tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Feb 9, 2008 8:40pm
thinking about spreadsheets while washing the dishes
I've had reasons to think about spreadsheets in the context of a number of clients recently. They're becoming something like a lingua franca for delivery of sample data. In some ways, this is frustrating: files are inevitably in Excel format, sizes are limited, delivery is clunky, etc. In other ways, it marks a sort of graduation into "real business" land for us, where we have to buy copies of MS Office and use them more than once or twice each month. That or just hit xlrd.
I'm inevitably reminded of Ian C. Rogers' post on music, Convenience Wins, Hubris Loses. There, he introduces the genius metaphorical arithmetic iTunes is a spreadsheet that plays music. For Rogers, this is a critique: It's context-free. You just paid $10 for that album - who plays drums? I dunno, WHY DON'T YOU GO TO THE WEB TO FIND OUT, BECAUSE THAT'S WHERE THE CONTEXT IS. Ian, as a Yahoo! Music guy, makes the point that background context for music is the domain of the web, and the missing piece to iTunes. For me, the analogy is a reminder of what makes iTunes so great: my listening habits have become much more spreadsheet-like lately: my two most-used smart playlists are "Been A While" (all tracks where last played is not in the last 3 months) and "Top Songs" (all tracks where rating is greater than two and time is less than 15:00). The first one feeds the second one as I listen to music and get around to rating it. The first one also helps guarantee a continuous degree of novelty.
The spreadsheet has an older, wiser cousin, and it is called database.
My first exposure to a database in the now-familiar application context was during an early contracting gig for which I learned ColdFusion and modified some sort of forms-based site. Everything made sense for the most part, except that there was this monster lurking under the covers and I could ask it to SELECT and UPDATE things, but only Tim in the room next door knew how to modify tables or make new instances. I had no mental model for what it was doing. The thing that makes a relational database more interesting to me than a spreadsheet is that it is meant to store a bag of facts rather than a particular representation of them. Excel's rows have a given order, and that's meaningful. I continue to be confused when I open the program, select a row header, and no automated sorting happens. I bump up against a particular idea of permanence that makes order matter for a spreadsheet and not matter for a database, and I've been conditioned to expect the latter by eight years of working on the web with a succession of open source SQL engines.
A blog post by Theresa Neil that I encountered early last week, Seek Or Show, pokes at this distinction from the interface point of view. She talks about two paradigms: the Seek (Search) paradigm is typically used in web sites, and the Show (View Based Lists) paradigm exists mainly in desktop applications. The distinction comes from differing economies of scale on the web vs. the desktop: the seek/search paradigm works when storage is cheap but transmission expensive, as in the context of a large database published over the web. The show/lists paradigm works when transmission is cheap, as on a desktop computer.
Theresa describes ways in which the show/lists pattern might move onto the web. I'm interested in the ways in which traditionally show-based applications might switch paradigms entirely. Local storage is becoming cheap, and technologies like Spotlight, CoreData, and SQLite are making it easier for all kinds of developers to think like a database admin (not to mention the way that Apple and Mozilla have their sites on actual application development with WebKit and XULRunner). Above all, the volumes of information typically associated with a show/lists UI are growing past the point of reason.
If iTunes is a spreadsheet that plays music, what would a database that plays music look like? There are a few hints out there at what this would be. The most obvious is Last.fm, the UK music site that observes your listening habits through an iTunes plug-in and publishes them on the web. My primary use of Last.fm is a the presence of a frequently-updated script that displays Shawn's recently-played music on my desktop. Up until a few months ago, this would migrate into search terms on OiNK (now it goes nowhere). Friends Ryan and Gabe eschew iTunes altogether and play their music from a custom-built web application that streams everything in via Flash in the browser. Here's a screenshot:
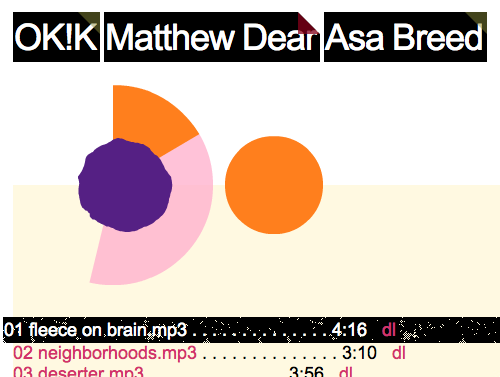
The blue dot at left is an animated radial EQ, the gray arc around it is the MP3 loading progress, and the orange arc is the track time progression. The orange dot at right is a growing/shrinking volume control.
The interesting thing about this case is that the site has rudimentary social features that mimic a few of Last.fm's, but you can actually listen to the music on it. It's storage as well as index. The thing it does not do is present a view of its music too far outside the traditional album-artist-track hierarchy.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments (3)
That's the thing... a spreadsheet is, at best, an INNER JOIN of a relational db.
Posted by joe on Monday, February 11 2008 4:16am UTC
this is a really interesting post. the past couple websites i've worked on have been Flash/XML driven, and to ease the clients into managing their own website i hooked everything up to an Excel spreadsheet saved out as a [messy] XML file. even though it's really ugly, as long as the flash deals with the office xml, the clients get to manage their website from a familiar excel sheet. how itunes stores its xml is more like a dictionary than Excel's spreadsheet format. this is something i did with my itunes data: http://www.diametunim.com/muse/spiral.php?user=sha last.fm does let you play music off of it, but it's still a little clunky. it'd be interesting to see how we move beyond spreadsheets as interfaces..
Posted by sha on Tuesday, February 12 2008 6:14pm UTC
Sha, the use of XML from otherwise "non kosher" apps is really interesting. I've been experimenting with geometry editing using Adobe Illustrator and SVG in a similar way, and there are definitely pitfalls. Maybe this is a way forward: the spreadsheet concept is obviously useful, but it could become a UI appendage that fronts a networked database. It seems like Google Docs is making some moves in this direction.
Posted by Michal Migurski on Tuesday, February 12 2008 7:40pm UTC
Sorry, no new comments on old posts.