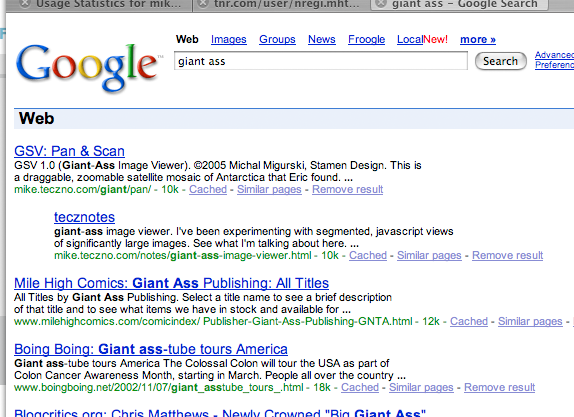
"giant ass"
In lieu of anything interesting to say, I will point out that "giant ass" continues to be a top search term in my website logs.
And, I've just discovered that I am also the #1 Google result for this illustrious word pairing:
Oct 5, 2005 3:21pm
out of context
Mr. Vander Wal met Mr. Migurski in person that month in San Francisco. "It's difficult to explain to my wife what I'm doing, who these people are or how I've met them," he said.
Oct 2, 2005 6:38pm
what's not web 2.0
37 Signals posts "What isn't Web 2.0?" Secrecy and buzzwords among other things.
you could have skipped the filppant list and just said that web 2.0 is a stake in the ground of developing the semantic web.
...which got some rude "buzzword-bingo" retorts. But I like this idea, so here's part of my response:
It's easy to forget that so-called buzzwords ("collaborative", "transparent") have a history - they *mean* something, even if that meaning tends to be obscured over time by thoughtless use. ...the absence of VC funding, secrets, hiring binges and economic incentives were preconditions responsible for the truly transparent & collaborative development surge that got us where we are now.
Sep 30, 2005 4:44pm
corpse bride
I love reading sentences like this in articles about movies:
For Corpse Bride, data wrangler/computer programmer Martin Pengelly-Phillips wrote a utility in Python computer language to convert the XML data into a flattened reel. The shots get validated for naming and length, and checked against the list of known shots in the editorial database in FileMaker Pro. In Python, a series of AppleScripts are created to update the editorial database with the most recent cut.
Sep 20, 2005 4:02pm
72hours tagged navigation
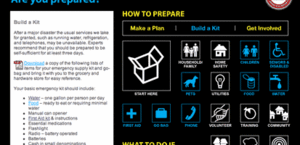
I'm putting together some emergency kits for when the big earthquake hits and FEMA takes a week to get north of Fremont. I noticed that San Francisco's 72 Hours site has a really interesting tagged navigation concept.

The site plan is broken up along two major axes: task-centered overviews across the top (Make a Plan, Build a Kit), and topic-centered details below. Each task page (shown here) is tagged with the topics it touches, for example Build a Kit highlights the Pets, Food, Water, First Aid and others. This gives a helpful, quick point of entry into the first-level goals that need to be accomplished and uses active verbs to do so.
These quick entry points are augmented by details within each topic page, which provide extra information not covered by the quick-start pages.
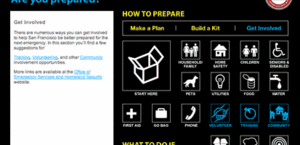
The whole sites uses guessable, crawlable URL's, e.g. "pets.html". There's no side navigation bar, and it's beautifully focused on the goal. Even site name serves as a helpful reminder of the amount of time you should be prepared to live on your own, and frames all the advice within.
Sep 14, 2005 3:33pm
bureaucracy = death?
I just sent this to Seth Godin, in response to Bureaucracy = Death:
An interesting counterpoint comes from Bruce Schneier, regarding the security lessons of Katrina: "Redundancy, and to a lesser extent, inefficiency, are good for security. Efficiency is brittle. Redundancy results in less-brittle systems, and provides defense in depth. We need multiple organizations with overlapping capabilities, all helping in their own way..." (Security Lessons of the Response to Hurricane Katrina).
I've been thinking a lot about bureaucratic efficiency in Katrina's wake, and about the different kinds of organizational efficiency. The Grover Norquist / Newt Gingrich calls against government bloat seemed to be well-intentioned, but it's clear from the Department of Homeland Security that the current Admin is looking for top-down efficiency, initiated by fiat and ruthlessly optimized. This seems to have resulted in the kind of brittleness that Bruce talks about, and was predicted by people familiar with distributed networks of any kind.
What would happen if there were a CNO at FEMA? He'd probably be somebody's fuckwit college roommate appointed from the GOP fundraising talent pool, that's what. Brittle.
I've been thinking that a better sort of efficiency is bottom-up, the kind of deep competence practiced by educated, informed people doing their jobs well. You still have a bureaucracy, but with a culture of basic competence that encourages and promotes efficiency at the lowest levels of the ladder. Turns out this is a lot harder to implement, because the solution starts at the K-12 level and moves from there. Progress is measured in decades, not political terms. If there is any lesson from computer science that I wish society could understand, it's this small-pieces-loosely joined design philosophy that makes the Internet work and Unix a stable operating system.
Sep 12, 2005 9:30pm
goodbye, flickr
I decided to delete my Flickr account today. I hadn't uploaded an image in a month or two, and my only exposure to the site was through various RSS feeds. It felt strangely satisfying to hit the big delete button without backing up or otherwise saving photos.
Sep 8, 2005 8:20pm
coast to coast
I'd like to see Maciej's paintings animated through the production process, but instead I will look at the front pages of the San Francisco Chronicle and The New York Times:
Sep 5, 2005 4:28pm
two things before I bail
1. I understand podcasting now
Still haven't successfully listened to a single talkie-podcast, except for one Adam Bosworth talk from IT Conversations where he referred to "this chart" at point and I threw up my hands & turned it off.
But Ryan pointed out DnB Sets, which offers a podcast of drum & bass and breaks sets, most an hour or more in length. This is a really great way to get music! iTunes handles all the details, and every morning I get two or three hours of fresh music to listen to and throw away when I'm done.
2. WTF happened to George Bush?
I'm not a fan of the President, but I thought his general reaction to 2001-09-11 was pretty admirable. Within a day he was front & center acting like he was in control, and imparting a general sense of getting-shit-done. Guiliani helped, too. I understand about photo-ops and PR, but putting on appearances is important.
This week, we have a mealy-mouthed dingbat flying around in his little airplane, listing how many buckets of ice are going to be sent to NOLA and staging absurdist theatrical on-camera "briefings" with the head of FEMA to reiterate the obvious. We know the situation is heart-rendingly fucked - get into that helicopter behind you and go do something about it!
Observe:


"I can see my house from here!"
Aug 31, 2005 6:25pm
two reblogs in the wild
Mike Frumin brought these two sports-focused Reblogs to my attention this morning:
- Sunday Story: NFL news, injury reports, rumors, fantasy football cheat sheets, player rankings and more.
- Hoop Log: Basketball news, with all posts categorized by team and player. Very well-designed, nice orange date slugs.
Both sites are maintained by Kyle Bunch.
Aug 28, 2005 2:16am
freedom and discipline
Sorry for the recent interlude of radio silence, but many interesting developments in Stamenland have conspired to fill my time with meetings, phone calls, conversations and plans instead of the usual aimless hackery.
William Blaze just released an essay on Web 2.0, with a few choice observations on web-enabled API's and other hot topics. Some selected excerpts:
...the web is different now, but the big differences aren't necessarily found in those prosaic "information wants to be free" ideals, which actually stand as one of the biggest constants in web evolution.
...
What really separates the "Web 2.0" from the "web" is the professionalism, the striation between the insiders and the users. When the web first started any motivated individual with an internet connection could join in the building. HTML took an hour or two to learn, and anyone could build. In the Web 2.0 they don't talk about anyone building sites, they talk about anyone publishing content. What's left unsaid is that when doing so they'll probably be using someone else's software.
As a tool-builder, I'm somewhat biased towards the idea that good software leads to good publishing. In the beginning, it didn't really matter how you published content. Webzine '98 lists the minimal entry requirements: a computer with internet access, a text editor, and ftp program, and something to say.
This core is no less valid today than it was seven years ago, when I picked up the essay linked above on a printed flyer at 3am in a National Guard armory in Santa Rosa, CA (don't ask). What's changed is that a lot of people have gotten the message, and suddenly the phenomenal rate of growth in blogs has made every individual voice just a tiny bit quieter. Your options as an opinionated online-writing-guy are to accept that on the Internet, "everyone is famous for fifteen people", or to start paying attention to how you say what you need to say.
Enter RSS, XML, API's. William:
Any user of a public API runs the risk of entering a rather catch-22 position. The more useful the API is, the more dependent the user becomes on the APIs creator. In the case of Ebay sellers or Amazon affiliates this is often a mutually beneficial relationship, but also inherently unbalanced. The API user holds a position somewhat akin to a minor league baseball team or McDonald's franchisee, they are given the tools to run a successful operation, but are always beholden to the decisions of the parent organization. You can make a lot of money in one of those businesses, but you can't change the formula of the "beef" and you always run the risk of having your best prospects snatched away from you.
...
The real hook to the freedoms promised by the Web 2.0 disciples is that it requires nearly religious application of open standards (when of course it doesn't involve using a "public" API). The open standard is the control that enables the relinquishing of control. Data is not meant to circulate freely, its meant to circulate freely via the methods proscribed via an open standard.
In other words, there's a strong relationship between freedom and discipline. Freedom without discipline becomes the freedom to not reach our goals. Discipline is standards literacy. Literacy in the common culture and an ability to navigate it is a pre-requisite for effective communication, a point made by E.D. Hirsch in his work on Cultural Literacy. Hirsch's point about the communicative freedom gained by anticipating the cultural standards of your audience is directly applicable to the read/write web, where publishing your information under a technical format such as RSS and a legal format such as a Creative Commons license means that your work can fly faster, further, and affect a broader audience. This is a higher freedom afforded by self-discipline.
Blaze's paragraph on the risks of public API's can be understood as a criticism of cultural domination. In some cases, this domination is probably not something that can be overcome: Flickr's API grants access solely to data that users have chosen to host on Flickr. EBay's data is specific to the marketplace run by EBay. A more interesting example might come from information that is public domain, such as the Library of Congress' categorization of printed works, or the dense network of facts kept by Wikipedia. I can't speak for the former, but the latter information is made explicitly free under the GNU Free Documentation License. 3rd parties can and do duplicate the Wikipedia database for their own purposes, and Wikipedia ensures that this information is available in a coherent form (SQL database dumps) under a permissive license.
The benefits gained from a higher degree of web 2.0 professionalism are enormous, and they don't invalidate the easy-on promises of 1998.
Aug 16, 2005 5:25am
del.icio.us user flocks
This is kind of neat:

Late last night, Slashdot linked to a Site Pro News article about 10 good CSS resources. Today, the article and its contents (WPDFD, Glish, the offical spec and others) absolutely freaking dominate Del.icio.us Popular, as seen in Vox Delicii, above. (If you're reading this more than a few days after I posted it, hit "Back one week/day" a few times after the jump)
When I first posted Vox, I expected to see users "flock to stories linked from Slashdot or BoingBoing", but not swings as wild as this. Aside from the Slashdot effect, is there something more going on here, like a Del.icio.us Popular feedback effect? I certainly don't think it's a Vox feedback effect; here's the traffic stats since it was launched:
So here are two questions I would like to have answered, after some more data builds up:
- Is there a pattern to the kinds of sites that get the heaviest traffic? If they tend to be list or surveys, it might indicate that Del is being used as a meta-bookmarking service, and that highly-popular bookmarks are themselves pointers to the real content. Here, there seems to be a halo effect, from the Site Pro News to the linked sites, each of which has individually been around for ages.
- Where do the links come from? There are a few URL tastemakers such as Slashdot, BoingBoing, Waxy, or Kottke. but then there are these guys ("Del.icio.us users who bookmark helpful/timely URLs"), none of whose usernames I recognize. Are they top users because they are quick on the draw, or because other users look to them for interesting places?
Aug 14, 2005 12:17am
music industry worried about everything
music industry are big-time weenies.
News for music industry: nobody likes a whiner. Stop complaining and do something interesting so Apple stops eating your lunch.
Aug 11, 2005 4:35am
second-person shooter
Julian Oliver is investigating the second-person shooter format, what it might look and play like. In this take on the 2nd Person Perspective, you control yourself through the eyes of the bot, but you do not control the bot. Your eyes have effectively been switched. Naturally this makes action difficult when you aren't within the bot's field of view; thus both you and the bot (or other player) will need to work together, to destroy each other.
This reminds me of my senior year at UC Berkeley, perfecting my game of multiplayer deathmatch GoldenEye. This was one of the few games I had seen at that time which allowed simultaneous split-screen competitive play, and the secret to getting really good was to stop watching your own screen, and watch the other three. It really did start to seem like a second-person shooter after a while, when tense standoffs were resolved by carefully watching what the other players could see, and reacting accordingly.
The other split-screen game we liked was Mario Kart, where viewing the other screens didn't help quite so much.
Aug 10, 2005 6:20pm
vox delicii attention
Vox (announcement) has gotten a bit of very-appreciated attention since I posted it last week:
- Jim Downing, Smart Mobs
- Information Aesthetics
- About.com Web Search Blog Site of the Day
- Social Software Weblog
- Waxy Links
- Yahtzeen8.0
It's interested to note the difference in reactions between this version and the older In The News site. Is Del.icio.us Popular really a more interesting data set to graph than Google News?
Aug 10, 2005 6:20pm
rediscovering america
Three recent accusations of recognition masquerading as discovery:
- "Funny, but while reading the article my brain made several twitches. It's not so much that I disagree with the sentinence of the article (focusing on activites as compared to, uh, other human aspects, such as colors, shapes and taste, maybe), but I really disagree with the problem specified above; what the hell is the difference between designing for some users compared to all users? They are still both user-centred design!" (Alexander Johannesen on Don Norman)
- "I'm more troubled by the 'Get Real' philosophy. Not that it is in itself wrong, but I can see the horde of inexperienced managers and sloppy programmers who use this kind of rationale as an excuse for poor planning and bad execution." (Cedric, commenting on 9Rules in response to 37signals)
- "First we have to set aside the fact that Clay is now talking about free-text search, and not tagging. But, let's say he is talking about tagging. The system he's discussing already exists. It's called "postcoordinate indexing," and I mentioned it in a prior folksonomy post of mine. I guess that's another thing that's really bugging me. Clay acting as if he's discovered unchartered territory, when, really, it's been well-trod upon for awhile." (Peter Merholz on Clay Shirky)
I think what's happening is that all the accused parties above have absorbed the lessons of All Marketers Are Liars:
Successful marketers don't talk about features or even benefits. Instead, they tell a story. A story we want to believe.
The problem is that there are only so many untold-stories out there. Norman is rehashing the time-worn lessons of attentive, professional design, while making dubious distinctions between "human centered" and "activity centered". 37Signals is repackaging agile software development a.k.a extreme programming, warts and all. Clay Shirky is an academic, and academics are frequently required to take aggressive or contrarian positions to ensure attention, tenure, and publication. If you take the step of distilling your story to a one-sentence elevator pitch, there's a solid chance you'll be overlapping someone else's pitch. This is fine... if you're not also pretending to break new ground by conventiently omitting mention of where the idea may have originated.
Aug 4, 2005 7:13am
acd, hcd, etc
There's an interesting thread going on at SIGIA-L right now. After Don Norman's latest doe-eyed essay ("Human-Centered Design Considered Harmful") was posted, a mostly-illuminating discussion about the role of the designer in unintended consequences ensued. I was initially swayed by Don's essay, but I don't really have the same background in the relevant literature, and I've since come to view Norman's essay as somewhat deceptive.
From the article:
One basic philosophy of HCD is to listen to users, to take their complaints and critiques seriously. Yes, listening to customers is always wise, but acceding to their requests can lead to overly complex designs. Several major software companies, proud of their human-centered philosophy, suffer from this problem. Paradoxically, the best way to satisfy users is sometimes to ignore them.
This quickly started moving in the direct of Intelligent Design, a topic that needs its own Godwin's Law.
How many purposes does a telephone directory serve? I use one to jack up the height of my PC monitor. This is a function of characteristics of the technology (phone book), my desktop environment (desk/chair/monitor heights) and my need for a higher monitor (my physical capacities) and my ability to 'see' the phone book as a solution to my problem.
Ziya:
Again, these may be interesting use cases that are relevant to an anthropologist, as it were. But there's absolutely no reason for paid designers to go out of their way to consider your usage of a phone book as a monitor stand. The fact that you did doesn't inform the design process in a meaningful way.
Designed for driving nails into wood, (the hammer) has been designed with a simplicity that it affords many other uses (driving in wooden plugs, driving in screws, breaking bricks, cutting wire, opening bottles of beer). It's easy to imagine some designer being tasked with "design me a tool for driving in nails" and coming back with some device that does that, but has no affordances for anything else.
Meanwhile, O'Reilly posts topics for this year's Emerging Technologies conference, one of which is "Externalities, Affordances, and Unintended Consequences":
Affordances, usually associated with human-computer interaction, industrial design, and environmental psychology, is here seen as the flipside of externalities: one person's externality is another's affordance.
If I can get a proposal together in time, this should be a hell of a gathering. Antoher interesting topic is "Data as Platform":
How can data visualization use our cognitive preattention to assimilate data quickly, rather than just paging through a database view. Will remixing always be a hack, or are there ways to offer stable commercial services around remixed applications? In other words, what's the path from hack to product for remixing?
Aug 3, 2005 4:57pm
announcing vox delicii
I switched the data source for the News project from Google News to Del.icio.us Popular, and called the resulting piece Vox Delicii.
Here's why:
Since August 2004, Google's algorithm for determining news items worthy of inclusion on the "In The News" short list has become much more opaque, and a little less meaningful. Before that date, I believe it to have been based on objective popularity. George Bush was always in the news, and major news events such as the Richard Clarke / Condi Rice hearings in Spring 2004 were very well-represented. About a year ago, Google switched to an algorithm that appears to be based on the first derivative of popularity: major newsmakers such as George Bush no longer showed up, while lots of "flash in the pan" names did. It was a sensible decision on Google's part, but hell on anyone trying to do a visual analysis. The appearance of the heat map became significantly more chaotic, and it was more difficult to view patterns. In effect, the map above shows change over time, and doing so with information that is already showing change over time gives you a map of acceleration, which is more difficult to comprehend quickly and less interesting to watch.
Similarly, Google's process for determining what constitutes a "proper noun" is also opaque. When Sun and Microsoft settled their long-standing legal disputes, Sun Microsystems appeared here while Microsoft did not. I don't know why - maybe Google is only interested in pairs of capitalized words surrounded by non-capitalized words.
Meanwhile, Del.icio.us Popular is completely transparent. A quick glance at the list of popular items shows them to be organized by number of recent posts. A little digging shows that this number is probably based on the number of posts in the last 24 hours, so right away there's an objective method for understanding the source of the data.
In some ways, the Del.icio.us data is also more interesting for what it represents. The News information was based on news-room memes, and strongly influenced by the Associated Press and the general tendency for news sources to reprint each other's stories. Thus, it wasn't really graphing the mindshare of information deemed interesting by the general public, but by that of professional journalists and their employers and stockholders. Meanwhile, Del.icio.us popularity is a significantly more bottoms-up affair, tracking the oddball tastes of the geek set as it flocks to stories linked from Slashdot or BoingBoing. This is real, honest-to-goodness attention data and it should be fun to watch and analyze as the set grows.

Jul 28, 2005 5:53pm
podcasting
Maciej's Audioblogging Manifesto notwithstanding, this comment on the recent New York Times article "Podcasting Hits Mainstream" is on the money:
Here's a success story for you: I'm now enjoying podcasts so much that I've begun taking the bus to work instead of driving to work, which adds about 45 minutes of communting and listening time into my day. Podcasts reduced my dependence on foreign oil. :-)
(from 37s)
My dad just read Kunstler's Long Emergency, and is all fired up about peak oil. I think there may be an interesting confluence between efficient information-foraging behavior and environmental harmony. Kunstler's main argument seems to boil down to one of human reaction time: given that oil is a finite resource (the only real point of debate is when it will run out), the most important variable is the speed and intent of civilization's rection. If we wait for the market to respond to decreasing supply, we will have waited too long. The book argues that peak oil is a manageable situation if we work to eliminate suburban patterns of living now - move to the city, or become a gentleman farmer.
Meanwhile, the mechanics of attention and connectivity are reaching a point where it's possible to live a rapid transit urban lifestyle, and have more leisure time to read & learn. I do almost all of my reading on public transit, and podcasting only makes sense to me in a context where I'm away from my usual speedreading environment.
Jul 23, 2005 12:47am
painting in public
My good friend Kelly is in the Chronicle today:
"If you don't have a gallery show and you don't have a job, then you do live painting,'' he said as he kneeled on one knee and began to brush the scene with bright oranges and deep blues. "It's a way of getting gigs.'' Porter is one of many young artists who are venturing out from the quiet solitude of their studios to paint before a live audience. While people chat, mingle or dance, artists are turning a blank sheet of paper into art, often inspired by the music of a DJ or a live band.
Jul 22, 2005 5:18am
more notes on look and feel
Last month I posted a small group of application fragments that I think are particularly good designs to emulate for an upcoming revision of Reblog, an RSS aggregator application that I co-develop with Mike Frumin at Eyebeam.
I just finished the first draft of a redesign based on those notes. Feedback would be very much appreciated.
Jul 22, 2005 5:18am
@#$% moveon
Why am I getting mail from MoveOn yelping about this week's milquetoast Supreme Court nominee, while this is happening?
Jul 21, 2005 6:16pm
mappr in businessweek
Businessweek Online has an article by Rob Hof that details several web services mashups, including our project Mappr. The "slideshow" illustration is a Mappr screenshot, and we're #4 in the list.
I know this because I've been getting CPU load warning messages on my phone all morning, and our traffic has increased by something like 1000%.
Also featured are ChicagoCrime, HousingMaps, and Alan Taylor's Amazon Light. A9 is an interesting inclusion, because unlike the rest of these "unilateral collaborations", it's an official project from Amazon.
Jul 19, 2005 10:52pm
america, fuckyeah
This morning I took the Naturalization Oath of Allegiance and became a citizen of the United States, finally.
Jul 15, 2005 5:50pm
emulating gmail conversations in mail.app
I use Apple's Mail.app as an IMAP client. It means that I can also check my mail via Pine or Squirrelmail, on any of the machines I use regularly. This is good.
Gmail has an awesome design feature called conversations, where your inbox and outbox are merged into a single message stream, and you can see a complete back-and-forth exchange in one place, instead of having to rely on sane quoting practices or constantly switch between mailboxes. I don't use Gmail for a number of reasons, mostly inertia and control-freakishness. I do want the benefit of conversations, though.
One method I've thought of using to duplicate this feature is to generate procmail rules to automatically route all of my non-list inbox mail to a "conversations" mailbox, and then use that as my outbox as well. This could work, but it feels like a serious hack that could have negative consequences down the line. Since I use Mail.app as my primary mail client, I think that OS X Tiger's new "smart mailbox" feature offers a nice compromise, where I get to have a conversation view in just one of my mail-reading environments.
So, by setting up a smart mailbox with just two rules, I've got conversations and I don't need to switch to Gmail to get them. The rules are simply to include all mail that's either in my inbox or my sent folder, nothing more. This handles 90% of the cases where I might want to interleave messages, with very few drawbacks.
There are two big problems with this approach:
- It only works in Mail.app. I can deal with this, since the conversation view is not yet a crucial feature of my reading.
- Mail.app's search feature doesn't seem to work within smart mailboxes. This is probably a bug on Apple's part, or at least a lame design decision for the sake of efficiency. Maybe they'll fix it in a future release.
Jul 12, 2005 4:33pm
panoramic photos from new york
I just returned from my five-day trip to New York on Sunday. I was in a panoramic photo mood, so here are four composite images. The first two are from Eyebeam's Chelsea space, and the last two are from my friend's warehouse space in Williamsburg where I stayed.




Jul 9, 2005 12:20am
we spoke at flashforward
Darren and I presented an hour-long Ask The Experts session at at Flash Forward in New York this morning.
Slides from our talk are available for download. There are also BSD-licensed demo files that demonstrate Flash implementations of various map projections and some helpful linear algebra.
Jul 8, 2005 5:32am
media futures
Five articles I need to read very soon, in Seth's Transparent Bundles:
- Media Futures: AUTOMATA: "The most exciting new Internet companies are focused on lead generation, behavioral targeting, co-registration paths (aka coreg) and domain name brokerage. I seem to stumble every day across some new firm propping itself up on the shoulders of Google, Yahoo! or others to take advantage of a current wrinkle in an otherwise perfectly efficient landscape."
- Media Futures: ALGORITHM: "An Algorithm is a set of instructions or procedures for solving a problem. In the same way that computer scientists 50 years ago focused on the single problem of designing a general purpose computer, there is a similar focus in 2005 among leading Internet service architects: creating a social media computer that leverages user generated content to automate the production of commercial content."
- Media Futures: API: "...But now, in tackling the concept of API, even as it relates to something familiar like Internet Advertising, I am intimated by the history of professional, enterprise computing...."
- Media Futures: ALCHEMY: "In considering Alchemy as it relates to the Internet, I have been spending my time trying to reconstruct my college readings of Walter Benjamin, the beautifully melancholy German essayist from the 30's."
- Media Futures: ARBITRAGE (II, III, IV, V): "Arbitrage is the fifth and final part of the Media Futures series. It has taken me a full month to establish enough contexts for the word so as not to reduce its meaning."
Jul 5, 2005 1:17am
new york again
Darren and I are heading to New York tomorrow, where we will host our "Putting Data on the Map" Friday morning Ask-the-Experts session at this years' Flash Forward conference. Anything interesting going on I should know about?
Jul 4, 2005 11:28pm
we spoke at where 2.0
Eric and I presented our MoveOn Virtual Town Hall project at O'Reilly's Where 2.0 conference last week.
Our talk went well, the whole conference was great fun. Slides from our talk are available for download. Elizabeth Goodman posted notes on the conference, including our 15-minutes segment - ours is near the bottom of that page.
Jun 29, 2005 7:30am
notes on look and feel
I've been planning a visual overhaul of Reblog's stylesheets. They are starting to look puffy and dated, and its time to cut out a little fat. I've collected a small group of application fragments that I think are particularly good designs to emulate.
Jun 28, 2005 2:18am
we are speaking at where 2.0
Eric and I are presenting our MoveOn Virtual Town Hall project at O'Reilly's Where 2.0 conference this week.
Stamen collaborated with MoveOn.org to create a live, map-based application which allows thousands of people to simultaneously communicate with MoveOn staff, featured speakers and one another. The project encourages a visceral sense of "being there" among participants, provides an immediate visual picture of the spread of MoveOn membership, and allows that community to connect with itself in a powerful new way. Upwards of 50,000 members have participated in these online town hall meetings simultaneously. Migurski and Rodenbeck will describe the nature of collaborative engagement that live online maps can provide.
Jun 26, 2005 11:16pm
razorbern, amazing photographer
Razorbern's photos on Flickr have been among my absolute favorites over the past few weeks. Here are a few that I expecially like:




Jun 25, 2005 9:46pm
GSV released
I've taken my previously-mentioned giant-ass image viewer, renamed it to "GSV", and cleaned it up a bit for easier distribution under a BSD license.
Features:
- Allows viewing of extremely large images on the web, by segmenting them into smaller tiles and showing only what will fit on the screen.
- Complete visual control through vanilla CSS.
- No server-side technology required.
- Developed in Mozilla and Safari, tested in Internet Explorer, reportedly works in Opera.
- Thanks to behaviour.js, very little actual Javascript knowledge required.
- Includes Python script for segmenting images.
Jun 24, 2005 6:15am
reblg, again
Marc Canter posted a lengthy reply to my previous post about reblg. It's a great point-by-point answer, and has been clarified somewhat through conversation as well. He really has a grand vision of a microcontent mesh, and it's both aspirational and achievable, so I'm into it. There are still a few difficulties I'm having with it, though, mostly of the "metacrap" variety.
Overall I'm really into the possibilities here, because I think that microformats have great potential to pick up some of the sem-web slack in a way that's incrementally reachable.
Marc lists a few benefits for content creators in addition to the ones I mentioned. One is:
It's imperative that the structure of the microformat or micro-content be maintained. This is the 'challange' that RSS has put us into - services like UpComing.org enable subscription to one's personal events, but the structure of the event is lost. That's gotta stop. We NEED to maintain the structure of stuctured content!
Okay, yes. But right now I subscribe to an iCal version of my Upcoming.org events, and they appear in my calendar app along with all my other events and appointments. That's not just structure, it's structure in a format I can use directly. hCal isn't there just yet, and it's the easiest one of the microformats to render unambiguously. Imagine hReview butting up against straw man #7.
Something else he says, later:
Going back to the islands of functionality..... For us (as an industry) to equal Longhorn and whatever Apple comes up with - it's imperative that we come up with techniques to implement the mesh. A mesh that inter-connects tools togfether. That's the infrastructure we're proposing.
I'm curious why Google isn't on the list with Apple and Microsoft. I view them as being in the best possible position to provide the kinds of aggregation services that microformats need, and the least likely to cooperate openly. Just as tags are useless without a Del.icio.us or Flickr to provide a comparative context, semantic microcontent requires that like be compared with like for it to make any sense. A decent search engine that was microcontent-aware would certainly help, and this seems to be exactly what Marc's proposing.
I bet it would take Google a month tops to implement the expected response for a search like "format:hcal san francisco skinny puppy shows".
Marc pledges not to commericialize the data, which is a bit of a bummer to me. Having a plan for commercialization up-front means that you're prepared for the eventuality (because it always comes up), and you're talking about it from day one so nobody from the information-wants-to-be-free crowd freaks out down the line.
Anyway, it's a lot to digest. Especially as it relates to ReBlog, because there's so much overlap it's scary. He's right that we're converging on the same spot from different direction - ReBlg has the big picture with not a lot of proof-of-concept, while ReBlog has been working pretty well for a year now in the specific domain of RSS content curation. It's a few plug-ins and bookmarklets away from realizing half this stuff.
Jun 23, 2005 7:10pm
cameron's blog survey
I took Cameron Marlow's weblog survey so he can finish his PhD, and you should too.

Jun 22, 2005 8:49pm
continuous partial attention
These are excerpts from Nat's notes on Linda Stone's Supernova 2005 talk on Attention.
I see twenty year cycles. Coming through in the cycles is a tension between collective and individual, and our tendency to take set of beliefs to extreme then it fails us and we seek the opposite.
...
1985-2005: Network center of gravity. Trust network intelligence. Scan for opportunity. Continuous partial attention is a post-multitasking adaptive behaviour. Being connected makes us feel alive. ADD is a dysfunctional variant of continuous partial attention. Continuous partial attention isn't motivated by productivity, it's motivated by being connected. MySpace, Friendster, where quantity of connections desirable may make us feel connected, but lack of meaning underscores how promiscuous and how empty this way of life made us feel. Dan Gould: "I quit every social network I was on so I could have dinner with people."
...
The next aphrodisiac is committed full-attention focus. In this new area, experiencing this engaged attention is to feel alive. Trusted filters, trusted protectors, trusted concierge, human or technical, removing distractions and managing boundaries, filtering signal from noise, enabling meaningful connections, that make us feel secure, are the opportunity for the next generation. Opportunity will be the tools and technologies to take our power back.
"I quit every social network I was on so I could have dinner with people." I thought I was just nuts.
Brilliant.
Jun 21, 2005 3:16pm
contagious media trophies

"Awards for the winners of the Contagious Media Showdown. Custom printed on our 3D printer, each trophy represents the traffic to the site over the course of the contest."
How cool is that?
Jun 21, 2005 6:38am
reblg considered baffling
So Marc Canter announced reblg today:
Ever wondered why you cant just click on an article and blog it? Where's the universal "Blog This" button? Concerned that while microformats and micro-content standards are taking off, our existing tools will lose the structure of these chunks of reviews, events, media. Etc.? Where are the reblogging tools that maintain the structure of microformats and micro-content? Tired of being forced to use only the latest tool or utility to take advantage of a new standard wish you could use ANY tool or utility instead? Where's a routing service to enable me to send posts to whatever tool I chose? Well then you know why we created ReBlg.com, a universal "Blog This" button and routing service.
I'm confused, but here's my interpretation:
Reblg hopes to spur the growth of microformats on the web, by introducing a tool (or set of tools) that create an incentive to post in a structured format. Presumably Reblg will be sensitive to hCal, hReview, and the other microcontent formats currently being pushed by Technorati. I don't see a format for your basic "blog post" but I imagine that such a thing is not too far out. Reblg's Grease Monkey script will parse HTML and add little orange "blog this" buttons next to recognized content chunks - calendar events, etc. Users of the script and other Reblg tools will be able to click those buttons and have them route the clicked-upon content to a blogging tool of their choice.
The benefits to weblog writers would be:
- Faster time-to-repost. Adding a piece of microcontent to your site would be a one-click operation, presumably with an extra "are you sure?" step and some space for comments thrown in.
- Easier to find re-postable content. If Six Apart and Blogger get on-board, many sites will be publishing this easy-to-repurpose material by default.
- Faster spread of your writing. Providing standard ways to repurpose your writing means that your readers can pass it on with less muss, less fuss.
The benefits to Reblg/Marc Canter would be:
- Marketable data. The Reblg service handles the transition between a click of the orange button and a post to your site. Each re-post would be routed through the server, along with immediate information on who's posting what and where they're getting it. Right now, Technorati and other similar sites get a lot of their information via trackback pings generated when a post is published. Here, Reblg gets much of this same information when a post is conceived. Holy crap!
- Copious whuffie.
I'm not fully clear on how this beats the One Microformat To Rule Them All, the URL. It feels to me that a lot of blogs have had this problem licked for some time, by providing permanent links to individual content chunks. I guess it's Marc wants to get not just the text of the linked item, but also the markup and semantic content. An item posted as an hCal event would stay that way through any number of "reblggings." I'm not sure I agree that this is necessarily a desire shared by others, though, because I can't piece together the first list of benefits above into any shape that would make sense for mid-stream users - people coming across reblgged posts and wanting to pass them on. hCal could be useful, if someone were to cook up an HTML-to-iCal bridge for it, but right now it's about as useful as the rest of the semantic web.
One place I can see this being insanely cool would be to make the linkage information open, like Del.icio.us does. If (as a writer) I could see who has been repurposing my microcontent, it would help close the already-tight post response ego trip loop accelerated by Technorati.
Oh yeah:
Final NOTE: We feel horrible about being so close to Reblog.org. They're nice people but we use the term reblog completely differently. Hmmmmm.
Dammit Marc, it's a great name, think up your own! Help me understand how this use of "reblog" is different from ours.

Jun 20, 2005 10:53pm
giant-ass image viewer
I've been experimenting with segmented, javascript views of significantly large images. See what I'm talking about here.
Update, Monday morning: This has caught the eye of Kottke's remaindered links and O'Reilly's Radar, which is making me think that I should take the javascript version a little more seriously.
So, I promise that at some point in the next few weeks, this will be packaged up into a nice little script that can be easily incorporated into any website.
Jun 18, 2005 11:42pm
adam: back from the dead?
Adam Greenfield has recently started posting again. I guess he was busy writing a book. It's nice to be reading V-2 again on a semi-regular basis; it was one of my favorite weblogs last year.
Jun 13, 2005 2:46am
fridgediff
Silly ubicomp idea.
FridgeDiff is a software + hardware system designed for installation in refridgerator doors. A webcam is pointed towards the fridge interior, and an automated snapshot is taken each time the door is opened and closed. The photos are compared pairwise, so that differences in fridge contents and arrangements can be timestamped. Image analysis techniques would be used to help identify the movement of items from one spot to another, but the real power would lie in providing information on food age. Any particular item could be tracked backwards in time to its first appearance, so that age could be determined to help judge when items should be discarded.
Additionally, metadata about the items might be provided with the aim of encoding expiration date information. If the fridge knew that a given had a 2-week lifespan, it could warn the user (via SMS, RSS, whatever) of impending spoilage. This meta-information need not be added synchronously - instead of depending on barcode readings or ubiquitous smart foods that announce themselves via RFID, FridgeDiff would sport a web services connection, allowing for large-scale, distributed content-tagging. By harnessing the food-identification smarts of the Bored At Work Network (BWN), FridgeDiff lets the collective intelligence of the internet teach it about food's behavior over time.
All of this would have just saved me the intense, personal hassle of cleaning out the back of our refridgerator and disposing of a full bag of moldy leftovers.



Jun 7, 2005 5:36pm
shawn in morocco
Shawn has been posting his amazing photos from Fes, Morocco.
Lots of human-scale interior spaces such as this one, hot on the heels of fresh attention paid to Christopher Alexander's work.

Jun 7, 2005 4:40pm
copyright idiocy
Two from Andy:
Plan to extend copyright on pop classics:
Britain's super-rich rock veterans are about to get even richer. The government wants to extend copyright laws to ensure pop songs are protected for almost twice as long as the current 50 years. ... James Purnell, the new minister for creative industries, believes the change will allow record companies to generate extra revenue to look for new talent and nurture it. Purnell, who will outline his plans in a speech next week, said: The music industry is a risky business and finding talent and artists is expensive. There is a view that long-term earners are needed so that the record companies can plough money back into unearthing new talent.
$#@*!!
Tough shit, James. Why is it that international copyright terms are being standardized up instead of down? The way things are going, who knows if these record companies will even be around to collect royalties in ten years, not to mention 60.
Digital photos can look great, but some labs won't print those that appear too professional:
Photofinishing labs increasingly are refusing to print professional-looking photographs taken by amateurs. The reason: Photofinishers are afraid of infringing on professional photographers' copyrights.
Double $#@%!!
I must not have been paying attention when we crossed over into Bizarro-world.
Jun 5, 2005 6:58am
RSS reuse
An interesting conversation has been brewing over at Read Write Web. It starts with a note about SuperFeedSystem and its marketing language:
What if you could have constant new content on your site ... without having to write a word of it? Now you can with the wonderful power of FEEDS. ... Use other people's information to have constant, new, expert articles auto-added to your sites.
There's an element of personal interest for me here, because I'm a co-writer of ReBlog, and our language says:
A reBlog facilitates the process of filtering and republishing relevant content from many RSS feeds. reBloggers subscribe to their favorite feeds, preview the content, and select their favorite posts. These posts are automatically published through their favorite blogging software. ... reBlogs are useful to individuals who want to maintain a weblog but prefer curating content to writing original posts.
Wow, sounds pretty similar.
I believe we avoid the thornier redistribution issues aired on Richard's site by focusing on the personal nature of reblogging, and taking care to build a clear chain of attribution into the reblogged news items. However, the technology is effectively the same between the two projects: SuperFeedSystem could probably be used to publish an Unmediated or Eyebeam ReBlog, while our software could be used to co-opt other people's written works into a search engine juicer.
Legally, the issues here are also identical. A few commenters argue that the second S in RSS grants implicit permission to re-use, but I don't believe this to be the case. Copyright law is clear that the owner of a work has the right to determine where and how it is reproduced. I don't think that the publication format is an implied license. I'm actually surprised that this conversation is even taking place - the stated goal of groups like the Creative Commons or the FSF is to provide for ways to unambiguously license material without requiring the old-style byzantine permissions runaround. It feels as though most of these questions have been asked and answered countless times, and that in 2005 it's enough to slap a CC badge on the work and be done with it. Richard's site lacks one, therefore he reserves all rights except fair use (excerpts, attributed quotes).
Still, I can see why there's a point near the end of the comment stream where the spittle flies a bit; ultimately it comes down to user's intent with a program like SuperFeedSystem or reBlog. If attribution is given in good faith and content is sampled judiciously, there rarely seems to be a problem.
A commenter near the bottom says:
I've never used any of Rich's articles, but now I definitely know that I won't. I would think that most people would get the hint from this conversation. Please keep life simple for newbies like me. RSS has been fun so far without the legal mumbo jumbo.
The whole point of a Creative Commons license is to recognize that new technologies allow for wholesale duplication, recontextualization and redistribution, and to formalize the licensing process with a simple pattern.
Jun 2, 2005 6:32am
VJ book: print with comments
Tim Jaeger is currently working on a project called VJ-BOOK.
VJ-BOOK is one of the first books that will be published on VJ culture, and potentially the first to theorize VJing in a way that breaks down the practice and reception of live visuals in a systematic, structured way.
The book is meant to be an academic work on VJ'ing, which is a lot more interesting than the glut of mid-1990's rave flyer books that functioned solely as collections with no commentary or reflection. The most fascinating aspect of this book for me is the beta reader concept:
Beta-Readers will serve an important function in VJ-BOOK. Contributing to its semi open-source format, PDFs of the different sections will be distrubuted to selected parties ahead of time (approx. Aug 2005) who will then add comments, additional photos, anecdotes, etc. These sections will be distibuted according to the readers unique areas of knowledge (software, a particular scene, etc.). This will serve to produce an authorship model that is similar to threaded online conversations rather than a single, stand-alone text.
Early printed books came with wide margins built-in, for use by readers when taking notes or adding glosses. These were necessarily personal, while Tim's are slightly more public without sacrificing the "official" feel of a printed book. Purple numbers in a printed work could serve as a bridge or peg to open the margins to the wide world. Incidentally, these same themes are explored in Narrating Bits, an interactive academic work that we helped develop with Erik Loyer earlier this year. This project was just mentioned on the excellent Information Aesthetics weblog.
Jun 2, 2005 2:11am
Re-re-re...
Let's create a feedback loop and reblog blogs about the reblog ~tj
Hooray for recursion! (again)
Jun 1, 2005 3:39pm
international symbol of RSS

I just got through posting this to an entry on Radar about the general incomprehensibility of XML/RSS icons on web pages:
The one thing all those buttons have in common is white text on an orange background, which is becoming something of an international symbol for a feed independent of format. RSS Equalizer and RSS Content Builder.com even use this convention in their product logos. It won't be long before this pattern enters the global consciousness, "the thing that decided decaf coffeepots should be orange."
Why not jump-start the process and ditch the letters altogether? A symbol such as this small image has a number of advantages over the RSS and XML buttons:
- Orange and contains three enclosed elements. This echoes the older buttons for those familiar with them.
- Visually distinctive, but still wordlike and usable within a text stream or verbal explanation.
- Designed to be small.
- Independent of language or character set.
- Three bullets look like an ellipsis and imply repetition and continuation.
Jun 1, 2005 2:55pm
eyebeam's guest reblogger
Starting this week, Eyebeam's guest reblogger of the fortnight is VJ Tim Jaeger. Until I shifted my focus completely to net-based visuals and data graphics (and co-writing ReBlog ;), VJ'ing was my most serious side project. I produced a lot of free video loops, experimented with 3D rendering in Max/MSP, and participated in local video events.
It should be fun to see what constitutes the cutting edge of the genre since I last performed.
May 25, 2005 4:45pm
ads in rss feeds
Let me circle this back to ads in RSS feeds. You can be fairly sure that every single person subscribed to your feed is a daily reader and it's not likely random searchers would add your feed. The people reading your feed are using a feed because they don't want to miss a single word you're saying. They're not just fans reading your site, they're more die-hard than that. Who would you subject to advertising, if you had a say in the matter: random visitors or your biggest fans?
I think Matt is overlooking the fact that RSS is beginning to cross over from personal publishing to commercial publishing. News organizations and professional bloggers aren't necessarily subscribed to because die-hard fans don't want to miss a word. Of the few hundred feeds I'm subcribed to, a very small (and shrinking!) percentage are personal subscriptions. The majority of my subscriptions are "industry" related - topical news aggregrators, keywords from Del.icio.us, and single-issue weblogs like Read/Write Web or if:Book feature prominently.
I'm not absolutely certain where Daily Kitten or Light Cone fit.
RSS is now my primary approach to many of these sites. A number of them subsist entirely on ad money. While I'm not thrilled to be advertised at in my own feed reader, I do acknowledge that a lot of these high-volume skim-feeds may not ever get a proper visit from me, and therefore need to push their support mechanism out where I can see it. As long as the ads stay plain text and on topic, I'll suffer them.
May 23, 2005 2:47am
the future of television, according to Bill Gates
Bill Gates, describing customizable television in Newsweek:
"Ninety percent of that stuff you don't care about," says Gates. "We'll let you have a custom ticker [with stock quotes, scores and other information that you pick]."
Geez, thanks Bill. I'll just get back to my existing personalized ticker and custom TV.
May 15, 2005 12:15am
regarding competition for bloglines
I sent this mail to Richard MacManus the other day. It's a response to his post about the suckiness of online feedreaders, and a manifesto of sorts about the qualities that make a good RSS reader. Writing it helped clarify some of my thoughts about potentially interesting extensions to ReBlog.
In Competition for Bloglines, you say: "...the User Interface of Bloglines is beginning to get very creaky. It still uses frames, for crying out loud! There's not a whiff of Ajax in the Bloglines UI and narry a hint of tagging."
I don't know if Ajax and tags are the magic bullets that can make or break a web-based feed aggregator.
Ajax is a great tool, but I don't think it's really relevant here (more below).
Tags are post-processing organizational aids: encounter a resource, read/view/understand it, and then tag it for later recall. This does not help with the efficiency of processing of new information, and in fact hinders it by creating an additional categorization step for new items. It's analogous to Apple's new Spotlight feature in Mac OS X Tiger: they added a file-processing step to the kernel that indexes resources as they are written to the filesystem, and this takes time. Thankfully it's just CPU time and not cognitive time - tagging always explicitly takes someone's attention.
The great strength of Del.icio.us is that it helps people leverage each others' attention, creating something like a distributed computing application for categorization... "Taxonomizing@Home!" =oD
The problem with a lot of feed readers is that they have a simple list-of-lists UI. None of them learn from past behavior to affect incoming information. You're just presented with a list of feeds, and a list of items in each of those feeds. If you're subscribed to the "Map" tag from Del.icio.us, for example, you see Map24 and Google Maps scroll by a few dozen times a day. Over time, this detracts from the value of the Del.icio.us feed by continually showing too much old information. There have been suggestions on the Del-discuss list to include a link in the feed for a tag only when it is first added, but it has been rightly pointed out that this strips out too much information: it's important to know that 100 people tagged this link, while only 10 people tagged that link.
I think there's some pent-up demand for an RSS client that handles this logic, because no matter how intelligent Del.icio.us gets about dupes, it will never be able to know that you've just seen the same link on Waxy, Kottke, Slashdot and Mefi. Steve Gillmor has written about an idea he calls "Information Triage", which describes a possible approach to dealing with the deluge.
I have a personal interest in all this, because I am one of the maintainers of ReBlog, a web-based feed reader whose specialties are republishing (an outgoing feed of items you deem interesting is published - this is currently used to run Eyebeam's ReBlog, Unmediated, and other sites) and a swanky user interface that makes feed-processing faster and easier through respect for Fitt's Law and a forthcoming keyboard-navigation interface.
Unfortunately, my own experience with subscribing to 200+ feeds has been frustrating: if I don't keep up with them, they quickly spin out of control. I don't think it's unusual for heavy RSS users to open up their reader software in the morning to find 1000+ unread items, with no sensible way to understand which items are new, which ones are repeats, or where to devote attention first. My personal feeling is that in order to successfully handle a large number of subscriptions, a good RSS reader must have some concept of statistical analysis, similar to Bayesian spam-filtering methods. If you've ever use DEVONThink, you'll know what I mean.
If the software can tell me that an item I'm looking at contains similar language (or links to the same URL) as 20 other items from 5 different feeds I'm subscribed to, this is tremendously valuable. I can start to operate on information in the aggregate. I can use my reader as a force multiplier, to get a high-level overview of the information flowing my way. I don't have to drink from an RSS firehose all the time.
Ajax has a place here as an interface assist. ReBlog already uses Ajax techniques heavily, to archive & publish items. These could be extended to providing more information about items as well. I'm imagining a reader that slowly fills in context about a given RSS item as you read it, by requesting and displaying stats about the popularity of that link within your set of subscriptions, or historical data such as when it first crossed your path. It could provide an option to ignore all future occurrences of the URL - who needs to see 30+ links to Backpack in a given week, after you've seen one and acknowledged it?
This kind of smart-client aggregation triage could be a serious advantage for anyone who needs to keep up with large volumes of information on a regular basis.
May 10, 2005 2:16am
irreverence deemed...
Disney has deemed irreverence as one of the five core equities of the Muppets (humorous, heartwarming, puppet-inspired and topical being the other four)
May 8, 2005 6:48pm
a new digital divide
I think a new divide has opened up, one that is based far more on choice than on circumstance. Several million people (and the number is growing, daily) have chosen to become the haves of the Internet, and at the same time that their number is growing, so are their skills.
Is it a divide if it's based on choice? Sounds more like the classic early/late adopter distinction to me. I basically fit onto the left-hand column for every row in Seth's table, which is an odd feeling. Bored with Flickr is a little harsh, but I must say that I'm more exited by the opportunities for social behavior that Upcoming affords than the passive social behavior that Flickr does. Flickr : past :: Upcoming : future.
May 6, 2005 7:52am
allegorical web design
Mboffin posted an animation showing the development of a basic web log in the form of a stream of screenshots. It's a 900k GIF, coincidentally the same dimensions as the monochrome monitor of my first computer.
My first impression is that it's a disarmingly simple demonstration of standards-based web design that explains the process better than any book or advocacy project ever did. It approaches Jon Udell's Heavy Metal Umlaut movie in communicative density and progressive unveiling of an idea.
The animation starts with a blank page, and a title: "Site Name." The process of constructing a website framework in this way and the mode of presentation feels like a handy metaphor for a few larger trends in current development for the web (more later).
Site content is slowly added. The page is built from the information up, a radical departure from the html terrorism of the bad old days. New chunks of content are added using obviously semantic markup: headers, unordered lists, plain paragraphs. When I was designing for the web before 2000 or so, I would start at the other end: sketch out a site design, build up a comp in Illustrator and Photoshop, decide where the table cut lines would need to be, and then work out the tedious process of pixel arithmetic GIF slicing. Flexibility had to be considered and planned for. Change was expensive.
Visual design comes next, and proceeds according to the internal logic of the box model. It's worth noticing that at this point in Mboffin's animation, work on the HTML effectively stops, and all effort moves to the style sheets. Previously generated chunks of content are grouped into columns and moved about the page, with backgrounds and borders adjusted. CSS is uniquely well-suited to this sort of incremental play and parameter adjustment, and closely matches Malcom McCullough's understanding of craft as an activity which requires both skill (planning, foresight) and feedback (responsiveness, flexibility). It provides a language that simultanesouly supports generalizations (e.g., "make all the borders red, and give them 10 pixels of space on the left") and specificity ("...except this one").
The final appearance is unmistakably now, from the image-header to the centered dual-column box and subtle gradients. I love the way in which it was approached as a loose pattern with cumulative refinements, rather than a rigidly pixel-specified Photoshop comp.
This particular approach to simplicity feels like an idea that is currently hitting its stride in web development circles, expressed through the mantra of "release early, release often". This example starts from the core of an idea, the textual content of the website. Other examples include event-sharing services and junk-management fads that focus narrowly on a single primary goal, short stories to the sprawling novels of 2001's obsession with content management behemoths. It will be fun to participate in the aggregation of all these porous mini-services into a loosely-coupled "emergent Internet operating system" over the next few years.
May 6, 2005 12:10am
sequence freakiness
To be pedantic, we should have done the five-oh-five tequila shots at 5am.
Apr 24, 2005 1:13am
"stop global warming" launched
I've been silent here for a week, because we've been working frantically to kick Stop Global Warming .org out the door in time for Earth Day.
That was yesterday, and the project is live. It will, of course, grow and change over the course of the upcoming year. The intent is for the site to be a sort of geo-blog, with each update over the next year introducing participants to a global warming hot-spot somewhere in the United States. It starts in Shismaref, Alaska, which is also the subject of an article in the this month's New Yorker on the topic of receding arctic ice. The article describes the way in which the surface reflectivity of ice vs. open ocean acts as a warmth-generating feedback loop. There's a Q and A with the author on the New Yorker's website.
We used Eyebeam's Forwardtrack software as a base for the project, and we are working on a visual map component for the website as the march grows in size and new stops are added. The final development push was madness. I haven't stayed at the office until the first morningbirds started chirping since I first started working with Eric two years ago, but any client who has pizza delivered to help make an all-nighter bearable and champagne when the work is done is all right in my book. Meanwhile, you should join me!
Apr 18, 2005 4:23pm
macromedia bought by adobe
Adobe just bought Macromedia for $3.4bn. This may cause the Flash IDE to suck less.
Dare to dream!
Apr 18, 2005 4:04am
simplicity and verification
Two articles crossed my feed reader today: Bruce Schneier on mitigating identity theft, and a one-sentence post from Thomas Vander Wal on simplicity and complexity:
We must understand and embrace the granular and complex to make things simple for the person.
Bruce says:
Fraudulent transactions have nothing to do with the legitimate account holders. Criminals impersonate legitimate users to financial intuitions. That means that any solution can't involve the account holders. ... Store clerks barely verify signatures when people use cards. People can use credit cards to buy things by mail, phone, or Internet, where no one verifies the signature or even that you have possession of the card. Even worse, no credit card company mandates secure storage requirements for credit cards. They don't demand that cardholders secure their wallets in any particular way. Credit card companies simply don't worry about verifying the cardholder or putting requirements on what he does. They concentrate on verifying the transaction.
These two ideas feel related to me. Thomas generally sums up recent developments in web interface design, notably the "search, don't sort" approach of Google News GMail, and the recent excitement about tagging and folksonomies. Granularity and complexity are being offloaded onto the site owner, where they belong. People who use a service are no longer expecting to engage in their own hierachical sorting of information (because nobody actually wants to do that). Rather, they are using simpler methods for annotating their stuff in a way that makes it easier to find later.
The link to identity theft I have in mind is the locus of responsibility. Currently, victims are responsible for fixing the damage. I check my credit reports every few months to look for fraud, I shred my mail, and I know people who've had severe damage done because they let their social security numbers slip into the open. In Bruce's perfect world, the companies that let your data out would be responsible for the damage, in the form of distributed liability. They would deal with the granularity and complexity of verifying individual transactions, so that their clients can benefit from greater simplicity.
Also, I like Thomas' focus on "the person" rather than "the user". A shift in attitude may help companies such as ChoicePoint regain the trust of the public, if they begin to understand their business as helping people manage the flow of their personal information in the world.
Apr 16, 2005 8:46pm
nine inch nails music giveaway
I was always more of a Skinny Puppy fan, but this is interesting news. Trent Reznor of Nine Inch Nails iss giving away a full track in Garage Band format, based on the original Protools files. This means that all notes and arrangements are free for sampling and re-working, though the output of this remixing can't be used for commercial purposes. Two interesting things about this news, to me:
- Easier mashups. The first mashup I ever heard was a brilliant mix of NiN's Closer and The Spice Girls' Wannabe ("I wanna (huh), I wanna (huh), I wanna (huh), I wanna (huh), I wanna fuck you like a..."). This year's E-Tech theme was "remix", and it's clear that an open-source approach to more than just software is starting to poke its head up into the mainstream.
- Macs. The Apple Powerbook has become the best platform for this change. Reznor is releasing his song in an Apple format, and the balance of power at E-Tech was overwhelmingly in favor of silver Powerbooks. A platform that allows 30 years of Unix history to run side-by-side with new image and music manipulation tools is a huge win. It's not surprising that Apple is posting record profits this year.
From Slashdot:
Hello all-
For quite some time I've been interested in the idea of allowing you the ability to tinker around with my tracks - to create remixes, experiment, embellish or destroy what's there. I tried a few years ago to do this in shockwave with very limited results.
After spending some quality time sitting in hotel rooms on a press tour, it dawned on me that the technology now exists and is already in the hands of some of you. I got to work experimenting and came up with something I think you'll enjoy.
What I'm giving you in this file is the actual multi-track audio session for "the hand that feeds" in GarageBand format. This is the entire thing bounced over from the actual Pro Tools session we recorded it into. I imported and converted the tracks into AppleLoop format so the size would be reasonable and the tempo flexible.
So...
You need a Macintosh and you need GarageBand 2.0. If you have a newer Mac, you already have the software. The more RAM you have the better. I did this on a PowerBook 1.67 w/ 2G RAM but it has been running on far less powerful systems. Drag the file over to your hard disk and double click it. Hit the space bar. Listen. Change the tempo. Add new loops. Chop up the vocals. Turn me into a woman. Replay the guitar. Anything you'd like.
I gave this to my crew and band to test out and all work effectively stopped for a while - it's fun to mess around with. I've now heard a country version of the track as well as an abstract Latin interpretation (thanks, Leo).
There are some copyright issues involved, so read the notice that pops up. Giving this away is an experiment. I'm interested to see what comes of it, what issues are raised and what the results are.
Have fun-
Trent Reznor
April 15, 2005
Apr 14, 2005 7:05am
splines
I've been doing a lot of research on spline curves lately, for a soon-to-be-announced project that requires moderately sophisticated rendering techniques not normally available in flash. This project has two requirements: drawing a smooth line through a series of points on a map, and varying the thickness of the line to convey information.

(see this in motion, see how it was made)
For those not familiar with graphics software such as Adobe Illustrator, splines are curves whose shape can be controlled by points. The curve travels through anchor points, while control points are used to influence the shape of the line. Here's an example, with anchor points shown as open blue circles and control points shown as filled blue dots:

The word spline comes from a term used in shipbuilding:
Because of their great size, such drawings were often done in the loft area of a large building, by a specialist known as a loftsman. To aid in the task, the loftsman would employ long, thin, flexible strips of wood, plastic, or metal, called splines. The splines were held in place with lead weights, called ducks because of their resemblance to the feathered creature of the same name. (Philip J. Schneider, NURB Curves: A Guide for the Uninitiated
The Flash MX drawing API provides a function called curveTo(), but it's based on a simpler type of spline curve called a quadratic curve. The splines used in Illustrator are cubic curves. The difference has to do with the number of control points that determine a curve: more control points means better control over the curvature of the line. Fewer control points means simpler math, crucial for an animation program such as Flash. Timothee Groleau has an excellent article, Approximating Cubic Bezier Curves in Flash MX, which shows a few strategies for "faking" cubic curves using Flash's simpler quadratic curves. The advice boils down to chopping up cubic curves into short quadratic curves that are close enough in appearance to fool the eye.
The math involved in drawing cubic curves is actually a lot less hairy than it looks. The easiest way to think about it is to imagine a point moving through space, pulled towards the control points over time. In those equations, t refers to the position of the point in time, from 0 to 1. x(t) and y(t) are two functions that give the x, y position of that point in space at time t. Drawing curves is difficult, drawing lots and lots of straight lines that are short enough to look like curves is easier. If you thin-slice t, you draw many segments and get a prettier curve. If you increment t by a larger amount, you draw fewer segments for a blockier curve, but it's a faster process.
In my case, I had a series of known anchor points, and had to guess good positions for control points. I did this by looking at neighboring anchor points. For example, when drawing the segment B-C of a longer line A-B-C-D, the position of the control point attached to B is based on the angle between A and C, while the position of the control point attached to C is based on the angle between B and D. This way, the line can be "stitched" together, with a smoothly-varying curvature over its length. A is influenced by B and C, B is influenced by A, C and D, etc.
Rendering variable thickness is more difficult. Taking the derivatives of x(t) and y(t) gives you a vector showing the current direction of the line. Using a bit of cartesian/polar conversion, it's possible to find the positions of points perpendicular to that tangent, which are to the sides of the line. Varying the distance of these points gets you two additional "rails" alongside the central curve. When traced, these rails follow the curve closely. Interesting things happen when the width of the whole thing is greater than the diameter of a hairpin turn.
This flash file shows my progress so far. The open circular points are placed randomly. The positions of the black control points are guessed, and the yellow line is drawn based on these values with a smoothly-varying thickness over its length. The whole thing is interactive, so you can get a feel for the behavior of the path as the control and anchor points are moved about. Here is the actionscript source.
Apr 11, 2005 5:15am
eyebeam's contagious media showdown
yeehaw!
Friends and Colleagues,
I am pleased to announce the world's first Contagious Media Showdown -- an open competition to see who can make the most viral website. Eyebeam set up a special server, lined up thousands of dollars in prize money, and recruited the best and brightest to make this experiment in contagious media possible. You can join the fun here:
http://showdown.contagiousmedia.org/
Enter the contest by reserving a spot on the official contagious media server. Then come to the workshops on May 7th, party with the panel on May 14th, and (if you have skillz) pick up your award on June 18th.
The workshops and panel include the people who brought you HotorNot.com, FundRace.org, BlackPeopleLoveUs.com, the Rejection Line, Blogdex, Del.icio.us, Gawker Media, ZeFrank.com, Dog Island, the Nike Sweatshop Email, and Pizza Party. We have special guests from the Yes Men and the Electronic Frontier Foundation and sponsorship from Creative Commons, Technorati, Alexa, and Datagram Hosting.
It is going to be hot -- tell a friend.
Thanks,
Jonah

Apr 7, 2005 4:15pm
why python web programming matters
Ian Bicking on why Python web programming needs help:
Resolving Python's problems with web programming is the most important thing we can do to market Python. You might dismiss me as being self-centered, as I'm a Python web programmer, and we all think our own problems are the most important problems. But then I'm a web programmer because I think it's the most important and empowering development environment of our time - it has been for at least the last five years, and I'd be surprised if that didn't stay true for at least the next five years. And I am doing okay - these aren't my own problems I'm complaining about. I don't want to talk down Python web programming too much - if you are serious about web programming the initial investment will pay off, since Python is a great environment. But if you aren't committed enough to invest that time, and you want to produce something useful quickly, then - though it hurts me to say this - Python isn't a good choice.
It's telling that I found this linked from Mr. Rails' website, where commenter Jonathan LaCour sums up the situation thusly:
Python doesn't need a Rails clone. It needs something as cohesive as Rails. Rails is good because its a full stack that takes advantage of Ruby's strong points. Python similarly needs a full stack that takes advantage of Python's strong points.
I recently got serious about learning Python for web programming, and I feel the same way. I'm not a rails guy by any means (can't stand the moronic second-coming evangelism: "I can't stand Python. Thanks for wonderful framework, David. Ruby is golden!!!" OMGWTFBBQ.), but having written my own frameworks in PHP, I can see the value of a strong choice with high visibility. Zope ain't it, but that was the best the Python mailing list could come up with when I asked about moving from PHP.
The reason I'm sticking with Python for now is that it's an unmitigated joy to program in. List comprehensions, everything-is-an-object, simple entry-level web packages like Jonpy, and a general feeling of shit-togetherness all make it feel like a "real" language.
Apr 6, 2005 6:57am
vanilla ice ice bay
Implausible Claims Made by Vanilla Ice in His 1990 No. 1 Hit "Ice Ice Baby." Fun fact: I can still recite extended portions of this song, from memory!
Apr 5, 2005 8:26pm
unilateral collaboration
The Christian Science Monitor had an article about website spinoffs by Jim Regan yesterday:
As private and commercial Web portals begin to invite outside involvement and experimentation, new sites are being launched which, rather than offer any unique material of their own, offer an alternative method of viewing someone else's material. Some are practical, some merely recreational, but all are examples of yet another evolution of the web - the 'unilateral collaboration.'
"Unilateral collaboration," what a gem!
It's nice umbrella term for a lot of current ideas:
- The theme of e-tech this year was "Remix," which played itself out in sessions devoted to the theme of working with others' raw materials. There was the web services mashup presentations by Alan, Cal and Erik, as well as sessions on modifying hardware or biological materials. The fact that the CSM is catching on is a sure sign that these kinds of meta-services are real.
- Technological enablers for unilateral collaboration are being embraced by owners of data. Yahoo! now has a robust API available, and firms like E-Bay make a large percentage of their money through their web services interface. The physical metaphor I have for this in my head is less about transparency, and more about porousness. It would be lovely to see this approach spread to other domains, such as government. A complete web-based API to government information would be a dream.
- Legal enablers are gaining some street cred as well. The GPL has worked for years, and Creative Commons licenses are establishing legal ground for copyright-enforced openness in the creative world. Supreme Court Justice O'Connor says "The primary objective of copyright is not to reward the labor of authors, but `[t]o promote the Progress of Science and useful Arts.' To this end, copyright assures authors the right to their original expression, but encourages others to build freely upon the ideas and information conveyed by a work. This result is neither unfair nor unfortunate. It is the means by which copyright advances the progress of science and art."
Apr 3, 2005 8:09pm
launchbar wins
(This entry started out as another application fan letter, but it gets quite a bit more general towards the end.)
I've been a user of launchbar since OS X 10.1. It has recently gotten a bit of high-profile competition from Quicksilver, but the kick in the pants resulted in a beta version that co-opted a number of Quicksilver's new features, in a way that I think is superior to Quicksilver.
Launchbar is a small app that brings a command-line-style approach to interacting with the Mac GUI.
You just hit Command-Space to bring LaunchBar's input window to front, enter an arbitrary abbreviation, and as soon as you start typing LaunchBar displays the best matching choices, ready to be opened immediately.
Launchbar learns as you use it: a few matches for a given set of characters are shown, whose order is dependent on your previous choices. Over time, my copy has learned to associate "F-N" with the Finder, "S-F" with Safari, "M-A-P-S" with Google Maps, "E-R" with Eric's contact information, and so on. For years, Launchbar was limited to finding documents and applications, but recent versions have expanded to include the address book (for mail and chat), browsing history, and tighter integration with the Finder and Terminal.
There are also so-called search templates, URL's with a wildcard. So a Google search for me (system wide) means "Command-Space-G-O-O-Space-[search term]-Enter", while a Wikipedia lookup is "Command-Space-W-I-K-I-[search term]-Enter."
Today I got an object lesson in the value of browsing history search.
I remembered a phrase from a site I had recently seen: "Genre is what we call one hit and its imitators." This wasn't enough for a Google search, and I couldn't remember where I had read it. On a whim, I typed "Command-Space-G-E-N-R-E", and the first result in Launchbar was the Greg Costikyan rant I had been looking for. The word genre appears nowhere in the URL, the page title, or any of the headers on the page. It was just the most relevant recent item I had browsed that happended to contain that term.
It will be fascinating to see how this plays with Spotlight in Apple's forthcoming Tiger operating system. I expect to see direct hooks from Launchbar to Spotlight, allowing for keyboard-only access to full hard-drive searchy goodness.
This all feels like part of a broader shift in attitudes toward computer usage that are summarized in Gmail's slogan, "search, don't sort." This movement is also embodied in popular tools like Flickr and Delicious, which have popularized a flatter, more ad-hoc method of organizing information. Services like these assume that categorization is more expensive than search, a sea change made necessary by the ocean of info-bits we're drowning in, and possible by generally faster processors and generally more ubiquitous internet.
For the moment, the grand unified personal infocloud is still a few years away, but it's being slowly converged-upon from two directions: Launchbar is coming up from the all-your-stuff-in-one-place approach, while a galaxy of API-enabled web-services (Flickr for pictures, Odeo for sound, 43 Things for desires, Ta-Da Lists for responsibilities, Upcoming for events) are exploring the all-of-one-type-of-thing-everywhere path. All-your-stuff-everywhere can't be too far away.
Apr 3, 2005 8:14am
pope john paul
Just after the election of the pope in 1978, Father Boniecki recalled, John Paul went on a pilgrimage to the birthplace of St. Francis of Assissi.
"There was a group of people there," he remembered. "The pope didn't know where they were from, maybe Czechoslovakia. They held up a sign that said, 'Greetings from the silent church.' They meant the church from behind the Iron Curtain, the church that couldn't say anything.
"The pope saw the sign and said, 'There is no longer a silent church. I am its voice.' "
(NYT)
Mar 29, 2005 8:01am
mappr mentioned by people we respect
Four nice write-ups about Mappr today.
Thomas alerted us that the Wall Street Journal has a piece about online photo sites:
Sometimes, the results are remarkable. Mappr's programmers searched Flickr for all shots tagged "Route 66," and then plotted them. Sure enough, the pictures wound from Chicago to L.A., with stops in Kingman, Barstow and San Bernardino. Oh, so pretty.
There is also a PC Forum recap in Barron's. Mappr is Stanford GIS website of the week, and Penn State has a class on new media and digital arti criticism which uses Mappr as an example, along with Cassidy's Graffiti Archeology and In The News arch-rival and beater-to-the-punch Newsmap.
I'm especially tickled by the academic links.
Mar 25, 2005 6:14am
bits on wheels - a fan letter
Bits On Wheels is a Mac-only Bittorrent client. It's freeware (but not open source or public domain) and it looks like this:
It has the usual Bittorrent features, and runs a little faster than my other client, Azureus.
The neat thing that sets it apart is the 3D swarm view, shown above. Bittorrent works by enabling participants to self-organize into a swarm: a group of machines group-hosting a particular file at a given time. When you connect to a Bittorrent tracker, your client can coordinate with others also connected to that tracker. Machines with the entire file are called seeders; they share pieces of the file with machines seeking the file. It's akin to book printing through coordinated xeroxing: I'll do the first ten pages, you do the next, then we trade. Easy.
The 3D swarm view shows yourself in the center. Hosts you are connected to lie around the periphery: although a Bittorrent swarm can be a complex graph, the swarm view is self-centered. Hosts around the edges may be connected to each other, but that is not shown.
Each host is represented by a translucent box, whose filling represents the percentage of the file that host has. As you obtain more pieces of the file, your box slowly fills up to 100%. Connections to those hosts are shown as spokes on the wheel, along which data packets travel. Links are bidirectional (you can be sending pieces to a host that you are also grabbing pieces from), and data travels along the spoke at a rate representative of your connection speed. Speedy connections are immediately apparent, as are stalled ones.
The colored circular rail fills up with green as you get more of the file. The screen shown above shows how much of the file I have, and which parts. Each host-box also has a little pie-chart above it, for which I haven't yet found a satisfactory explanation. I'm guessing it shows a host's share ratio, the relative amount of data uploaded vs. downloaded.
The hosts are divided into seeders and leechers: seeders have a red background, and they are completely full. These are hosts that already have the entire file, but are continuing to share more. Leechers are on the blue background, and they are hosts seeking pieces of the file. When your client has successfully downloaded 100% of the file, the background becomes solid-blue: you no longer need to be connected to other seeds, because you yourself are now sharing the entire file.
The beautiful thing about Bits on Wheels is the way in which it makes this process visually coherent. The first few times I tried it, I was mesmerized for up to twenty minutes at a time, watching the connections speed up or slow down as hosts came and went.
I don't think I really grokked Bittorrent until I used this app.
The one thing I would change about it would be to add RSS awareness. Or, to remove the mandatory "where do I save this?" dialog at open-time so I can add my own commandline RSS parser onto it, without having to learn AppleScript.
Mar 22, 2005 1:35am
rebloggin'
I'm Eyebeam's reblogger of the fortnight. This means that I spend a chunk of every day reading through Eyebeam's enormous base of subscribed RSS feeds, picking the choicest bits of information that I find particularly noteworthy/interesting.
As anyone who plays guitar knows, interesting things happens when outputs are connected to inputs:

That's a Slate article about "newsmashing" (reblogging, basically), posted to Jason Kottke's remaindered links, reblogged by me, re-reblogged by yatta at unmediated, found in my RSS reader, and currently re-posted here. I'll refrain from re-re-reblogging it even though I can.
Mar 20, 2005 10:29pm
e-tech, done traveling
I returned from e-tech a few days ago with a wicked cough. We were comped at the last minute by Nathan Torkington, who also extended an invitation to present our MoveOn national town hall at this summer's Where 2.0. More on that later. It was my first time at the conference, and was truly a blast.
Some highlights:
- George Dyson's talk, Von Neumann's Universe. This was an inspirational look back on the history of computing, through the eyes of an historian and family member of the tight circle of mathematicians and physicists responsible for digital computing.
- The BBC presentation (Tom Coates, Matt Biddulph, Matt Webb and Paul Hammond) describing experiments in SMS-driven playlist selection. Remarkable less for the technology presented, and more for the difficulty I had in imagining a bottom-line-driven U.S. media conglomerate donating the same effort to skunkworks-style experimentation resulting in actual air-time (10 hours!).
- Cory Doctorow's talk, All Complex Ecosystems Have Parasites. Cory practically phoned this one in, but the message about learning to love chaos in a vibrant internet is an important one for would-be regulators to understand
Some Not-so-highlights:
- Jason Fried's talk on Basecamp and Ruby on Rails. The IRC backchannel was truly merciless during this one, most likely because it was a peppy sales pitch completely innappropriate for the context. Basecamp and RoR are both supposedly pretty great, but prefacing almost every sentence in a presentation with "Do..." or "Don't..." is an awful way to address a technology-aware audience, especially if you use constructions such as "Don't worry about [technological concern], except when you have to." Thanks... knowing when you have to worry about something is the the hard part.
Actually, that's the only low point for me. Overall, a fantastic experience.

Mar 15, 2005 6:50am
the gates: memory blog
I added a few words to the Gates Memory Blog today.
... When I look at the 2,000 images that have been submitted so far, I'm amazed by the formal games you can play. Photos of the same place, or photos at the same time. Iconic viewing angles. Single gate against blue sky. Saffron fabric against sunshine. Rows of gates receding to a vanishing point. Rows of gates crisscrossing the frame. Gates framing people. Gates framing other gates. Gates photos in a pile, gates browsable by tag. ...
Mar 14, 2005 3:38pm
off to e-tech
I'm heading to San Diego tomorrow morning, to catch two days' worth of O'reilly's Emerging Technology Conference, thanks to a windfall last-minute comp from Nathan Torkington.
Mar 11, 2005 3:47am
latest moveon event
MoveOn used Stamen's collaborative mapping software again tonight, with an online town hall meeting that featured calls from Howard Dean, Senator Harry Reid, and Adam Ruben.
It was great to hear two things:
Recognition of linguist and cognitive scientist George Lakoff's ideas about self-aware language usage in politcal speech. It's not a matter of arguing your point, it's a matter of framing it to drive home the underlying values. Social justice, in the case of Dean's talk.
Black box Voting: It's about time this country took voting technology seriously. Dean mentioned the specific example of Oregon, which requires that all voting technology used in the state supports manual recounts. This issue has been covered extensively in such forums as Slashdot, and it's really pretty simple. How is it that national elections in the US have been twice marred by "irregularities", while a low-tech purple-thumb in Iraq ensured that no voters were able to defraud the system?
Agh.
Mar 8, 2005 6:58pm
json-php and mappr updates
Two things I did with my unusually productive morning:
- Created a Yahoo! group for my JSON-PHP project, at Matt's suggestion.
- Added Worldkit-style geo: tag support to Mappr.
Mar 8, 2005 2:25am
in l.a.
On Thursday night, I had got to get up in front of a large auditorium full of people and talk about our work, for the second time in my life. The event was the launch party for USC's IML Vectors Journal. We worked with Erik Loyer to develop two of the journal's interactive articles, The Unmaking of Markets and Narrating Bits. My In The News project from last year was also included.
I get incredibly apprehensive in front of crowds: palms sweating, blood rushing, frantically scribbling a few notes so I don't blank, trying to picture the audience naked. When Andy and I first performed as BiPole, I spent the first 5 minutes of the set freaking out trying to replace a dead co-ax cable, and the remainder sweating while he pounded out a significantly more gabber-oriented set than I expected. Somehow, my up-front crowdfear and anxiety usually gives way to complete contentment by the time everything's over if I'm able to find a drink. It seems like the proper way to handle fear of speaking in front of groups, is to do it often enough that it becomes second-nature.
The biggest advantage of doing these things is that you inevitably meet the most interesting people afterwards. We were approached by Bob Stein from Future of the Book who had some nice things to say about Mappr back in January. We also got to visit Julian Bleecker at the ZML (URL MIA) where he showed some of his wi-fi art/tech projects.
Eric and I have been talking a bit about resurrecting 16thandmission, and a few of Julian's ideas about place-specific wireless access sound like a good fit. I don't know if the plaza at 16th and Mission has any signal now. Providing freebie coverage may help further rid the location of its junkie-stigma, especially since the city has recently rebuilt the square, and provided brighter lighting. We wouldn't be able to install any wi-fi equipment on-site, but our office is across the street, and I'm sure that there's a way to set up a reverse-cantenna for saturated directional coverage, instead of reception.


Feb 24, 2005 5:04pm
ajax, again
Ajax seems to be the new official term for remotely-scripted web applications, in the few days since JJG published his paper on the topic. Lots of predictably-acerbic commentary from slashdotters, pointing out that this is just new name for an old idea (and a fantabulous e-term to boot). The story with JJG's post is not that Ajax is new, but that there is now a two-syllable term that encompasses an emerging development pattern. In other words, this is news for business people, not developers.
In a narcissistic moment, I was curious whether anyone was finding my website on the search term "ajax", and found this instead:
Feb 24, 2005 4:59pm
new york, day 2
I'm starting my second day in New York today. This city is amazing - it feels like San Francisco did when I first showed up there in 1995. A surprise lurking on every street, a complete change in feel from neighborhood to neighborhood. I could live here, for sure. Yesterday I spent most of the day at Eyebeam's DUMBO space, with the 12th-floor view of the Brooklyn and Manhattan bridges. It was cold as hell. Visited Peter in Williamsburg ("Billburg... don't call it Billburg"), with the 6th-floor cell tower-studded warehouse roof view of Manhattan and Williamsburg bridges.
Feb 21, 2005 6:28pm
ajax: a new name for an approach to web applications
Jesse Jame Garrett of Adaptive Path just published an article about web applications development called Ajax: A New Approach To Web Applications:
Google Suggest and Google Maps are two examples of a new approach to web applications that we at Adaptive Path call Ajax. The name is shorthand for Asynchronous JavaScript + XML, and it represents a fundamental shift in whats possible on the Web.
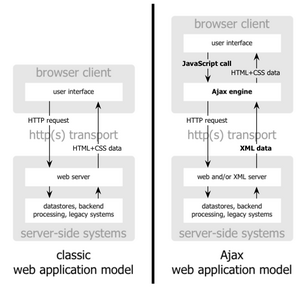
It's a nice recap explaining the interesting new possibilities allowed by XMLHTTPRequest in browsers such as Mozilla, Safari, and IE 6. We've been using it to add full keyboard navigation to an upcoming release of ReBlog. The X in the name may be a little presumptuous: often, generating and parsing XML is a pain. JSON is a nice alternative, using Javascript's native object representation syntax to send data that can be parsed by eval() in one step.
I'm not sure how I feel about the coining of a proper name such as "Ajax", and its use in contexts such as "Ajax engine." It's always helpful to identify and describe patterns in development, but this usage implies a brand identity and productization that just doesn't exist. In its defense, Ajax is way easier to type.
Still, it's amazing how much expressiveness has been introduced into web transactions with the introduction of a simple mechanism for in-flight HTTP requests. Writing applications in this style raises a few interesting questions, especially: where does it stop? With two methods for performing HTTP transactions, it's good to know where to use regular page reloads. Ajax introduces some confusion into traditional application designs: if you're using a pattern like MVC to design your server-side code, Ajax now gives you two views and two models, where the server's view is the client's model. This is weird. Flickr gets this right, using in-page requests for small, local tasks like updating image titles or descriptions.
Feb 20, 2005 9:17pm
heading for new york
I'm leaving for New York in two days. I'll be there for a week, working with Eyebeam, checking out The Gates, and visiting friends. I also want to see the new MOMA. Any advice on things to do?
Feb 19, 2005 12:14am
small update to json-php
I made some edits to JSON-PHP, with the gracious assistance of Matt Knapp. JSON-PHP is my implementation of JSON, a lightweight data-interchange format specially adapted for use with client-server javascript communications with XMLHTTPRequest. The change handles a few edge cases involving encoding mixed-index arrays, trading nominal type consistency for a less lossy representation of data.
Feb 17, 2005 5:57pm
tracking google maps
Mikel Maron has written a javascript extension to Firefox that allows arbitrary XML to be applied to Google Maps. Here's my trip into work this morning:
(Or here, if you've got Firefox and Greasemonkey)
Feb 16, 2005 7:39am
nietzsche on design
Via Thomas:
When one has finished building one's house, one suddenly realizes that in the process one has learned something that one really needed to know in the worst way -- before one began
...Kind of like how I spent a significant portion of 2004 building a room at my old warehouse, only to finish and decide that I was no longer interested in communal living. Oh man was it gorgeous, though - 3 stories up, balcony, right by floor-to-ceiling warehouse windows with roof access for tomato-growing on the edge of the ghetto. When Jack Dangers and Ben Stokes performed at the house last year, they called it "the treehouse."
Feb 14, 2005 8:07am
indie rock pete
From an essay on UltraGleeper, a Codecon presentation on web page recommendations, which I missed:
If you want best-sellers you can check the best-seller list. In my opinion, a good recommendation engine must have an element of anti-popularity. I implemented this in the Ultra Gleeper with something I call the Indie Rock Peter Principle, named after the comic strip character Indie Rock Pete, who has a kind of sadomasochistic relationship with popularity. The IRPP stipulates that beyond a certain point, additional recommendations (i.e. incoming links) decrease a page's score instead of increasing it. Not only does this clear the ground for real surprises, it acts as an additional, probabilistic filter for pages you've seen in casual browsing. Anything it misses will probably show up within a couple days in the weblogs you read.
Brilliant. (emphasis mine)
Feb 14, 2005 2:42am
codecon 2005 recap
We presented Mappr at Codecon 2005 yesterday, and I think it went pretty well. I wanted to go check out a few of today's sessions (notably Wheat and Incoherence), but circumstances prevailed against me, and I was only able to attend the Google reception Friday evening and most of Saturday's talks.
We were asked a few great questions, which I'll summarize here:
A few participants asked about the possibility of open-sourcing Mappr, or at the very least clarifying the licensing terms on the website, so decompilers would know what they were permitted to do, before doing it anyway. Clearly, we'll need to be more up-front about the terms for using the client-side map code, though this a question probably best asked of Tomas, who wrote it.
The open-source question is an interesting one, as it applies to web services. The GPL has addressed the licensing issues around machine-readable computer code, and Creative Commons has done the same for creative works, where derivative works and attribution are an issue. Web services are still a fairly major gray area, especially in the case of Mappr:
- We don't actually own most of Mappr's data, since the photographs you see on the site are all there courtesy of the original photographer, subject to their terms, and served up via Flickr. If Flickr were to shut their doors, Mappr would disappear as well.
- The geographical data we use to make our location guesses comes from US Government sources. It is public-domain, but it isn't "ours" in the strictest sense either.
The value Mappr has (and there must be value, for something to be licensable) is in the work it does, the service it performs. In a sense, a webservice is like the blue-collar worker of the 2.0 web, paid hourly for work done rather than salary for ideas generated; it's a role that resists easy intellectual property pigeonholing. What aspect of Mappr could be open-sourced? The client code, obviously, but this is in some ways the easiest part to reverse-engineer. The server-side location matching heuristics could be open sourced, but that wouldn't be worth much without the formatted place information culled from various sources. The photos themselves aren't ours to license.
One participant asked about explicitly geo-tagged images. This has been brought up before, and Flickr has just made this a lot easier by opening up EXIF data in their API. They still don't provide a way to search on EXIF, and I strongly suspect that not very many photos in the system have geo data in them.
I would approach the task of using explicit geo-data by merging it with existing place-name data: I would define a new type of relationship in Mappr ("Mappr believes this photo is near...") based on the closest named place to the photo's latitude and longitude. I would also allow for alternate ways to specify this information: EXIF is voodoo to a lot of users, and inaccessible once the image has been uploaded. It should be possible to expand our range of mappr-recognized tags to include something like "mappr:latitude:12.34". This has been brewing for a while, and Flickr's EXIF hooks are one additional fire under my ass to get it done.
Alon Salant's Photospace project, presented right after ours, handles the explicit geolocation issue nicely by providing for local maps and using RDF to link GPS tracklogs to terraserver maps. It's a little technically hardcore for Flickr users, I think, but definitely the approach of choice if you are interested in rigorously-specified locations for images. There were questions about our learning and feedback mechanisms. For example, if photos tagged with "Concrete" are consistently misplaced into Concrete, WA (ironically, the photo we currently have for that location is actually intended to be in Concrete. Try duck), how can the system learn to disassociate these tags? Right now it's a manual process: I mark placenames "Gary" or "Reading" as commons words or names that may not actually be placenames. Implementing any type of automated learning system is pretty far out of my reach right now, though I do have a copy of AIMA on my bookshelf that may help with this.
Er, that's it. Go Codecon!
Feb 11, 2005 10:52pm
flickr folder action
A couple of months ago I had the idea that it would be possible to use the OSX Finder to automatically (or "automagically," as the old Sysadmin term went) upload photos to Flickr when my camera was attached to my Mac, with no involvement from me. The logic went like this: 1. Flickr can get uploads from a UNIX command line 2. AppleScript can issue UNIX commands 3. the Mac Finder can automatically execute AppleScripts when a new object appears in a folder (a Folder Action) 4. Folders are created in the /Volumes directory whenever a new volumesuch as my camerais mounted
Feb 10, 2005 7:55am
newsburst busted
Feb. 15: I just got a mail from CNet apologizing for the brief bugginess, and assuring me that Newsburst now works on a Mac. Sure enough, I'm logged in and trying it out.
CNET News.com is launching a Web-based RSS news aggregator called Newsburst. The site, now in preview, will compete with Bloglines and Rojo. CNET's move comes on the heels of the LA Times and Guardian, which launched desktop RSS readers last week. This is the beginning of a trend where the big media launch branded RSS aggregators to make sure they retain reader loyalty.
It'd be a much more effective trend if the developers of newsburst had bothered to make the signup form work on a Mac. It doesn't even work in Firefox, so I wonder whether this is an MSIE-only thing. Come on guys, it's a couple of pull-down menus - get your act together and stop trying to be all javascript-crafty.
Feb 6, 2005 8:38pm
spy list leaked
from Slashdot:
"A list of 240,000 names of Polish secret agents, informers, secret service employees, and victims of persecution was leaked on the internet in the last days and became an instant hit. The search for "lista Wildsteina" (Wildstein's list) sky-rocketed to 300,000 per day in the second most popular search engine in Poland (onet.pl) outperforming "sex" (former top query) by more than 30 times. The list appeared on many web sites, p2p networks, and was made into a searchable database. There are worries the list might contain names of active security agents, still working abroad. Google news has more coverage."
Feb 2, 2005 4:05pm
mappr is under the gun
A string of links over the last few days have slowed mappr to a crawl, and I had to shut it down for a few hours last night so Eric could present it at Meetup in NYC.
Mappr is quite literally a snapshot of the nation. Actually, it's lots and lots of snapshots. ... click on a photo and Mappr will tell you just how confident it is that it placed the pic in the right location. We're confident you'll find a surprise at every click.
Sometimes the best way to figure out where you are is to simply look around. Mappr lets you look at the U.S. and points nearby through the eyes of photographers kind enough to submit their snapshots to the site. The geographical interface to these casual (often very casual) snaps is wonderfully addictive if you let yourself worry less about the destination and more about your glimpses on your way there.
K10K:
If you're a fan of Flickr Check out Stamen's : Mappr - a visual mapping of flickr's photocoupage. (tipped by Tomas!)
So that's why it has been sluggish since yesterday morning. CPU load has been hovering at around 5.00, hitting highs of 10.00 yesterday. The default recent photos search takes days, but tag-specific searches like "sign" or "red" work pretty quickly, and are more interesting anyway. :)
Jan 28, 2005 7:31am
iron curtain west
How unfortunate, I would've liked to hear Laurent Garnier play, (Ruby Skye notwithstanding). Instead I'll just continue listening a few of his recorded sets. Via Dusko:
LAURENT GARNIER TOUR CANCELLATION STATEMENT
LAURENT GARNIER US TOUR DATES: Fri March 4 SF Ruby Skye CANCELLED, Sat March 5 LA Avalon CANCELLED, Mon March 7 NY Cielo CANCELLED
I am very sorry to have to cancel my forthcoming U.S. tour due to what I consider to be completely unreasonable demands by the U.S. Embassy in France in order to renew my work visa.
In order to obtain this new visa, the rules have once again changed since November 2004 and I would now have to not only fill out an exceedingly probing application form, but also be interviewed by a member of the Embassy staff, and provide proof of ownership of my house, details of my bank account, my mobile phone records, personal information on all my family members and more. I consider these demands to be a complete violation of my privacy and my civil liberties and I refuse to comply.
I am horrified by these new regulations and feel really sad that this is what some call freedom and democracy.
It has now become almost impossible for an artist to come and perform in the United States. And until this new proceedure changes I will unfortunately refuse to comply with this nonsense.
Thank you for your understanding.
Laurent Garnier
Jan 27, 2005 8:13pm
completely floored
I'm in awe:
What kind of company has the time, money, and testicular fortitude to photograph every single block in ten major cities and hook the whole deal up to a yellow pages search? Amazon apparently.
Update, this was probably inevitable:
So, I entered a local pizza joint's name. Search came up with it along with a picture of the store front. I clicked on the "walk up and down the street" arrows to see what else they had. And I keep clicking down the block when I see THE ENTIRE SEPOY HOUSEHOLD on amazon.com!! It must have been sometime in October and we seem to be returning from lunch. Maybe a sunday? How massively weird is that?!
Jan 25, 2005 6:11am
here comes the infocloud

According to Wired (and Slashdot):
In Austin, Texas, a colocation company is building a low-cost data center out of dozens of Mac minis. Underwriters Technologies' Mac mini colocation is housed in Austin's Data Foundry facility, a former bank vault where space is at a premium. Because the Mini measures only 6.5 inches square and is 2 inches high, Underwriters can cram a standard server rack with three times as many minis as full-size servers.
The colocation side of this interests me less than the plain fact that Minis are already being thought of as servers. Thomas Vander Wal has an interesting term, personal information cloud, to describe the bits of data such as phone numbers or to-do lists that seem to belong on cell phones, PDA's, stacks of index cards, and other such pocketable items.
My experience with setting up my Pair account to handle my mail, my website, my del.icio.us-like personal bookmark system, and a bunch of other stuff has led me to think that the best residence for the info cloud may ultimately be on a device such as the Mac Mini, plugged into a home DSL connection rather than colocated in a server room. Most of the needs listed above can be handled elegantly by open source software, and can probably be commoditized enough for Apple to slip them into OS X at some future date as an extension to iLife. The colocated server is pretty abstract, but combine a machine you can see in a place that you know with a .Mac-provided dynamic DNS, and the Mini becomes an ideal storage unit for your networked stuff ("stuff" here is used in the same context, and with the same implied meaning, as Iomega's hugely successful Zip drive ad campaign from, like, forever ago).
Apple has really opened the floodgates for computer contexts that treat the machine as an appliance instead of office equipment. It will be interesting to see all the use possibilities that arise from cheap, small, beautiful machines serving mail, music, movies, pictures or journals.
Jan 25, 2005 2:04am
bitman video bulb

Indescribably cool.
This tiny device plugs directly into an RCA jack, and pumps out a constant stream of "bitman" dancing to any TV, VCR, whatever. I'm in love with the idea of video so compact it can fit in this form factor, and content that is completely static. I can imagine an adaptation of this concept, that contains some sort of environmental sensor (audio, temperature, whatever) and creates environmentally-appropriate graphics with no clunky storage or transmission medium.
Jan 23, 2005 5:22am
on development frameworks
I've been following the chatter about Ruby On Rails for the past few months with some interest: I'm primarily a PHP developer because it's the first language I learned in any serious capacity, and has continued to serve me well for five years running. My ears always prick up when I hear about someone's favorite development environment, so I occasionally buy books on topics like JSP, Python, or even Lisp to keep myself informed on what I've been missing out on, and whether it's time for a switch.
Today, Jason at 37Signals posted a pithy response to Geert Bevin's criticism of RoR, and I feel as though something may have been lost in the shuffle. Geert makes two good points about development frameworks:
It's utterly ridiculous to compare how long it took you to bash a simple application together. ... I think that driving a web application from a database structure is totally backwards.
...which reminds me why I always seem to stick with PHP, no matter how good the books I read sound. RoR's breathless evangelism shows how fast and easy it is to write a web application, but glosses over two reasons that I shy away from frameworks-du-jour:
- Frameworks are often advertised on the basis of their design philosophy, and seem to promise that this will effortlessly translate into elegantly-architected applications. Not so: any framework flexible enough to handle all the potential situations in which it may find itself will also be flexible enough to support terrible design decisions on the part of its users.
- Design is what happens after a framework or environment has been chosen. PHP is often derided as a primitive or childish language, but I've found it flexible enough to support pretty much all the weird stuff I need it to do with a minimum of fuss, which includes building personal frameworks not unlike RoR.
If I were man enough, I guess I'd be a Perl guy.
Jan 19, 2005 6:47am
more freeway interchanges
Via pasta and vinegar, I came across these stunning drawings of nonexistent freeway interchanges today. They tie in neatly with my collection of bay area freeway interchange photographs.


Jan 17, 2005 6:58pm
announcing map_projection, sort of
I've been using a small library of PHP code to do my map projection math for some time, since I started using the Lambert Projection in preference to the much simpler Mercator Projection. The classes I wrote to simplify this process are described in more detail here, and available for free (beer + speech) from PEAR.
They were posted some time ago, but I'm coming to terms with the fact that I'm not going to have the patience to see the PEAR package approval process all the way through, and that a thoroughly-vetted, much-used package still technically in the "proposal" phase is plenty good enough.
Jan 17, 2005 4:29pm
write back
I've added Blosxom's "writeback" plug-in, so it's now possible to leave comments and such here directly (see "responses" link in each post footer). In the past, I've preferred to get mail directly, but interesting conversation seems to be moving to the web in general, so it's about time this site was a little more dynamic.
Jan 13, 2005 7:30am
a little more mappr
Oh and mappr got metafiltered today, which was a nice surprise. Wish they'd have waited two days for the dynamic version.
Jan 13, 2005 7:28am
malcolm gladwell and james surowiecki
Two of my favorite New Yorker writers (the others are Anthony Lane and Adam Gopnik) are currently engaged in a weeklong conversation about their respective books, Blink and The Wisdom Of Crowds. I don't have the attention span to follow this one blow-by-blow, but I plan to pay close attention when they're done.
From worldchanging:
...a public conversation/debate between James "Wisdom of Crowds" Surowiecki and Malcolm "The Tipping Point"/"Blink" Gladwell is still pretty interesting, at least for those of us interested in social networks, framing and memes, group behavior, and cultural change. Surowiecki and Gladwell are two of the best-known social observers around right now, and they both make trenchant observations apt to trigger cascading aha! moments for readers
It's immensely gratifying to have seen the New Yorker explode with vitality and significance since I started subscribing five years ago. When I read my parents' issues as a child, I generally checked only the cartoons, and had a fairly strong view of the magazine as a bit of a wash-up.
I still hate the fiction.
Jan 9, 2005 8:49am
folksonomies and synonyms
Folksonomies are the current hot topic in information organization right now, but Louis Rosenfed points out an important drawback to their use:
Folksonomies are clearly compelling ... but they don't support searching and other types of browsing nearly as well as tags from controlled vocabularies applied by professionals. Folksonomies arent likely to organically arrive at preferred terms for concepts, or even evolve synonymous clusters.
Louis goes on to predict that Flickr, del.icio.us, and other folksonomy-dependent sites (uh, what other folksonomy-dependent sites?) will have difficulty scaling as volume gets out of hand. This is a moot point, volume is already out of hand, and they've scaled fine.
His point about synonyms is a great one, though, and is pointedly ignored in Clay Shirky's rah-rah response. Folksonomies are unlikely to evolve synonyms for the simple reason that people will usually choose just one of the many synonyms available. For example, self portraits on Flickr are usually tagged with me (15,396 photos) or selfportrait (2,150 photos), but who tags their photos with both? Right. So the overlap just isn't there to be able to infer that these two terms are synonymous, just like people tend to use one preferred name for a place with names in many languages, or one preferred name or nickname for a person in particular contexts. We just happen to be in the early stages of a project that hopes to use folksonomies and user-generated meta-data to make sense of free form conversation, so this is going to turn into a bear of a challenge.
(Addendum: there are a few words about this subject on David Smith's site)
Jan 7, 2005 3:19am
bill thompson is wrong
I know it's fashionable to be an iconoclast and all, but this article called "Dump The World Wide Web!" is just silly:
But enough is enough. Just as it is sometimes necessary to demolish old buildings to make way for new, so it is time to move on from the web. It isn't as if we need to look far for an alternative -- we've had one since 1990 when the web was just starting to emerge from CERN physics lab. Its called "distributed processing" and it enables programs to talk to each other in a far richer, more complex and more useful way than the web's standards could ever support.
Yawn.
Here's where I think Bill errs:
- The Web was conceived as a pragmatic approach to a publishing problem. The reason that Berners-Lee's work took off like it did was because it was so basic anyone could understand it and get to work: "When Tim Berners-Lee created the Web he wanted a simple text-based publishing tool for the high-energy physics community, and a simple markup language that let authors specify headings and link to other documents was fine." The World-Wide Web got the cold shoulder from the hypertext community, and it lacked the academic polish that other, more Correct applications had. Nevertheless, as Jason Kottke says, here we are. Any argument founded on the idea that the Web is not good enough because it isn't complete or correct enough is highly suspect, because academic correctness was never the point.
- Bill invokes Microsoft's initial focus on the AOL-like Microsoft Network as evidence that the Web wasn't worthy of attention. Microsoft did not ignore the Web, it tried to ignore the whole Internet, and it did so for economic reasons rather than technical ones. "(Microsoft) never liked the Web and it was only the horrible realisation that every company, every net user and every competitor was going to invest a vast amount of money, effort and resources making it seem like it worked that forced Bill Gates to turn the company around and give it a Web focus late in 1995." That just sounds like the same old M.O. from Microsoft, where new technologies are watched from afar until they prove profitable, then seized wholesale after the difficult pioneering work has been done by others. Fortunately, the Internet isn't a thing, it's an agreement, so it wasn't a market that MS could monopolize.
- Bill contends that such services as news publishing or e-commerce would be better served through the creation of special-purpose protocols and applications, rather than general-purpose browsers, and cites the use of mail clients as evidence that special clients for special content are acceptable. If Bill were writing an article about why we should dump e-mail, I suspect that he would be arguing that advertising mail deserves a special program separate from personal mail. I submit that any new publishing or information service which doesn't use a general-purpose browser faces an uphill battle, and if it doesn't reduce published material into a widely-readable and easily-writeable format like HTML, it had better have a damn good reason for valuing solipsistic correctness over convenience for end-users. RSS is the only example I can think of that might validate Bill's point, and even that is served over HTTP because it's a convenient delivery mechanism.
Anyway, I'll let Stewart Brand have the last word:
Starting anew with a clean slate has been one of the most harmful ideas in history. It treats previous knowledge as an impediment and imagines that only present knowldge deployed in theoretical purity can make real the wondrous new vision. (The Clock of the Long Now, page 74)
Time for a shower, I feel like I've been trolled. Enjoy this refreshing bit of optimism about the Web from Adam Rifkin.
Jan 4, 2005 9:16pm
ahoy, ahoy
Courtesy of Interconnected, excerpt from 1999 NPR interview with Allen Koenigsberg, professor of classics at Brooklyn College:
I think I've actually determined the date and location of the invention of the first `hello' badge, which was in 1880 at Niagara Falls, which was the site of the first telephone operators convention. And I found the minutes of the meeting, and in there he's very proud to see that they're all wearing their name tags. And he says, `We have a new word to go on our name tags, the word "hello."'

{kind=link}
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski