tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Jul 5, 2015 7:21pm
writing a new continuous integration service for openaddresses
We’ve been working on an update to the technology behind OpenAddresses, and it’s now being used in public.
OpenAddresses is a global repository for open address data. In good open source fashion, OpenAddresses provides a space to collaborate. Today, OpenAddresses is a downloadable archive of address files, it is an API to ingest those address files into your application and, more than anything, it is a place to gather more addresses and create a movement: add your government’s address file and if there isn’t one online yet, petition for it. —Launching OpenAddresses.
Timely feedback is vital to a shared data project like OA, something I learned many years ago when I started contributing to OpenStreetMap. In 2006, tiles rendered many days after edits were made, and the impossibility of seeing the results of your own work gated participation. Today, the infrastructure behind OSM makes it easy to see changes immediately and incorporate them into other projects, feedback vital to keeping editors motivated.
Last year, we automated the OpenAddresses process to cut the update frequency from weeks or months to days. Now, we’d like to cut that frequency from days to hours or minutes.
OpenAddresses is run from Github. If you host a code project there and you’re serious about code quality, it’s likely that you’ve configured Travis or Circle to automatically run your test suite as you work. For external contributors sending pull requests to a project, CI services make it easy to see whether changes will work:
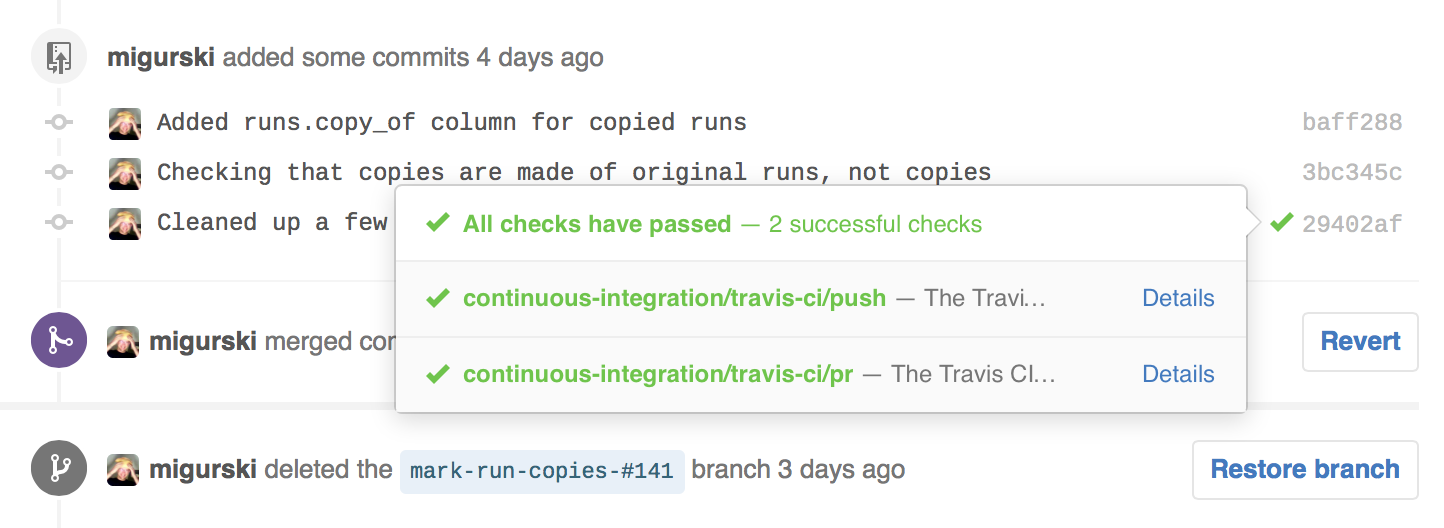
OA has always used Travis CI to verify the syntax correctness of submitted data, and it will tell you that your JSON is valid and that you’re using the right tags. We wanted to be able to see the true results of integrating that data into OA. Ordinarily, Travis itself might be a good tool for this job, but OA sources can take many hours to run, and a single PR might include changes to many sources. So, we needed to roll our own continuous integration service.
What’s New
Creating our own service to run OA source submissions required three parts:
- A web service to listen for events from Github.
- A pool of workers to act on those events.
- Communication back to Github.
The web service is the easiest part, and consists of a simple Flask-based application listening for events from Github. These events can be signed with a secret to ensure that only real requests are acted on. There are dozens of event types to choose from, but we care about just two: push events when data in the OA repository is changed, and pull request events when a contributor suggests new data from outside. Events come in the form of JSON data, and it takes a bit of rooting around in the Github API to determine what actual files were affected. Git’s underlying data model (more, easier) is helpful here, with commits linked to directory trees and trees linked to individual file blobs. Each event from Github is turned into a job of added or changed source data, and each individual source is queued up for work. Nelson chose PQ for the queue implementation since we’re already using Python and PostgreSQL, and it’s been working very well.
The worker pool is tricky. It’s wasteful to keep a lot of workers standing around and waiting, but you still want to act quickly on a new submissions so people don’t get antsy. There are also a lot of interesting things that can go wrong. Amazon’s EC2 service is a big help here, with a few useful features to use. Auto Scaling Groups make it easy to spin up new workers to do big jobs in parallel. We’ve set up a few triggers based on the size of the queue backlog to determine how large a group is needed. When there have been tasks waiting for a worker for longer than a few minutes, the pool grows. When no new tasks have been waiting for a few hours, the pool shrinks. We use Amazon Cloudwatch to continuously communicate the size of the queue. We have struck a balance here, aiming for results within hours or minutes rather than seconds, so we only grow the pool to a half-dozen workers or so.
Finally, Github needs to know about the work being done. As each task is completed, a status of "pending", "success", or "failure" is communicated back to Github where it is shown to a user along with a link to a detailed page. Commercial CI services use the Commit Status API to integrate with Github, and it’s available to anyone. The tricky part here is how to differentiate between failed jobs and ones that simply take a long time. In our case, we have a hard limit of three hours for any job, and judge a job to have failed when it’s been AWOL for more than three hours. Right now, we’re not retrying failed jobs.
Next Steps
There are still bugs and weird behaviors in the CI service, so I’m shaking those out as I watch it in action.
We are continuing to run the batch job process. There’s nothing else that can generate the summary page at data.openaddresses.io for the time being, so the new continuous integration feature is being used solely to inform data contributors within pull requests. I’d like to replace the batch job with a smaller one that schedules missing sources, renders maps, and summarizes output. Then we can kill off the old batch process.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments
Sorry, no new comments on old posts.