tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Feb 15, 2016 6:27am
openaddresses population comparison
Lots going on with OpenAddresses since I last wrote about it in July. The continuous integration service is alive and well, we have downloadable collections of all addresses, the dot map is updating regularly, and the full collection has ticked over 220 million records.
Last year, Tom Lee (of Sunlight Foundation and Mapbox) made an offhand estimate of two people per address which has had me thinking about completeness and coverage estimation. At that number, we’re at approximately 3% of global addresses. Fortunately, there are a few gridded population datasets with worldwide coverage that make it possible to estimate coverage more precisely:
- NASA Earthdata Gridded Population of the World (GPW) offers a 30” raster product.
- Global Rural-Urban Mapping Project (GRUMP) offers additional processing over GWP.
- Yale Geographically Based Economic Data (G-Econ) offers a 1° gridded spreadsheet data product, broken down by country.
G-Econ is the smallest data set, and as a simple spreadsheet it’s the easiest to get started with. It has estimates through 2005 which is close enough for an experiment, and a number of interesting data columns beyond simple population counts about economic output, soil type, availability of water, and climate.
Using G-Econ, it’s possible to generate address/person comparisons for places where OpenAddresses has data, such as Europe:
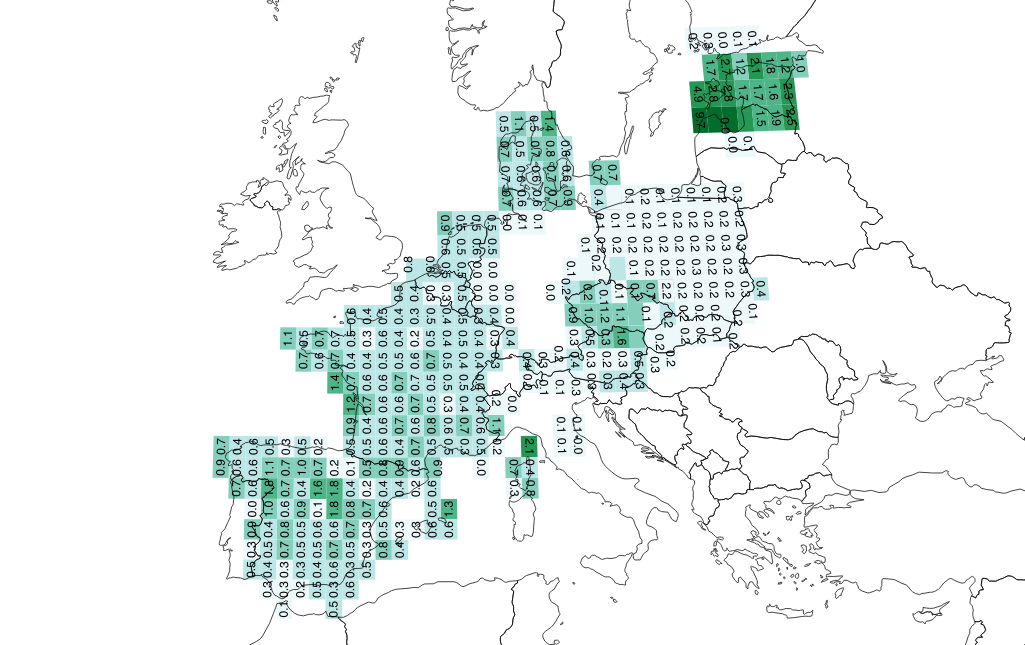
From this image, it looks like Tom’s estimate of 0.5 addresses per person holds for much of France, Spain, and Denmark, but not at all for Poland where it’s lower at 0.2 (five people per address). The values for Estonia are strange, with almost two addresses per person in certain grid squares.
In the Western U.S., we can see the effect of overcounting Montana addresses via overlapping statewide and county sources:
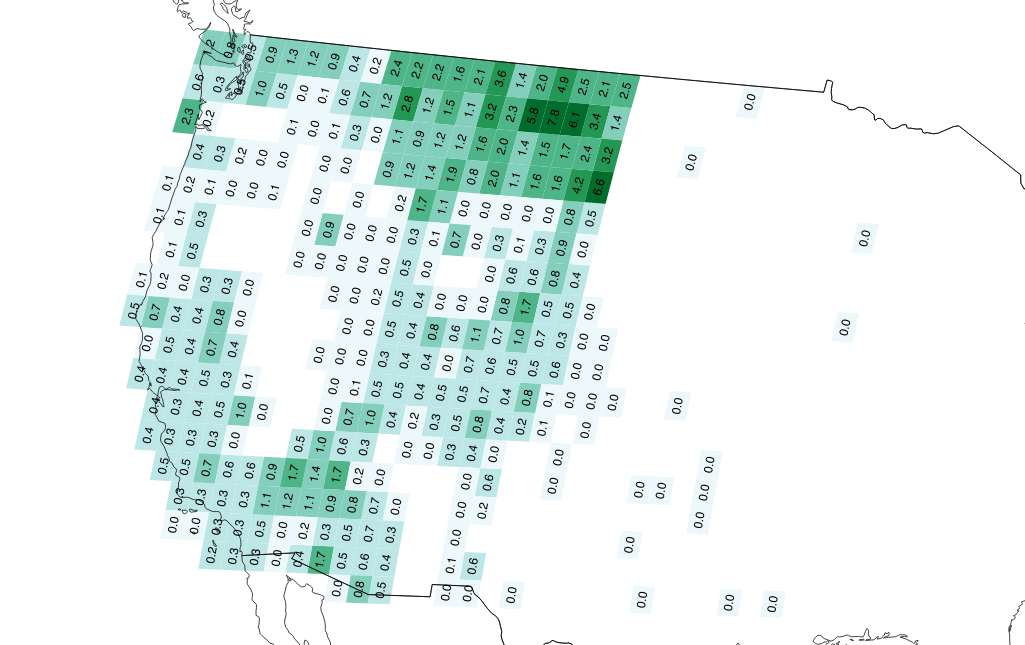
I’m just getting started on this analysis, and hope to create fresh data on a regular basis as we generate scheduled downloads of OA data. I’d like to understand more about the relationships between population density and address availability, and potentially switch to the more complex and current GPWv4 dataset if this is interesting.
For now, check out these two things:
Feb 1, 2016 4:59am
blog all oft-played tracks VII
This music:
- made its way to iTunes in 2015,
- and got listened to a lot.
I’ve made these for 2014, 2013, 2012, 2011, 2010, and 2009. Also: everything as an .m3u playlist.
1. Grimes: Flesh without Blood

2. Trust: Shoom

3. Klatsch!: God Save The Queer
4. Zed’s Dead: Lost You

5. The Communards: Disenchanted

6. Delia Gonzalez & Gavin Russom: Relevee (Carl Craig Remix)
7. The Smiths: Rubber Ring

8. Hot Chip: Need You Now

9. The All Seeing I: 1st Man In Space

10. Missy Elliott: WTF (Where They From) ft. Pharrell Williams
%20ft.%20Pharrell%20Williams.jpg)
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski