tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Feb 15, 2016 6:27am
openaddresses population comparison
Lots going on with OpenAddresses since I last wrote about it in July. The continuous integration service is alive and well, we have downloadable collections of all addresses, the dot map is updating regularly, and the full collection has ticked over 220 million records.
Last year, Tom Lee (of Sunlight Foundation and Mapbox) made an offhand estimate of two people per address which has had me thinking about completeness and coverage estimation. At that number, we’re at approximately 3% of global addresses. Fortunately, there are a few gridded population datasets with worldwide coverage that make it possible to estimate coverage more precisely:
- NASA Earthdata Gridded Population of the World (GPW) offers a 30” raster product.
- Global Rural-Urban Mapping Project (GRUMP) offers additional processing over GWP.
- Yale Geographically Based Economic Data (G-Econ) offers a 1° gridded spreadsheet data product, broken down by country.
G-Econ is the smallest data set, and as a simple spreadsheet it’s the easiest to get started with. It has estimates through 2005 which is close enough for an experiment, and a number of interesting data columns beyond simple population counts about economic output, soil type, availability of water, and climate.
Using G-Econ, it’s possible to generate address/person comparisons for places where OpenAddresses has data, such as Europe:
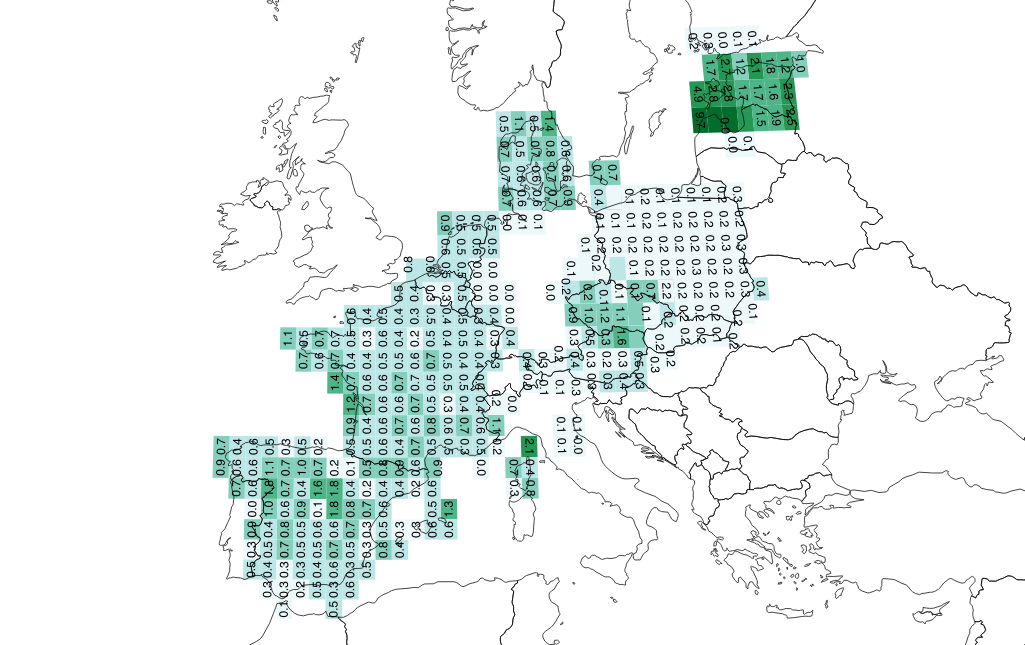
From this image, it looks like Tom’s estimate of 0.5 addresses per person holds for much of France, Spain, and Denmark, but not at all for Poland where it’s lower at 0.2 (five people per address). The values for Estonia are strange, with almost two addresses per person in certain grid squares.
In the Western U.S., we can see the effect of overcounting Montana addresses via overlapping statewide and county sources:
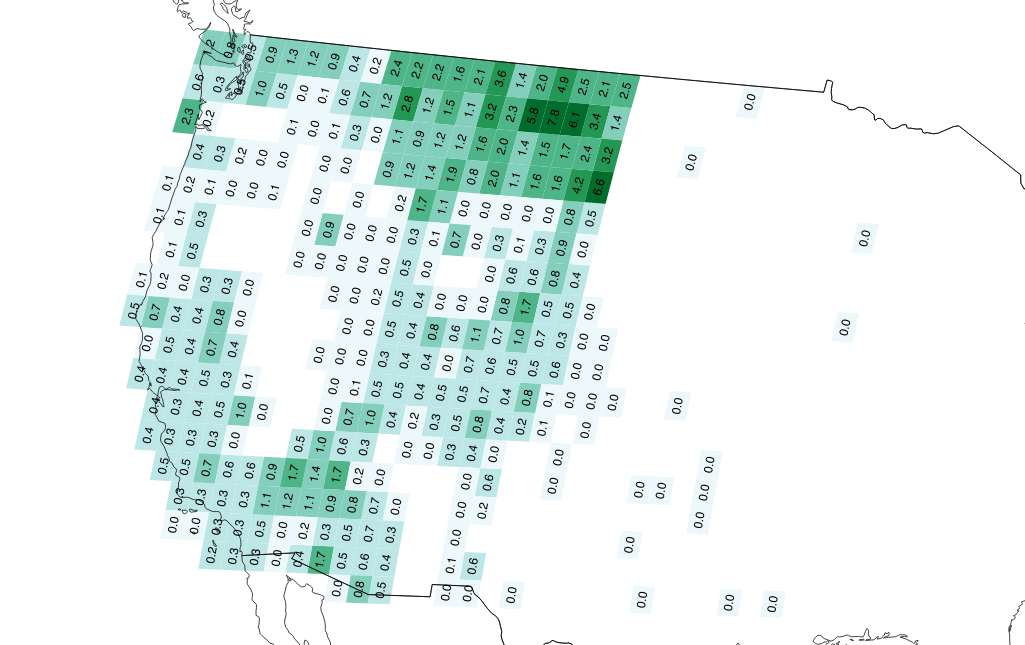
I’m just getting started on this analysis, and hope to create fresh data on a regular basis as we generate scheduled downloads of OA data. I’d like to understand more about the relationships between population density and address availability, and potentially switch to the more complex and current GPWv4 dataset if this is interesting.
For now, check out these two things:
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments (2)
Mike, I've been wanting to do a similar comparison of population density to OSM data, to measure completeness of roads and other feature types. So great to see you're working on this. Was thinking about converting worldpop into vector tiles, and setting up a TileReduce processor for the analysis. That conversion looked heavy so I didn't get far --- maybe we can sync up to think through how to make finer grain population data more accessible
Posted by Mikel on Tuesday, February 16 2016 12:17pm UTC
I'm dismayed to have missed this writeup when you first posted it! I saw the lovely graphs, but not the more detailed notes. First: nice work! This is great. Second, I'll drop the link in here for my source data: https://docs.google.com/spreadsheets/d/1x814db9sFEPRmGW1CvMsyhg12CScib-pJ6K3xTqdydA/edit?usp=sharing That spreadsheet is not at all up to date, but contains the basic reasoning used to get the 0.5 addresses per person figure. There's obviously selection bias here -- I only looked up geographies we had in OA at the time -- but I tried to hit a bunch of different admin levels, looking up population numbers from official sources and/or wikipedia.
Posted by Tom on Sunday, February 28 2016 4:50pm UTC
Sorry, no new comments on old posts.