tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Nov 20, 2014 6:07am
open address machine
The OpenAddresses project is super-interesting right now:
OpenAddresses is a global repository for open address data. In good open source fashion, OpenAddresses provides a space to collaborate. Today, OpenAddresses is a downloadable archive of address files, it is an API to ingest those address files into your application and, more than anything, it is a place to gather more addresses and create a movement: add your government’s address file and if there isn’t one online yet, petition for it. —Launching OpenAddresses.
OA is the free and open global address collection, but it’s just getting off the ground. Ian Dees of longtime OpenStreetMap involvement kicked off the project early this year when OSM balked at bulk address imports. It’s more sensible as a separate project anyway.
I’ve been working on data.openaddresses.io to make the project more legible and responsive.
I’m about six months late to the party, but there’s a ton to do right now. Thinking back on my own involvement in OSM, I remembered that around 2006 the street map tiles were being updated infrequently, and my own willingness to add data was gated by the turnaround time of seeing my input on the real, live map. I’d add some stuff, then twiddle my thumbs for days (or weeks) while the render refreshed. My satisfaction from adding data improved with every advance in OSM’s rendering stack re-render time. Seeing your effect on the data set is an important motivational factor.
OA has a similar issue for me. It’s implemented as a giant bag of JSON files stored in Github, so it’s not immediately obvious where the data lives, how up-to-date it is, or (if you’re submitting new files) whether a data source even works. The processing code works, but it’s not immediately obvious how to make all the pieces fit together.
I have been working on machine, a harness for running the whole process on a more regular cycle. There’s a bunch of interesting moving pieces.
I’ve taken Andy Allan’s chef advice to heart and created a chef recipe collection for preparing OA to run on a bare Ubuntu 14.04 machine. Chef is a no-brainer for me now, and I use it for everything that stands any chance of being important. Andy says:
Configuration management really kicks in to its own when you have dozens of servers, but how few are too few to be worth the hassle? It’s a tough one. Nowadays I’d say if you have only one server it’s still worth it – just – since one server really means three, right? The one you’re running, the VM on your laptop that you’re messing around with for the next big software upgrade, and the next one you haven’t installed yet.
If you want to add a skeletal chef script to any existing repository, start here:
git pull https://github.com/migurski/chefbase.git master
The whole OA codebase is now possible to run on a scratch machine, which means that once each week I can start an EC2-XXXL server and have it set up with complete OA code in minutes. It takes a few hours to run everything. We can keep data.openaddresses.io up-to-date with the status of the data, including a fresh map of data from US states and counties (even though OA is international), a complete listing of cached and processed status for all data, and small data samples to provide hints for correctly mapping (“conforming”) source data to OA’s needs.
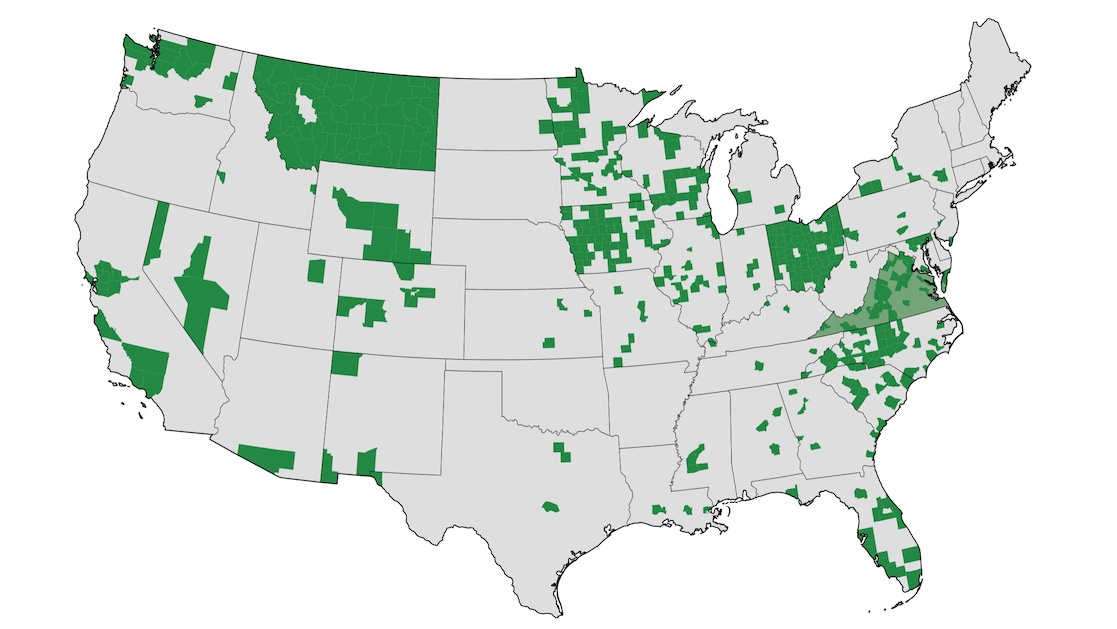
There remains a lengthy ticket backlog, but I am hoping that OA provides a way to better expose and unify the world’s municipal government spatial data. Today, addresses. Tomorrow, parcels.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski
Comments
Sorry, no new comments on old posts.