tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Jun 15, 2007 2:08am
notes on api authentication
We've been thinking a lot about authentication recently, both as consumers and designers of web API's. Although certain best practices in this area are being solidified, I still think it's a wide-open field for experimentation. This post is a run-down of various patterns we've encountered for authenticating applications and users, and has been greatly helped along by conversations with Shawn, Steve, Matt, and others.
Keys
The simplest application authentication method is the developer key. Flickr has been using these since day one, and they mostly help in monitoring usage. Generally, the idea is that a site issues a unique key to each application consuming the interface, and then requires that this key be passed along with every request. Keys are not expected to remain secret or be subject to rigorous control, but they do help Flickr keep tabs on how applications use the API, and provide a way to find someone to blame when requests with a given key cause problems. We used to routinely get mails from Stewart about Mappr's (ab)use of expensive search parameters.
Flickr's API keys are explicitly connected to Flickr accounts, and are issued via an application form that asks for a description of your intended use and a promise to abide by the terms of use. There's also a monitoring page that displays your own API usage:
When we designed the Digg API, it was decided that key enforcement was not a high-enough priority to warrant the overhead of administration, so we went with a simple form of consensual disclosure. Digg application keys must be provided, must be in the form of a valid absolute URI, and should point to a page that describes the application. The URI isn't checked for normal usage, so it's possible to experiment and play with the API with minimal hassle.
Tracking keys is enough of a hassle that companies like Mashery have popped to provide this as a service.
Usernames, Passwords
Authenticating individual users is more sensitive, especially when an API provides read/write methods for posting new information to a user's account. The easiest way to authenticate this is to require that a user's account name and password be attached to requests.
The original Del.icio.us API required HTTP basic authentication for all methods, including the ones that returned information available on public, anonymous web pages in the application. Basic auth is well-understood and reasonable well-supported, so this made it quite easy to write tools that used the API. The major drawback of this method is that account passwords can be sniffed on every request, making them wildly insecure. At some point last year, Del.icio.us began requiring that all API requests be done over HTTPS. This solves the problem of password exposure, but introduces a new problem: HTTPS is a considerable resource hog, and is expensive to serve. Cal estimates that the cryptographic overhead of HTTPS can cut a web server's performance by 90%. It is useful for HTTPS to keep the contents of an interaction secret where the data is sensitive, as with banks and medical records, but it's total overkill in the case of a typical web API.
A more subtle problem with asking for usernames and passwords is the inherent phishing risk. An API that can be operated with a user's permanent password is a magnet for potential abuse, because something you know might also be something someone else knows. Flickr's early approach to this problem was to ask for the user's e-mail address in the request, not their Flickr username. A sniffed API password would be useless for logging into the main website, and knowing a username and password wouldn't get you into the read/write API.
Digests
One way to deal with the risk of password exposure without touching HTTPS is digest authentication. This is a pattern that uses one-way hashing functions such as MD5 or SHA to hide a password in transit, while still allowing it to be verified by the API server. Generally, an API client will send the server a hashed combination of username, password, and possibly other details. The server can't deconstruct the hash, but it can make one of its own and ensure that the two are identical.
At one point, the Atom Publishing Protocol defined WSSE as its preferred form of authentication. A visitor from the miserable world of SOAP, WSSE defines a simple way to hash up the user's password, the creation date of the message, and a nonce ("number used once") for a bit of randomness. The hashed tokens are difficult to pry apart, and the method helps prevent replay attacks by enforcing recency (via the creation date) and randomness (the client makes up a new nonce on every turn). WSSE has come under a great deal of criticism due to its requirement that the password be part of the hash. No sane application developer stores passwords in cleartext, but WSSE requires that this be the case in order for the server to re-create the hashed token for comparison.
Amazon's web services define their own authentication protocol that borrows a number of advantages from WSSE. First, the value that the client hashes includes HTTP headers, the request body, the URL, and the date, among other details. Second, the instead of asking for an account password, Amazon assigns each API user a secret key for use in such hashes. The secret cannot be used to retrieve API user account details, and it can be invalidated and re-generated if the user thinks it's been leaked. Third, Amazon offers several ways to attach the authorization signature to requests, from packing it into special-purpose HTTP headers to tacking it onto the request CGI parameters. The latter method makes it possible to generate limited-use URL's for private data, allowing an Amazon API user fine-grained control over public access to stored data. Because use of Amazon's API is billed, these features add up to a sane way to ensure that it's difficult to rack up excessive costs on user's account.
Tokens
A useful response to the phishing risk of passwords is a limited-user token, a pattern I'm starting to see used more often in authentication schemes.
Flickr switched to this model some time ago, adding the concept of a secret key to be shared between an application developer and Flickr. The general pattern is that authenticating as a Flickr user to a 3rd party web application involves having that application send you to a page on Flickr.com, which accepts your user credentials and asks whether the requesting 3rd party application should be allowed to read/write data on your behalf. The application and Flickr share a secret key which is checked at this time. If you agree, Flickr will redirect you to the 3rd party application's authentication handling page along with a freshly-minted frob. The 3rd party application can then convert this frob to a token, which can then be used to perform actions on that user's account.
There are a few significant things going on here. First, only Flickr needs to see your username and password, which is great security. Second, the frobs and tokens are tracked by Flickr, so the permissions you've granted to the 3rd party can be revoked at any time. Third, the secret key means that an intercepted frob is not useful to an interloper.
Unfortunately, this also means that Flickr's authentication process is (in my humble opinion) a total fucking hassle (sorry Aaron).
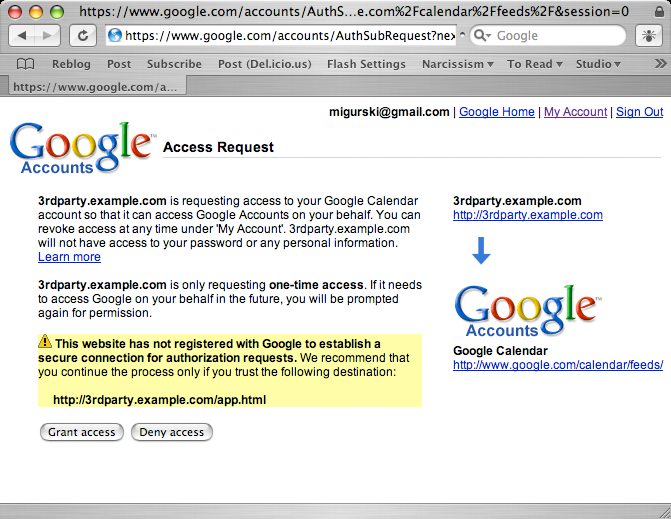
Google's AuthSub is a similar approach that I believe dispenses with some of Flickr's complications. Unlike Flickr, AuthSub does not require a pre-existing arrangement between the 3rd party application and Google, and there is no secret key. Instead, Google displays the authentication handler URL and domain name, and lets users determine whether they trust that application by name. The token sent by Google at this point (what Flickr calls a frob) is valid for a single-use, but can be exchanged for a session token if the user explicitly allowed this to happen. Tokens issued by Google can only be used for a limited subset of their applications, e.g. just gmail or calendars. AuthSub also agreeably allows for experimentation: it's possible to request a valid token without a publicly-viewable web application.
Google's access confirmation page looks like this:
Google rounds out AuthSub by providing a page in each user account that lists the currently-valid tokens and the web applications to which they've been granted. These can be revoked by the user on an individual basis, and offer a granular level of control over how their data is exposed and manipulated.
One potential security weakness in AuthSub is that the token may be intercepted and used. I'm not clear on how Google's web services use these tokens, though - it may be necessary to pair the token with some other piece of information that's harder to intercept, such as the user's Google account name.
An approach to keeping tokens secret that I've not yet seen in practice, but one that looks promising, is Diffie-Hellman key exchange. D-H uses a property of modular arithmetic that allows two parties to agree upon a shared secret over an insecure channel. The algorithm is roughly analogous to two people exchanging a box with two padlocks on it, keeping the box locked while in transit but not requiring either person to give up the key to their own lock. With a few extra round trips, the contents of the box can be exchanged securely.
This means that it should be possible to replace the open token transmission above with a secure exchange, resulting in a temporary secret shared between the API client and server, highly-resistant to sniffing.
Summary
I'm seeing a clear progression in API authentication from a two-party relationship between the application developer and the application user, to a three-party relationship between the application developer, the user, and the 3rd party needing temporary access to the application on the user's behalf, no doubt driven by the way popular applications are starting to treat themselves as platforms to be extended and built upon. One major recent entry that I haven't yet touched at all is Facebook.
Links mentioned above:
- Flickr API
- Flickr API developer key application form
- Flickr API terms of use
- Digg API
- Digg API application key requirements
- Mashery
- Del.icio.us API
- HTTP basic authentication
- Cal Henderson's book Building Scalable Websites
- Cornell CS 153 lecture notes
- Atom Publishing Protocol
- Amazon Web Services REST Authentication
- Google AuthSub
- Diffie-Hellman key exchange
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments
Sorry, no new comments on old posts.