tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Jun 2, 2017 5:39am
the levity of serverlessness
As tech marketing jargon goes, “serverless” is a terrible word. There’s always a server and the cloud is just other people’s computers, it’s only a question of who runs it. I like Kate Pearce’s take:
The next time you try and use the word “serverless” just remember it’s like calling takeout “kitchenless”.
Still, Amazon’s supposedly-serverless Lambda offering has some attractive qualities so I’ve used it on a selection of projects during the past few months. I’ve learned a bit about making Lambda work in a Python development flow. Having already put my head through this wall, maybe this post will help you find it easier?
The key differences between running code on Lambda instead of a server you manage emerge in costs, downtime, heavy usage, and development constraints. You pay for the resources you consume measured in milliseconds. With a virtual server, you pay for uptime measured in hours. Lambda is free when it’s not in active use, unlike a virtual server that costs money when sitting idle waiting for requests. Lambda can accept large concurrent request volumes. Virtual servers may instead need to be spun up over a period of minutes to deal with increased demand. In some ways it’s closer to Google’s old App Engine service than Amazon’s EC2, similar to Heroku’s platform service, and definitely closer to my own assumptions about EC2 at the time it first launched a decade ago (I didn’t realize EC2 was regular Linux boxes in the sky). The heavy cost for these scaling properties comes in several constraints: a Lambda function can only run for a few minutes and consume a small amount of memory, and must be written in one of a limited number of languages.
I’ve used it in three projects of increasing complexity: a script for reposting images from my Tumblr account to my Mastodon account, a simple form-based data collector, and a new service for scoring legislative district plans (more on that in a future post).
Some things worked as-advertised.
Stuff That Just Worked
- Python 3.6
- Execution limits
- Different invocation types
- Integrations with other AWS services
- AWS CLI, the command line client
For a while, only Python 2.7 was supported by AWS Lambda. This made it kind of a toy — anything serious I do in Python now, I do in version 3 to get the advantage of good unicode support. Sometime last month, Python 3.6 support was added to Lambda making it immediately compatible with my own development preferences. The Python 3.6 support is real, and comes with the full standard library you’d expect anywhere else. It’s possible to write serious code and deploy it now.
The documented limits seem to work as promised: functions can reliably run for up to five minutes, and the provided Context object will tell you how much time you have remaining in milliseconds. When you go over time (or over memory, though I have not experienced this) the function is halted without notice. Execution logs go to Cloudwatch, where the amount of billed time is recorded.
There are two invocation types, “Event” and “RequestResponse”. The first is used in situations where you want to trigger a function and you don’t care about its return value, such as scheduled tasks. The second is used when you need the response immediately, and is especially useful together with API Gateway for writing functions that can be called by users via an HTTP request. Event invocation is pretty useful: you can’t run a Lambda function directly from a queue, but you can invoke the function as an Event and let it run for an indeterminate period of time while responding immediately to a user request. It’s a useful way to get queue-like behaviors cheaply.
Generally, interactions with other AWS services work well. I’m new to Cloudwatch Logs, but it’s the only output mechanism available for debugging a Lambda function running on the platform. When a function is retried and fails twice, a warning message can be sent via SNS or pushed to a queue. Lambda functions are not ordinarily accessible from the public web, but the API Gateway service makes it possible to map a URL to a function so it can be used on a website. All basic stuff, but it works together effectively. I’ve found it useful to keep numerous browser tabs open with the AWS Console because it can be confusing to track each of these services.
Finally, the AWS CLI is a great command-line client for all AWS services. Terminology between the developer console, the CLI, and the underlying Boto SDK is consistent, and actions available in a browser are equally available via the CLI client. This makes it possible to script certain deployment tasks as part of an automated process, and experiment with AWS actions before writing code.
Some other things about Lambda remain a pain.
Stuff That Sucks
- Editing code
- Configuring API Gateway
- Development environments
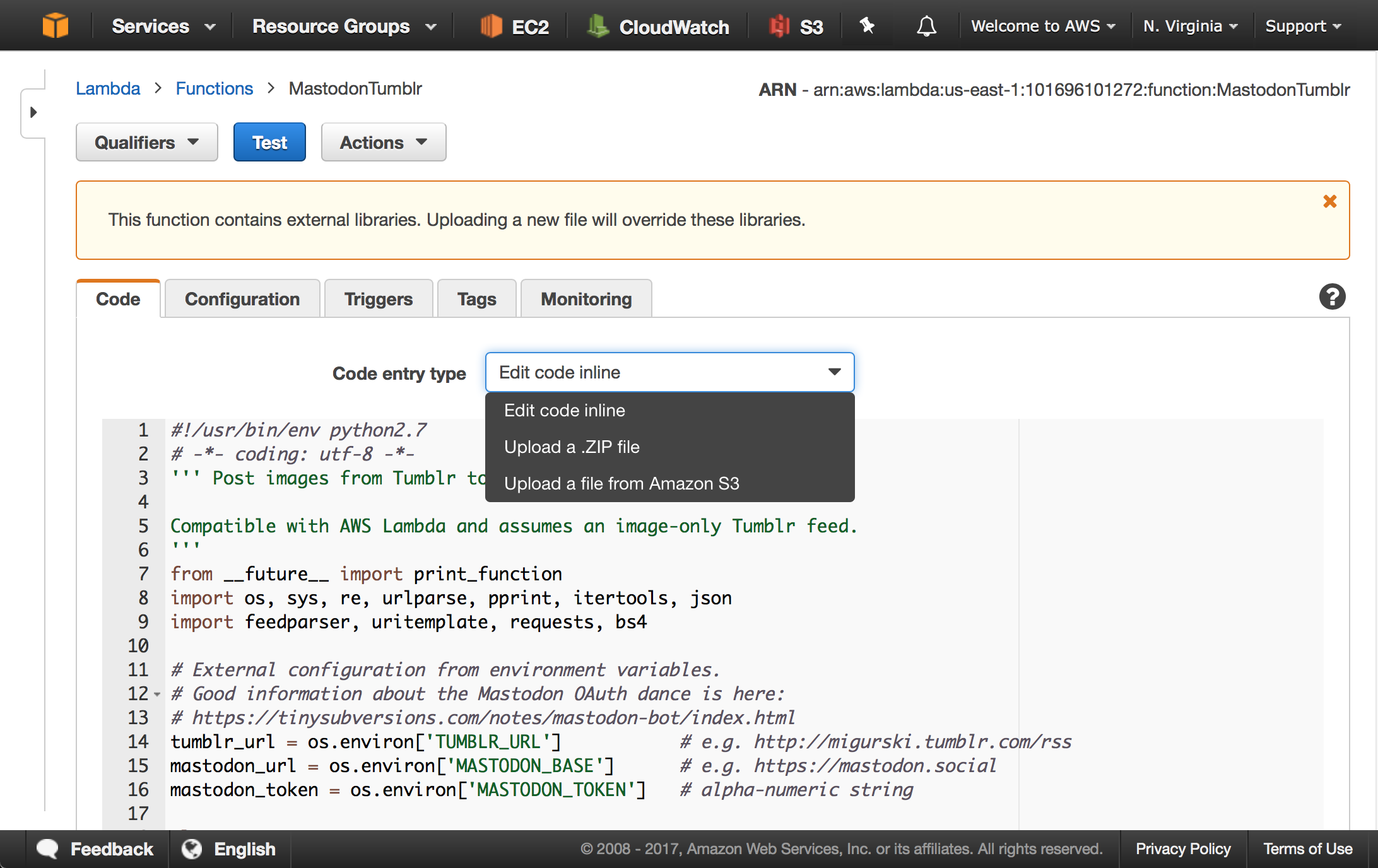
Editing non-trivial code is a bummer. The basic interface to Lambda is an editable text box where you can type (or paste) code directly. In my browser, Safari on OS X, certain operations like copy/paste frequently fail in the text box. A Zip archive upload is provided as an alternative, and the AWS CLI can let you do this programmatically. On slow internet this introduces a prohibitive time delay uploading large function packages. Heroku’s Git model and integration with service like Github feels much more mature and conducive to a smooth development and deployment flow.
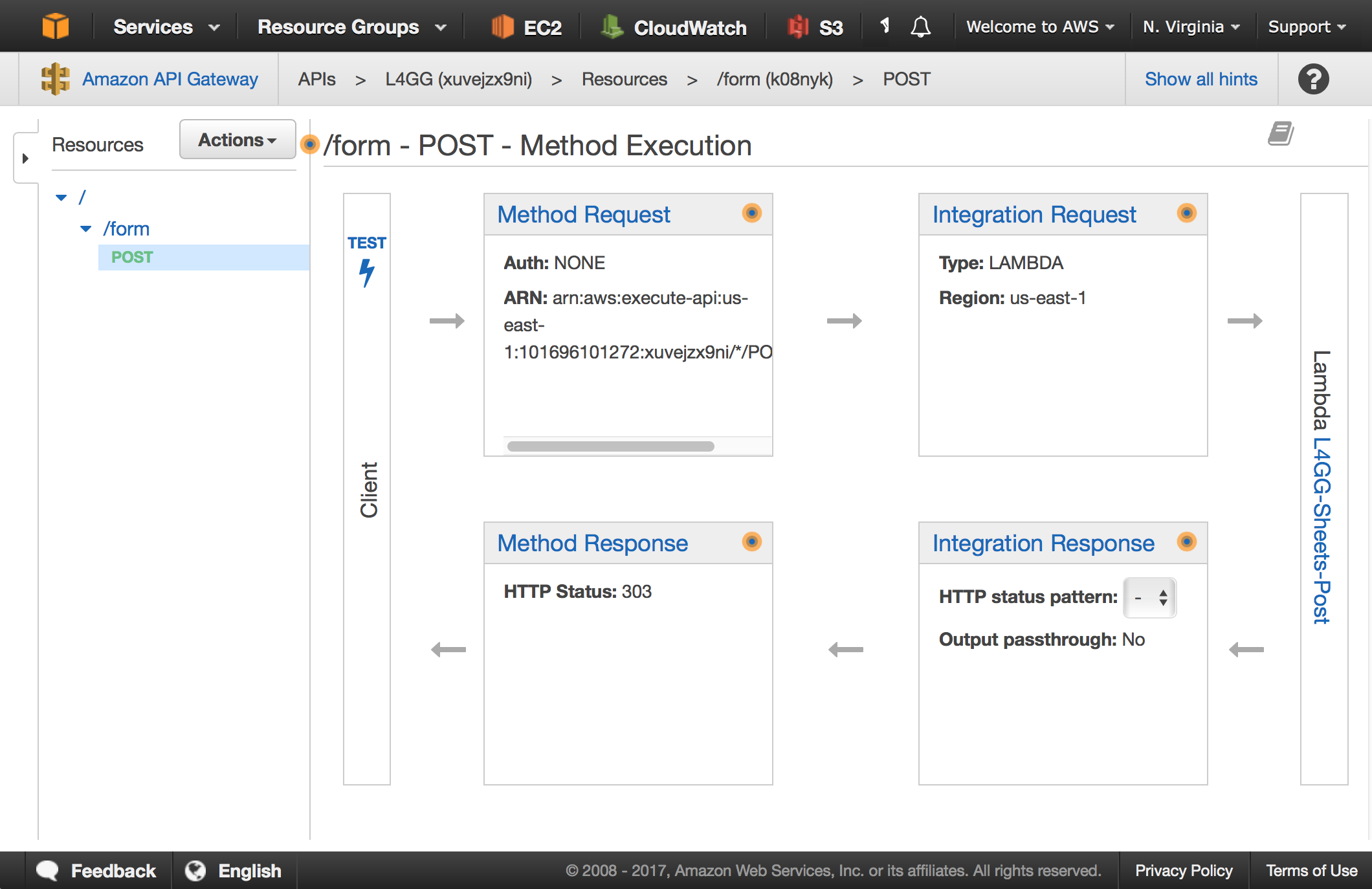
Working with the API Gateway service is unfortunate, with four interlocking pieces of configuration: Method Request, Integration Request, Integration Response, and Method Response. Configured settings in each are interdependent, such as the status code and header behaviors in the two response configurations. Getting “normal” HTTP things like form submissions to work involves some pretty weird Stack Overflow driven development, and generally feels hacky. I have mostly found configuring API Gateway to be a trial-and-error process. I’ve heard that Swagger helps with this in some way, but it also appears to overengineer a lot of unrelated things so I’ve ignored it.
Finally, it’s difficult to spin up a quick dev environment with all these services. I’ve ended up continuously deploying to production as I work, not dissimilar from old-style FTP-based development. Heroku has always done this very well with entire stacks magicked out of Github pull requests, and the recently-departed Skyliner.io platform did a great job with AWS configurations specifically. AWS API Gateway does have the concept of deployment stages, but it’s only one piece of the overall picture. AWS Cloudformation is supposed to help with this, but it’s big and impenetrable and I haven’t yet invested the time to understand if it’s an answer or more questions.
Fortunately, a bunch of other things I thought would be difficult turned out to work really well in Lambda after a bit of effort to learn more about the model.
Stuff I Learned
- Packaging for deployment
- Deploying from a CI service
- Including compiled binaries
- Uploading one well-tested package for multiple functions
- Using Proxy Integration to make requests sane
As soon as I wanted to use Amazon’s Python SDK Boto to talk to other Amazon services from Lambda, I realized I was going to need to build a package larger than a single file. Lambda’s deployment advice shows how to use Pip to build a zip archive for upload to Amazon, so I’ve been adding that to project build scripts. Pip’s target directory option creates the right structure for Lambda’s use, which means that my usual requirements declarations now just work with Lambda.
Once Boto was added to the package, the size immediately ballooned to several megabytes. Boto is pretty big, and doesn’t include an option for building a minimal version. So, I was creating code builds much too large to effectively upload from my home DSL or my mobile tether. I wanted to be able to deploy via incremental Git pushes as Heroku allows, and fortunately Circle CI’s deployment feature made this possible. After adding master branch deployment to my testing configurations, I no longer needed to wait for lengthy network transfers on my local connection.
The next addition that ballooned my package sizes was GDAL, a compiled binary library for working with geographic data. Fortunately, Seth Fitzsimmons and Matthew Perry have each worked on this before and provided details on making GDAL work with Lambda. Seth in particular has become something of an expert in getting hard-to-compile binary software like GDAL and Mapnik working on platforms like Lambda and Heroku. I’m enormously lucky to be able to benefit from his work. I used Seth’s Docker-based build hints to include GDAL in the Lambda packages. With GDAL’s addition and a few other dependencies, the overall package size had increased to 25MB so I was grateful for Circle CI’s role in the process.
The actual differences between different function packages were quite miniscule by this point, so I’ve been uploading a single package to Lambda for multiple functions and using a minimal entry point script to provide handler functions. This organization has helped in a few ways. When Lambda invokes a handler from within a module, it doesn’t allow for relative imports that are useful for building a real package. I looked for ways around this and found a 2007 note from Guido van Rossum arguing that “running scripts that happen to be living inside a module’s directory” is “an antipattern”. Moving those scripts out to a short file outside the module is closer to the spirit of Guido’s intended usage. Also, it makes comprehensive testing of a module easier to complete.
After messing around with API Gateway’s various input and output options, I’ve concluded that Lambda Proxy Integration is the only way to go. Lambda handlers will never see CGI-style HTTP input as Heroku applications do, but API Gateway sends the next best thing with a dictionary of HTTP input details. These are under-documented so it’s taken some trial-and-error to get input working. I’ve considered writing a small Lambda/Flask bridge using these objects in order to write an application that can be fully run locally, and hopefully the example provided in Amazon’s docs is sufficiently comprehensive.
Conclusion
Working with Lambda still feels fairly uphill, and I’m hoping to improve on some of the challenges above. As I’ve been writing an application with no users, it’s been easy to update live Lambda functions. A next step would be to configure a second development environment with all the necessary interconnecting parts. I’m pretty pleased with the tradeoffs, assuming that Lambda’s scaling advantages work as-promised.

subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski