tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Nov 29, 2012 7:37am
gamma shapes for obama
Back in April, I bailed to Chicago for a week to volunteer with the Obama campaign tech team. It’s the team you’ve read all about, the one CTO’d by Harper Reed that blew the doors off the Romney campaign, and I was unbelievably lucky to spend one too-short week seven months ago working with the group right in their office.
Interestingly, what I ended up working on was a direct descendant of the precinct geometries that Marc Pfister mentioned in the comments of my old post:
We were manually fixing precinct data. We’d look at address-level registration data and rebuild precincts from blocks. A lot of it could probably have been done with something like Clustr and some autocorrelation. But basically you would look at a bunch of points and pick out the polygons they covered.
Clustr is a tool developed by Schuyler Erle and immortalized by Aaron Cope’s work on Flickr alpha shapes:
For every geotagged photo we store up to six Where On Earth (WOE) IDs. … Over time this got us wondering: If we plotted all the geotagged photos associated with a particular WOE ID, would we have enough data to generate a mostly accurate contour of that place? Not a perfect representation, perhaps, but something more fine-grained than a bounding box. It turns out we can.
Schuyler followed up on the alpha shapes project with beta shapes, a project used at SimpleGeo to correlate OSM-based geometry with point-based data from other sources like Foursquare or Flickr, generating neighborhood boundaries that match streets through a process of simple votes from users of social services. For campaign use, up-to-date boundaries for legislative precincts remains something of a holy grail. We would need an evolution of alpha- and beta-shapes that I’m going to go ahead and call “gamma shapes”.
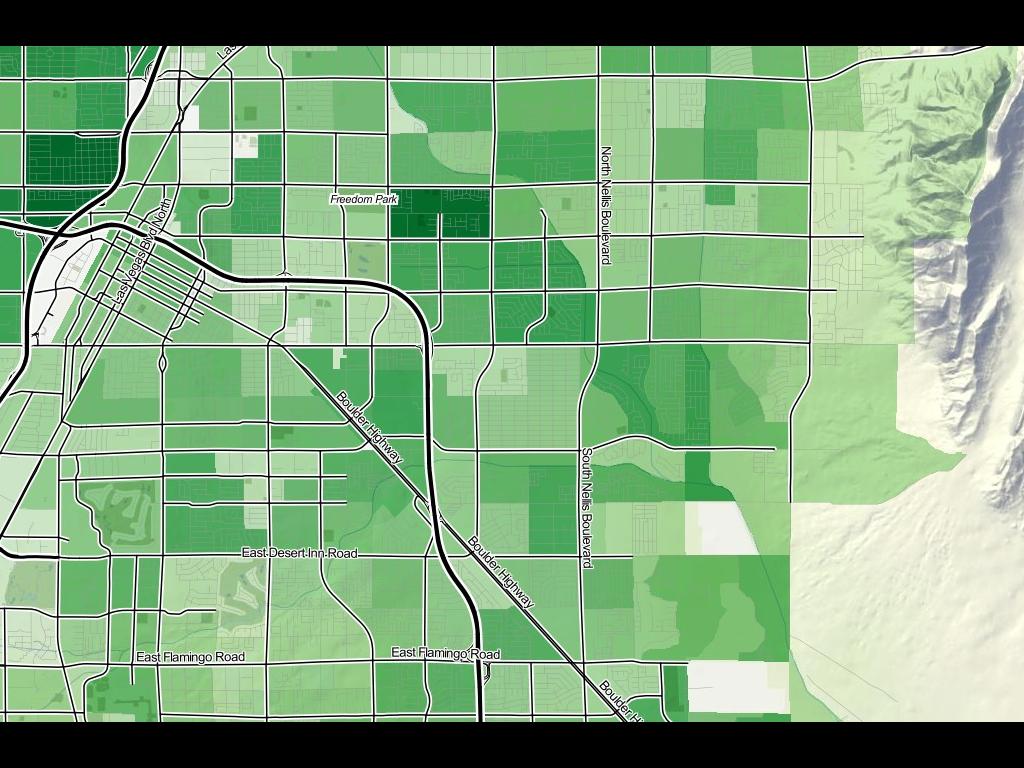
Gamma shapes are defined by information from the Voter Information Project, which provides data from secretaries of state who define voting precincts prior to election day. While data providers like the U.S. Census provide clean shapefiles for nationwide districts, these typically lag the official definitions by many months, and those official definitions are in notable flux in the immediate lead-up to a national election. Everything was changing, and we needed a picture like this to accurately help field offices before November 6:

Unlike Flickr and SimpleGeo’s needs, precinct outlines are unambiguous and non-overlapping. It’s not enough to guess at a smoothed boundary or make a soft judgement call. As Anthea Watson-Strong and Paul Smith showed me, legislative precincts are defined in terms of address lists, and if your block is entirely within precinct A except for one house that’s in B, that’s an anomaly that must be accounted for in the map, such as this district with a weird, non-contiguous island:

The shapes above should look familiar to you if you’ve ever seen the Voronoi diagram, one of this year’s smoking-hot fashion algorithms.
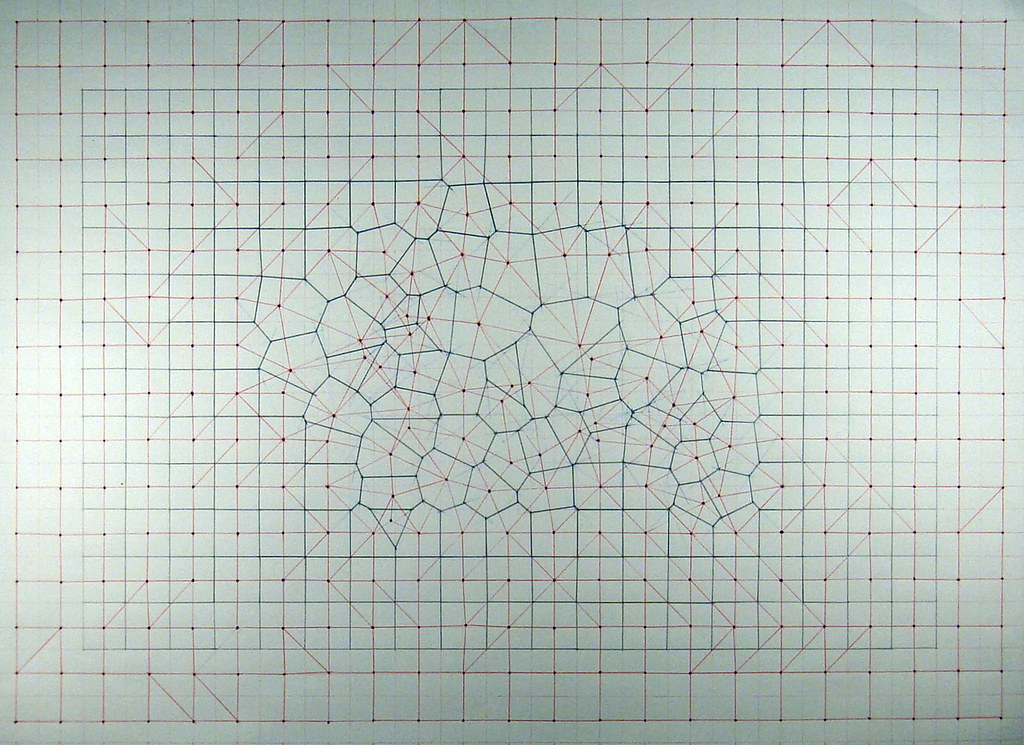
When you remove the clipping boundaries defined by TIGER/Line, you reveal a simple Voronoi tessellation of our original precinct-defining address points, each one with a surrounding cell of influence that shows where that precinct begins and ends. Voronoi allows us to define a continuous space based on distance to known points, and establishes cut lines that we can use to subdivide a TIGER-bounded block into two or more precincts. In most cases it’s not needed, because precinct boundaries are generally good about following obvious lines like roads or rivers. Sometimes, for example in cases of sparse road networks outside towns or demographic weirdness or even gerrymandering, the Voronoi are necessary.
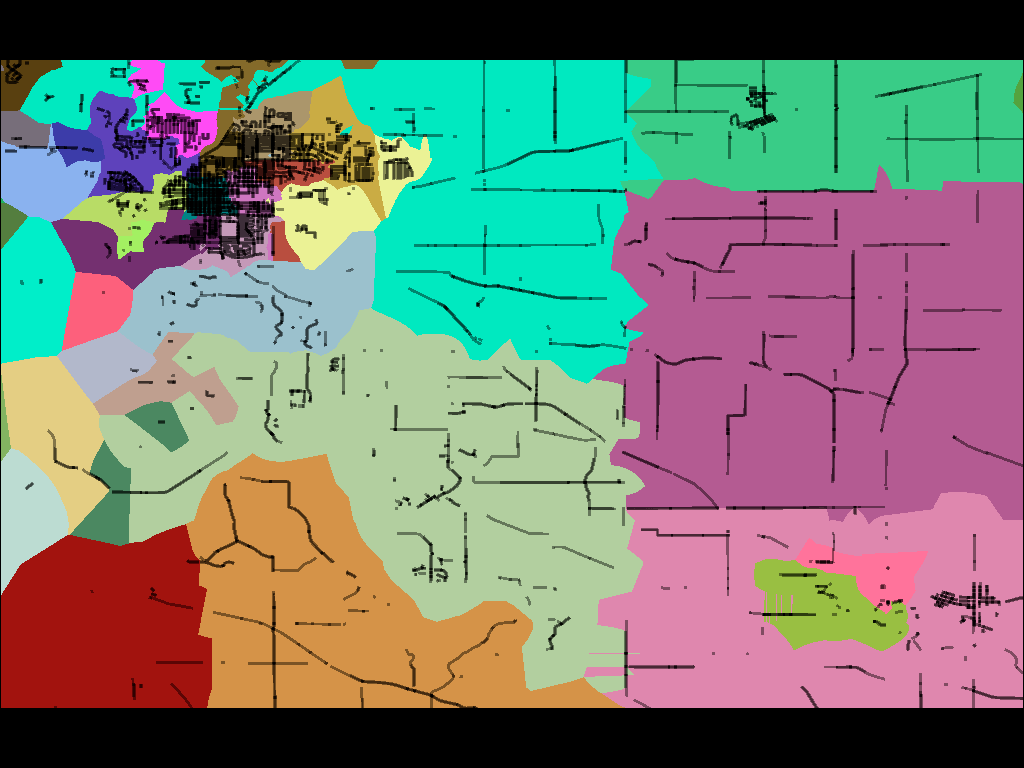
The points in some of the images below are meant to represent individual address points (houses), but for most states precincts are defined in terms of address ranges. For example, the address numbers 100 through 180 on the even side of a street might be one precinct, while numbers 182 though 198 are another. In these case, I’m using TIGER/Line and Postgis 2.0’s new curve offset features to fake a line of houses by simply offsetting the road in either direction and clipping it to a range.

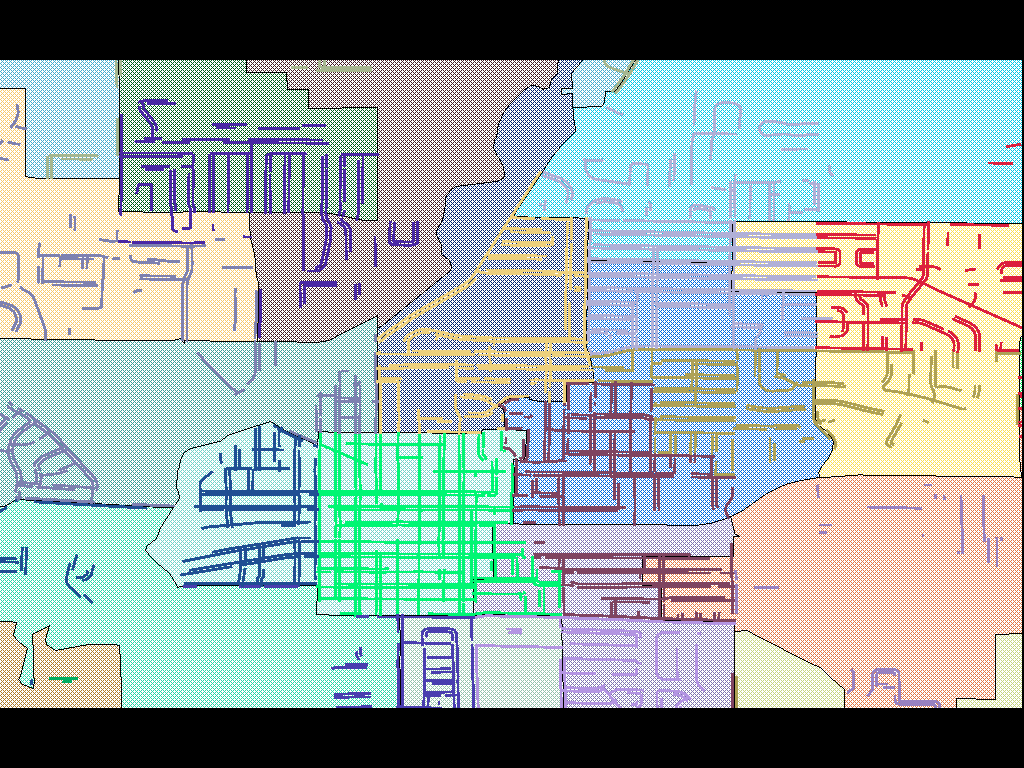
For a large city, such as this image of Milwaukee, there can be hundreds of precincts each just a few blocks in size:
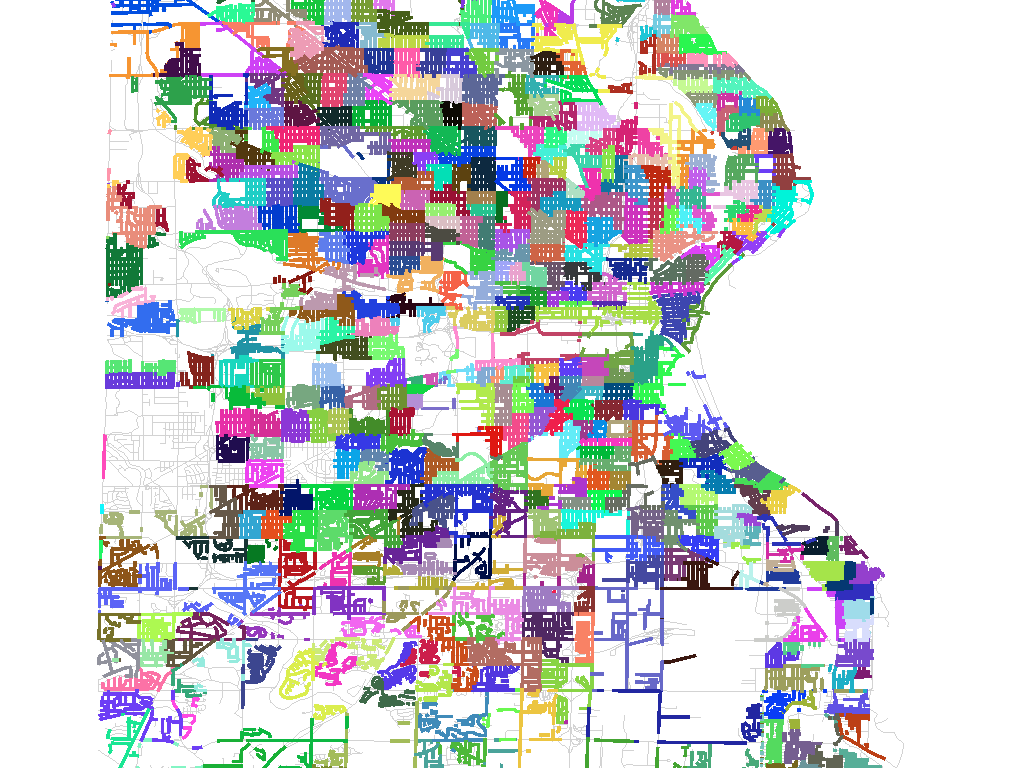
In the end, the Voter Information Project source data ended up being of insufficient quality to support an accurate mapping operation, so this work will need to continue at some future date with new fresh data. Precincts change constantly, so I would expect to revisit this as a process rather than an end-product. Sadly, much of the code behind this project is not mine to share, so I can’t simply open up a repository as I normally would. Next time!

Nov 26, 2012 7:13am
teasing out the data
I spoke in New York two weeks ago, about the shyness of good data and the process of surfacing it to new audiences. I did two talks, one for the Visualized conference and the second for James Bridle’s New Aesthetic class at NYU’s Interactive Telecommunications Program.

In February 2010, The Economist published its special report on “the data deluge,” covering the emergence and handling of big data. At Stamen, we’ve long talked about our work as a response to everything informationalizing, the small interactions of everyday lives turning into gettable, mineable, patternable strands of digital data. At Visualized, at least two speakers described the bigness of data and explicitly referenced the 2010 Economist cover for support. I’ve been trying to get a look at the flip side of this issue, thinking about the use of small data and the task of daylighting tiny streams of previously-culverted information.

Aaron Cope joked about the concept of informationalized-everything as sensors gonna sense, the inevitability of data streams from receivers and robots placed to collect and relay it. I recently spent a week in Portland, where I met up with Charlie Loyd whose data explorations of MODIS satellite imagery arrested my attention a few months ago. Charlie has been treating MODIS’s medium-resolution imagery as a temporal data source, looking in particular at the results of NASA’s daily Arctic mosaic. Each day’s 1km resolution polar projection shows the current state of sea ice and weather in the arctic circle, and Loyd’s yearlong averages of the data show ghostly wisps of advancing and retreating ice floes and macro weather patterns. The combined imagery is pale and paraffin-like, a combination of Matthew Barney and Edward Imhof. I’m drawn to the smooth grayness and through Loyd’s painstaking numeric experimentation with the data I remember the tremendous difficulty of drawing data from a source like MODIS. Nevermind the need to convert the blurry-edged image swaths, collected on a constant basis from 99-minute loops around the earth by MODIS’s Aqua and Terra hardware, the downstream use of the data by researchers at Boston University in 2006 to derive a worldwide landcover dataset is an example of interpretative effort. The judgements of B.U. classifiers are tested by spot checks in the United States, visits to grid squares to determine that there are indeed trees or concrete there. The alternative 2009 GLOBCOVER dataset offers a different interpretation of some of the same areas, influenced by the European location of the GLOBCOVER researchers and the check locations available to them. Two data sets, two sets of researchers, two interpretations governed by available facts, two sets of caveats to keep in mind when using the data.
Civic-scale data offers some of the same opportunities for interpretive difficulty. For years I’ve been interested in the movements of private Silicon Valley corporate shuttles, and thanks to the San Jose Zero1 Biennial we’ve been able to support that fascination with actual data.

At Visualized, I explored the idea of good data as “shy data,” looking at the work we did in 2006/2007 on Crimespotting and our more-recent work on private buses. The city of San Francisco had already studied the role of shuttle services in San Francisco, yet the report was not sparking the kind of dialogue these new systems need. Oakland was already publishing crime data, but it wasn’t seeing the kinds of day-to-day use and attention that it needed.

Exposing data that’s shy or hidden is often just introducing it to a new audience, whether that’s The New York Times looking at Netflix queues or economists getting down in the gutters and physically measuring cigarette butt lengths to measure levels of poverty and deprivation.
The Economist-style “data deluge” metaphor is legitimate, but seems somehow less cuspy than completely new kinds of data just peeking out for the first time. The deluge is about operationalized, industrialized streams. What are the right approaches for teasing something out that’s not been seen before, or not turned into a shareable form?
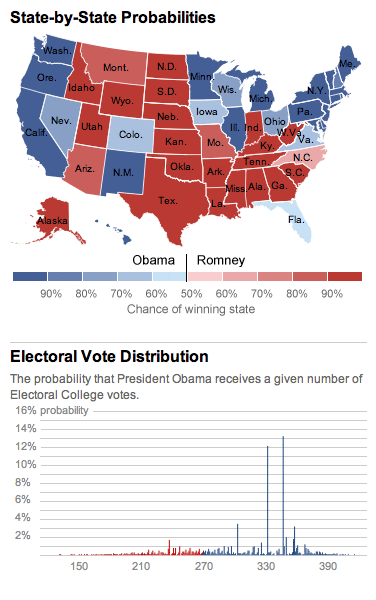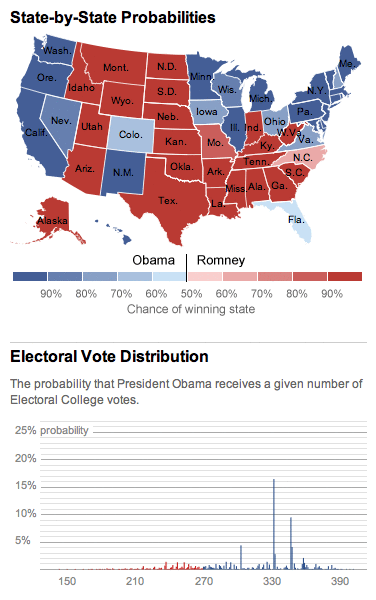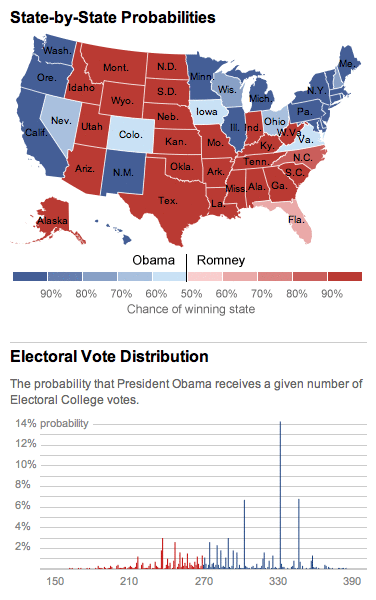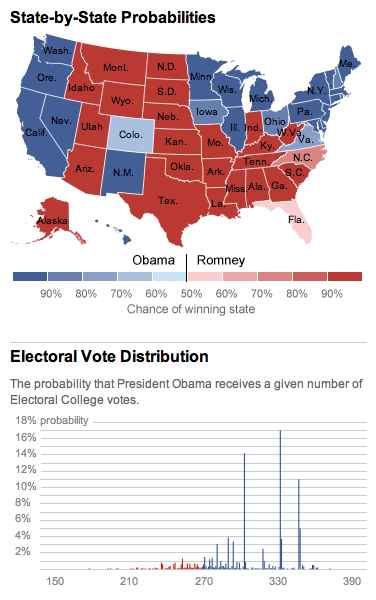
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski