tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Mar 30, 2007 6:24am
browser shims (lazyweb)
Last week I tried out Cocoa Dev Central's One Line Of Code Browser. It's an Xcode tutorial that shows how to create (from scratch) a Mac OS X standalone application with a text entry field, a fetch button, and a WebKit view - a complete browser in just one line of code. It's actually one line a code and a fuckton of clicking around in Xcode and Interface Builder, but their point roughly stands. I opened the tutorial when I got on BART, and had a running browser six stops later despite never having used Xcode before.
The promise of WebKit is that it makes possible a range of hybrid, web-on-the-desktop applications for prototying and deploying. Matt has tread this ground before, but it's worth repeating. Tom and I kicked around a few ideas for such applications over beers, but they hinge on the existence of open source browser shims for Mac, Windows, and Linux. This should be possible with WebKit, Explorer, and Konqueror or Firefox, but it's outside of my area of expertise. Does such a thing exist? Can it? I'm picturing and application kit that lets you specify width and height of the final window, pack in some html, css, and javascript, and pop out an executable for any platform that runs the resulting browser-in-a-box as a first-class application.
Mar 28, 2007 7:31am
space needle
Peacay has some amazing architectural renderings of the Seattle Space Needle and other attractions at the Century 21 1962 World's Fair.
I can't help but feel terrible for this guy, trapped deep in his dull office, hundreds of feet in the sky with no windows:

Mar 23, 2007 11:44pm
stamen in pingmag
We're heavily name-checked in Pingmag today, Infosthetics: the beauty of data visualization.
Mar 23, 2007 8:02am
oakland crime maps V: modest maps
One of the main tasks I needed to handle for my project with Oakland's CrimeWatch application (previous: I, II, III, IV) was a Flash-based display for maps of criminal events. Darren, Shawn, and I banged out what has now been released as Modest Maps. As it turns out, a whole bunch of other current projects needed the same thing, so development has been rapid over the past few months and we're now at a point we feel comfortable calling 1.0 beta.
![]()
Modest Maps is a BSD-licensed display and interaction library for tile-based maps in Adobe Flash 7+, written in ActionScript 2.0.
Our intent is to provide a minimal, extensible, customizable, and free display library for discriminating designers and developers who want to use interactive maps in their own projects. Modest Maps provides a core set of features in a tight, clean package, with plenty of hooks for additional functionality.
Future releases may include display layers in ActionScript 3.0 and WPF (Windows Presentation Foundation), but for now it's a kick-ass tile-display engine that can pull in map layers from a variety of sources.
Mar 13, 2007 5:02am
what to do when they don't
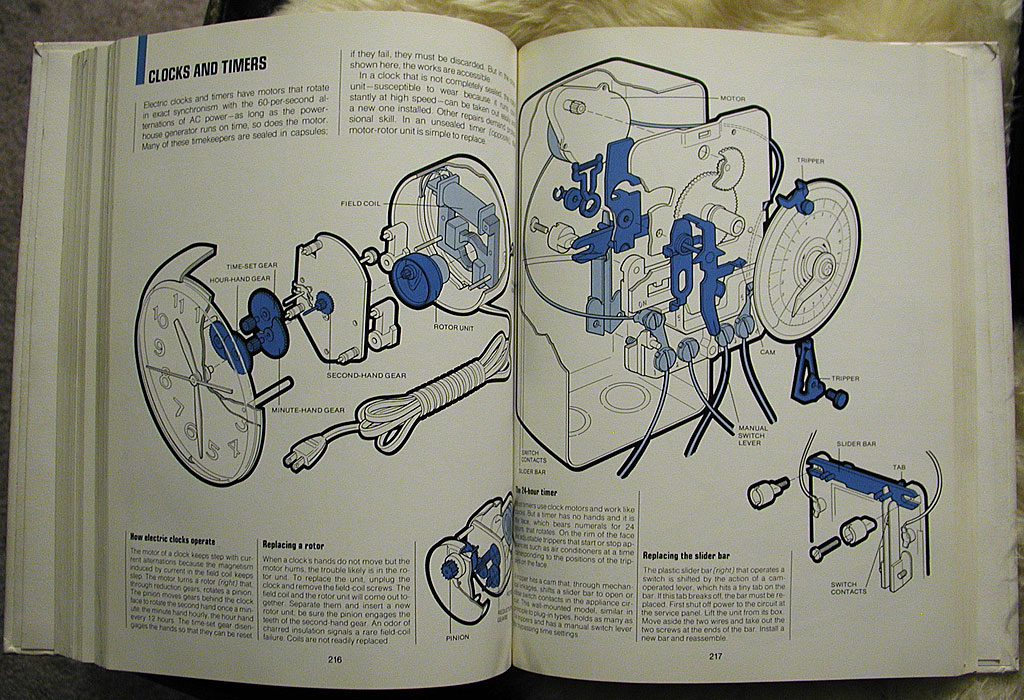
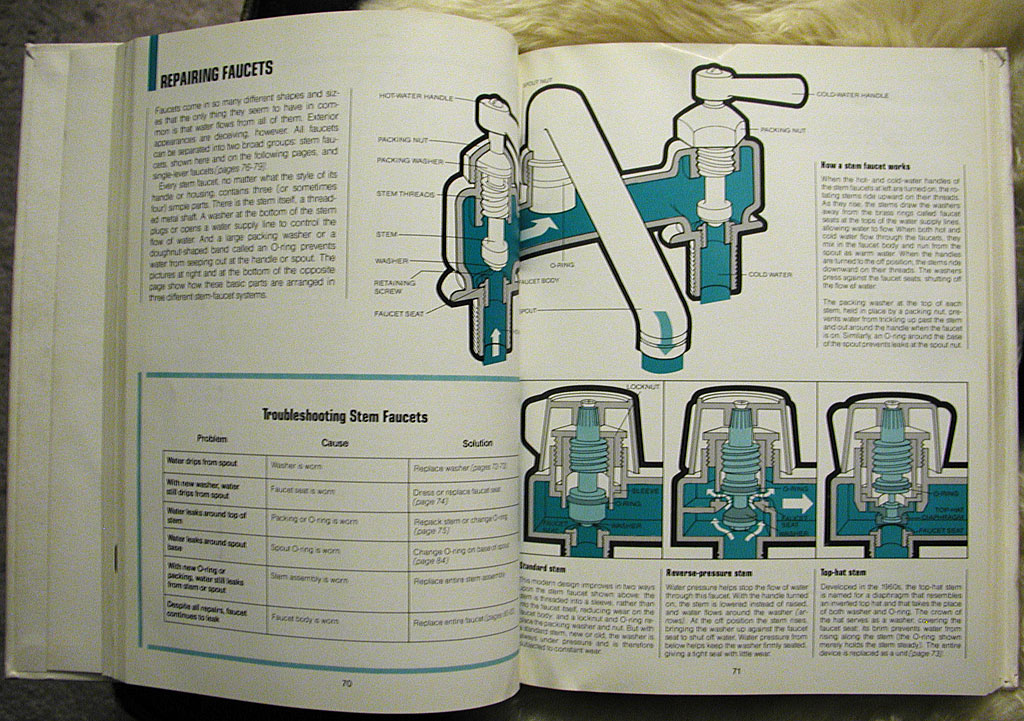
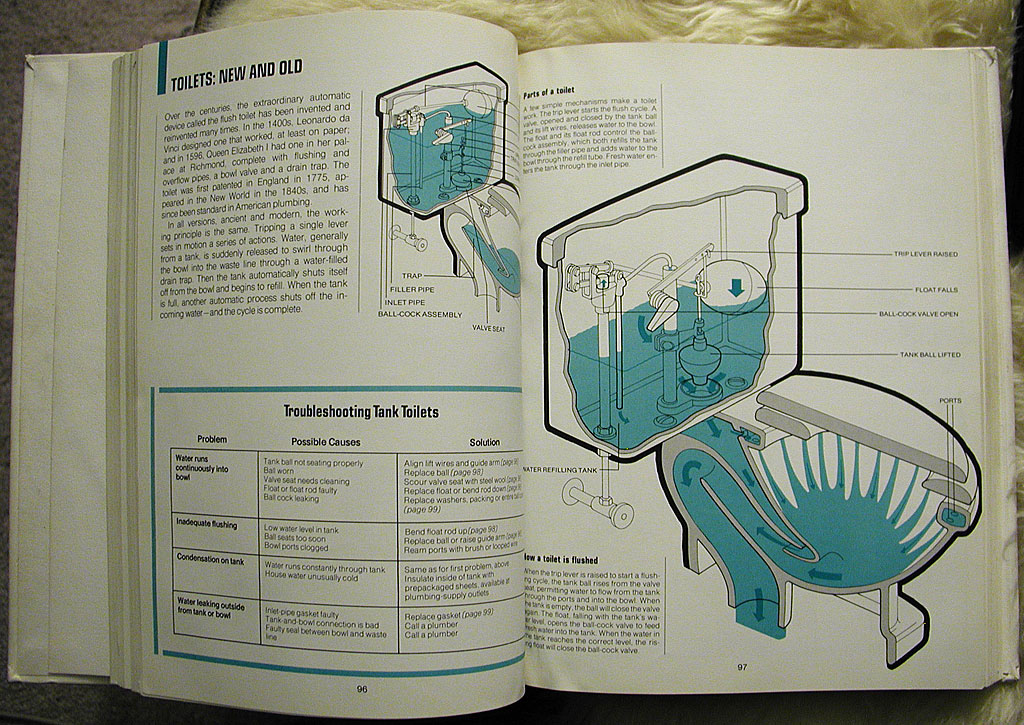
Someone in our building left a copy of How Things Work In Your Home (And What To Do When They Don't) sitting out on the "free" table. Gem brought it in before anyone could get their paws on it. It's a 1975 Time-Life book on repairing household items, and features detailed cutaways and exploded views of any kind of machine, gadget, or appliance typically found in a 1970's home.

Each chapter is identified by a single spot color that unifies it as plumbing, electrical, air conditioning, etc. The illustrations are detailed with a characteristic 70's "fat outline", and describe inner workings of motors and septic tanks.
Clocks:
Faucets:
Toilets:


Mar 7, 2007 1:32am
that was the winter of my discontent
After an overly-long, sucky winter, I'm back on my bike as of this past weekend. The leg still bothers me but it's nothing like the misery of December and January, when I slept on the floor for two months and was forced to scrape JPEG's to take my mind off the pinched nerve.
Mar 5, 2007 7:55am
more against openID
(This post is an expanded version of a comment I left on Josh Porter's blog)
I expressed my reservations about OpenID last month, and here I am doing it again. A recent post from Josh Porter made me think some more about why I believe OpenID is such a stillborn concept.
I'm actually pretty impressed with the technology behind OpenID, especially its distributed design and lack of dependence on any one point of failure. The core promise for users is the ability to coordinate sign-on credentials between sites, so you only need to remember one username/password combination. It does this by treating your URI (the location of your blog, or whatever) as your identity, and authenticating against that. The site to which you're trying to prove your identity (the consumer, I guess) contacts the URI that stores your identity (the provider), some encrypted magic takes place, and you get to leave a comment or upload a photo without having to remember another set of login details. So far, so good.
The problem with OpenID is that it violates one of the longest-runnings stories we tell ourselves about the Internet, from the famous New Yorker cartoon:

They do a great job of arguing that it's a legitimately open protocol, with no patent encumbrance or vendor sports involved. I have no reason to disbelieve them, but I also don't believe the openness of the protocol matters. The point where it fails is that your proof of identity is only as good as its perceived strength. When I was younger, getting into bars or buying booze for the under-21 people I knew meant having a fake ID, and it was commonly known that some states has shittier licenses than others. I forget which was which, but you were supposed to pretend to be an out-of-state student from a place where they used cheap laminate, no holograms, and common fonts on the ID itself. These were the ones you'd try to fake, and it was up to the bouncers and bartenders to decide whether your scuffed-up, delaminated card was a fraud.
OpenID suffers from this same problem, but I can see it leading to a chain reaction of lameness that brings us right back to where we are now, in terms of identity on the web:
- Let's say you set up your own OpenID provider, littleguy.example.com. This is the core of OpenID's openness: anyone can set up their own provider. They have a list, or you can make your own. The account or server where your provider lives may be compromised, but OpenID consumers have no way of knowing it. How can they be informed that littleguy.example.com is actually a wolf in sheep's clothing?
- Because it's difficult to know whose identity provider is secure and trustworthy, smart identity consumers who actually let you do stuff with your identity will exercise caution in choosing the OpenID's they accept. SomeBigCo might decide to not accept identities from littleguy.example.com, treating it like an easily-faked drivers license. This is the point where OpenID's openness stops being important: the protocol may be pure, but participants still have to decide whom they can trust.
- It's kind of a crapshoot to figure out why SomeBigCo refuses to accept your provider, so you follow Simon's advice and set up a SomeBigCo identity. The point of OpenID is to have just one, so that's the one you decide to stick with. Now, every time you use that identity to authenticate someplace, SomeBigCo gets to know. It knows about your SomeBigCo accounts, your OtherBigCo accounts, and all your LittleOrg accounts, which is immensely valuable marketing information. If SomeBigCo knows that I have a $50/month Twitter Pro account, I start to look like the kind of person who might pony up for other services. Maybe SomeBigCo sells this information because its shareholders demand it be monetized, or an employee with a meth addiction and a vendetta decides to sell it on the black market. Maybe SomeBiggerCo buys SomeBigCo to get their hands on it. The point is that it's worth money.
- Meanwhile, OtherBigCo is unhappy that SomeBigCo knows all this stuff about when its users log into their OtherBigCo accounts, so it decides to stop accepting any non-OtherBigCo identities. All the value in OpenID is in being a provider, as Microsoft discovered when Passport got nowhere with non-MS companies who didn't like the idea of giving all their user information to Microsoft for free. This is square one: Yahoo!, Google, and Microsoft will happily provide OpenID, but see no long-term sense in consuming it. Your "identity" becomes useless anywhere outside those walled gardens, except in its original use case: leaving comments on blogs.
This is as it should be. People who know me know that I like to kill off old accounts as often as I start new ones, so the permanence of a global identifier has no attraction for me. People who read Danah on teens and social software know that kids happily put tons of time and effort in creating, maintaining, and destroying online identities, so I don't put a lot of faith in the tech consultants whining about how miserable they are having to recreate their LinkedIn buddy lists on last.fm. People who use Mac OS X know that the whole "ZOMG too many passwords!!1!" issue can be dealt with cleanly and elegantly by client-side keychain software that stores your valuables on your own machine, where no one is tempted to sell them for marketing purposes except you (Root's big idea in 2005).
The ridiculous thing about OpenID is that it has no value unless loads of people buy in, which I assume is why there have been so many "we will support OpenID mumble-mumble" announcements in recent months. If it gains any traction at all, it's going to be just like the consumer credit system without all that pesky government oversight getting you a free personal report once a year and going after abusers. It's a cute technical approach to a big, hairy social status quo, and I'm sitting here writing a big-ass diatribe about it because I don't want to find myself forced into signing up for a SomeBigCo account two years from now and getting all my shit stolen or sold, ChoicePoint-style.
Mar 2, 2007 12:47am
oakland crime maps IV
Last month, I posted a few notes on possible displays of crimes in time. This post shows the small amount of headway I've made towards implementing the competing ideas of spherical vs. conical fields around crime events.
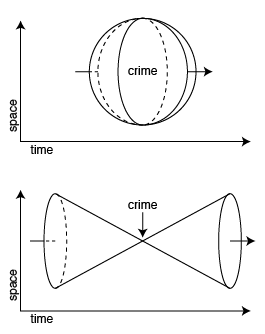
The difference between the two boils down to the shape of the three-dimensional field (two dimensions of space, one of time) that surrounds a criminal event. The sphere is centered on the event, and is largest in space when closest in time to the crime. The cone is smallest in space when closest in time, but ripples forward and back.
These are the results so far:
Spherical Fields
This was the initial idea, and it makes visual sense when animated. Drag the small gray slider at the top of this image back and forth to see how it works:
See a larger version of this view.
Red circles show a crime that is yet to happen, while blue circles show a crime that has already happened. The black dot in the center is visible only inside the sphere.
Conical Fields
Cones were the second idea, inspired by a conversation with Adam Greenfield which suggested that a ripple or light cone was a better visual metaphor. Here, the red circles start out large and converge or focus down to the crime before expanding again in blue:
See a larger version of this view.
The most confusing aspect of the conical version is that it still reads as big = close, which is not quite right. It should read as focused = close, so Eric and I experimented with a blurs to better suggest that the event is coming into and out of focus as you slide back and forth in time:
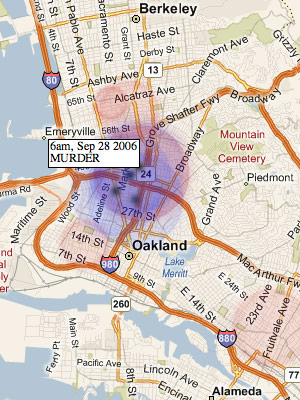
There are two versions of this interactive piece to play with full-screen, showing murders and prostitution. The second one is interesting, because it shows that prostitution arrests in West and East Oakland (along San Pablo and International Boulevards) occur in waves. The two areas are relatively quiet for days or weeks, then suddenly get hit with a block of arrests. I'm guessing this is due to planned and coordinated OPD vice squad activity. You can see examples of such waves on February 15, January 18, December 20, and December 14.
Mar 1, 2007 7:50pm
ichat san franciscoes
It took three people five minuets of staring and comparing to realize that the top image was upside-down, and needed to be flipped:
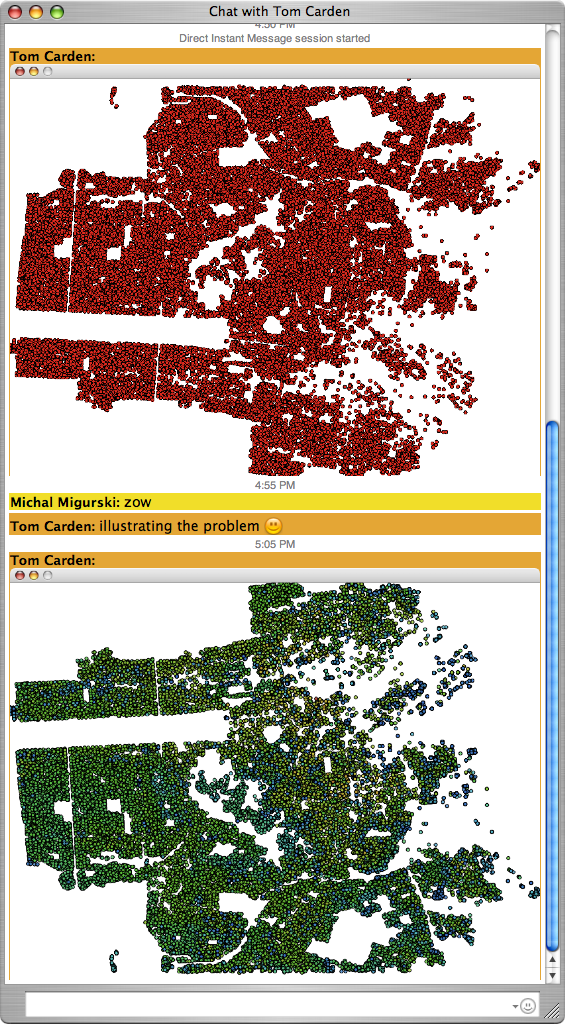
"What's that big blank spot in Cow Hollow?"
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski