tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Dec 14, 2012 6:58am
three ways fastly is awesome
We released the Google #freeandopen project earlier this month.
In a few days the International Telecommunication Union, a UN body made up of governments around the world, will be meeting in Qatar to re-negotiate International Telecommunications Regulations. These meetings will be held in private and behind closed doors, which many feel runs counter to the open nature of the internet. In response to this, Google is asking people to add their voice in favor of a free and open internet. Those voices are being displayed, in as close to real time as we can manage, on an interactive map of the world, designed and built by Enso, Blue State Digital, and us!
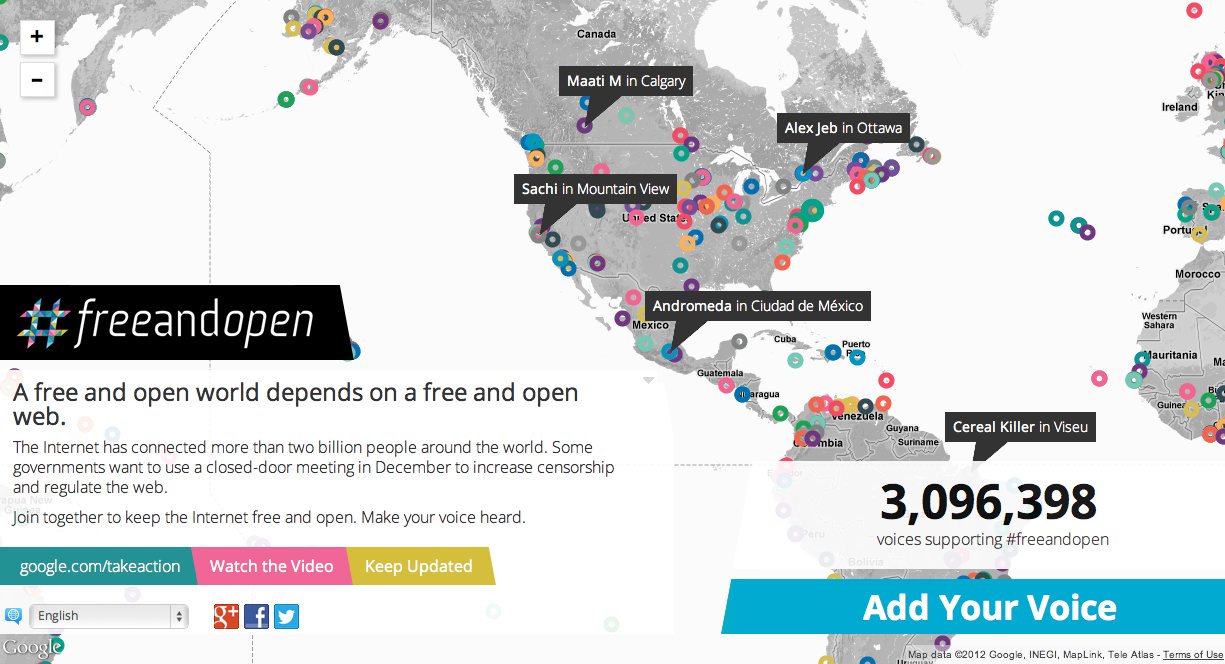
It was a highly-visible and well-trafficked project, linked directly from Google’s homepage for a few days, and we ultimately got over three million direct engagements in and amongst terabytes of hits and visits. We built it with a few interesting constraints: no AWS, rigorous Google security reviews, and no domain name until very late in the process. We would typically use Amazon’s services for this kind of thing, so it was a fun experiment to determine the mix of technology providers we should use to meet the need. Artur Bergman and Simon Wistow’s edge cache service Fastly stood out in particular and will probably be a replacement for Amazon Cloudfront for me in the future.
Fastly kicked ass for us in three ways:
First and easiest, it’s a drop-in replacement for Cloudfront with a comparable billing model. For some of our media clients, we use existing corporate Akamai accounts to divert load from origin servers. Akamai is fantastic, but their bread and butter looks to be enterprise-style customers. It often takes several attempts to communicate clearly that we want a “dumb” caching layer, respecting origin server HTTP Expires and Cache-Control headers. Fastly uses a request-based billing model, like Amazon, so you pay for the bandwidth and requests that you actually use. Bills go up, bills go down. The test account I set up back when I was first testing Fastly worked perfectly, and kept up with demand and more than a few quick configuration chanages.
Second, Fastly lets you modify with response headers. It’s taken Amazon S3 three years to release CORS support, something that Mike Bostock and I were asking them about back when we were looking for a sane way to host Polymaps example data several years ago (we ended up using AppEngine, and now the example data is 410 Gone). Fastly has a reasonably-simple UI for editing configurations, and it’s possible to add new headers to responses under “Content,” like this:
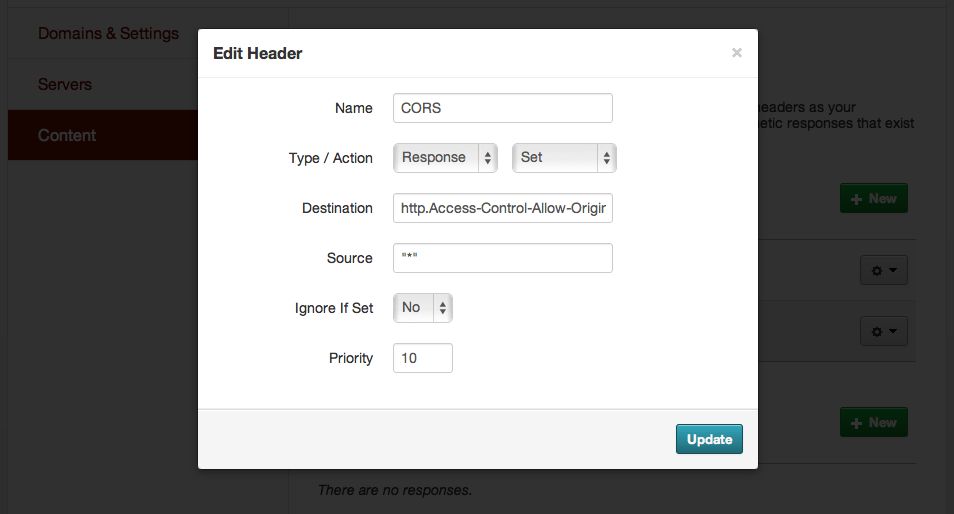
Now we could skip the JSONP dance and use Ajax like JJG intended, even though the source data was hosted on Google Cloud Storage where I couldn’t be bothered to figure out how to configure CORS support.
Finally, you can perform some of these same HTTP army knife magic on the request headers to the origin server. I’m particularly happy with this trick. Both Google Cloud Storage and Amazon S3 allow you to name buckets after domains and then serve from them directly with a small amount of DNS magic, but neither appears to allow you to rename a bucket or easily move objects between buckets, so you would need to know your domain name ahead of time. In the case of GCS, there’s an additional constraint that requires you to prove ownership of a domain name before the service will even let you name a bucket with a matching name. We had to make our DNS changes in exactly one move at a point in the project where a few details remained unclear, so instead of relying on DNS CNAME/bucket-name support we pointed the entire subdomain to Fastly and then did our configuration there. We were able to keep our original bucket name by rewriting the HTTP Host header on each request, in effect lying to the storage service about the requests it was seeing so we could defer our domain changes until later:
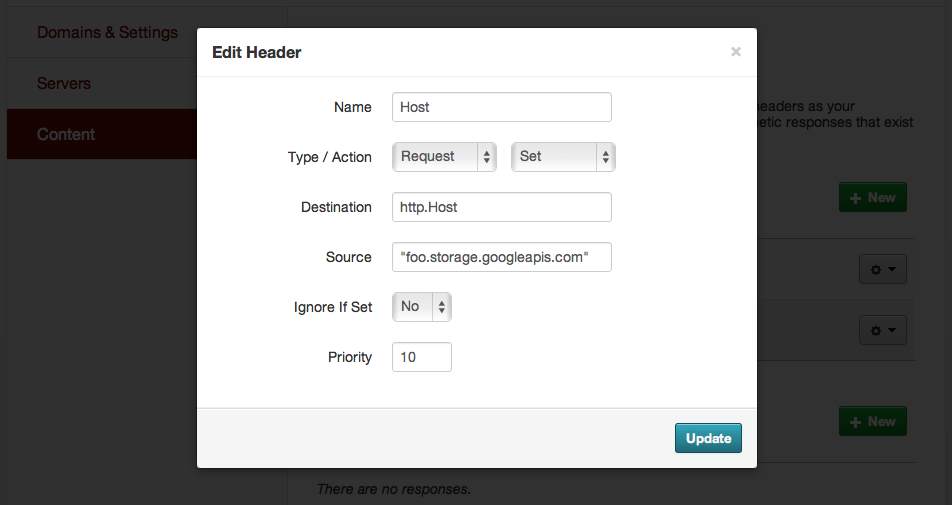
It sounds small, but on a very fast-moving project with a lot of moving pieces and a big client to keep happy, I was grateful for every additional bit of flexibility I could find. HTTP offers so many possibilities like this, and I love finding ways to take advantage of the distributed nature of the protocol in support of projects for clients much, much larger than we are.

subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments (2)
Very interesting, thanks. Are you allowed to reveal what backend technology you used, if any?
Posted by Stephan Tual on Friday, December 21 2012 11:27am UTC
Hi Stephen, the backend technology is painfully boring: a mix of PHP, MySQL, Python and Redis.
Posted by Michal Migurski on Saturday, December 22 2012 1:13am UTC
Sorry, no new comments on old posts.