tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Sep 26, 2011 12:06am
piecemeal geodata
Two weeks ago, I attended the 5th annual OpenStreetMap conference in Denver, State of the Map. My second talk was called Piecemeal Geodata, and I hoped to communicate some of the pain (and opportunity) in dealing with OpenStreetMap data as a consumer of the information, downstream from the mappers but hoping to make maps or work with the dataset. Harry Wood took notes that suggested I didn’t entirely miss the mark, but after I was done Tom MacWright congratulated me on my “excellent stealth rage talk”. It wasn’t really supposed to be ragey as such, so here are some of my slides and notes along with some followup to the problems I talked about.
tl;dr version: OSM Cartography really should be a lot easier. Part of what makes it hard is understanding where useful, small parts of the data come from. I made new metro-area extracts for world cities, and I’ve got a proposed change to the Planet page that’s easier for new data consumers to understand.

First, the pain.
To make your own useful map of OpenStreetMap, you need OSM data and a derived coastline. To turn that data and coastline into something good, you need to understand how to use a whole belt of tools: getting data from Planet or one of the extracts, importing into a rendering database with osm2pgsql, pulling out relevant data with Osmosis, getting a separate coastline data set, and getting that into a rendering database with shp2pgsql. Once you get your head around it, it’s not so bad, but recently I’ve had the privilege of seeing all this through a beginner’s eyes thanks to two Stamen clients, and I think there’s a lot that can be improved here.

Frederik Ramm’s 2010 talk, Optimising the Mapnik Rendering Toolchain, put it better than I can right on the first slide: “Things you could have found out yourself if only it didn’t take so damn long to try them!” This is the story of OSM in a nutshell, though I should point out there’s nothing actually wrong with this state of affairs. A conversation with Matt Amos after I spoke showed how sensitive to the risk of attractive nuisances the OSM community can be—“if we do this thing, then people will use our half-assed solution instead of doing it right for themselves”. OpenStreetMap should provide a bulletproof full-planet wholesale service intended for use by serious developers, in preference to retail services like the extracts.

The opportunity here is that the data is actually incredibly valuable all on its own, without the bogeyman of commercial data licenses or crown copyright. Tom Churchill argued in his Saturday talk that OSM data was better for his law enforcement clients than commercial data, even though price for his is not a factor. For Churchill’s ARS product, the presence of details like leisure=playground or building names on college campuses is a critical element of situational awareness missing from navigation-focused commercial data sets.

It’s possible to shrink this problem by providing a wider variety of OSM extracts, and improving the usability of the Planet page.
One way to provide better planet extracts is to make them geographic and tiled. I’ve had some similar experiences with raster elevation data from the USGS, and it took a lot of digging to find that NED 10-meter data is actually findable in simple .zip files, instead of the confusing collection of slippy-view-and-download tools (“The National Map Legacy Viewer”, “The National Map Seamless Server”, “New National Map Viewer”, “National Map Viewer Beta”, “Seamless Data Warehouse”, “Earth Explorer”, etc.).



(Watch a video of the Dutch brick-laying machine)

Anyway, the value of tile-based downloads is something I covered in my NoGIS talk a few months ago, and I’m seeing some movement on this idea on the list through tools like OSM Split and Merge Tool.

Perhaps more interesting is the possibility of per-city extracts that cross national and administrative boundaries. This is one place where I’ve been experimenting with Osmosis to release metro.teczno.com, a collection of extracts for worldwide cities. I think there’s a real opportunity here, with so many emerging cartography tools like mbtiles that assume limited-coverage tile collections, often at the scale of a single country or metro area. Extractotron, the code behind these extracts, is additionally an experiment with how to best use cloud-computing resources to support distributed data. Amazon has offered to host full-planet datasets in the past but these efforts have often floundered due to the fast-moving nature of OSM data. With a bit of experimentation I’ve determined that it takes about a half-day to run a full 18GB planet file on a few dozen metro areas, or about $2.00 in EC2 costs. Combined with the ability of an EC2 instance to terminate itself, it’s possible for me to maintain worldwide metropolitan extracts on a regular basis for less than the cost of sponsoring a child.


The final opportunity I discussed was the sad state of the Planet index, a webserver-default file listing with almost no introduction or considerations for novice users:
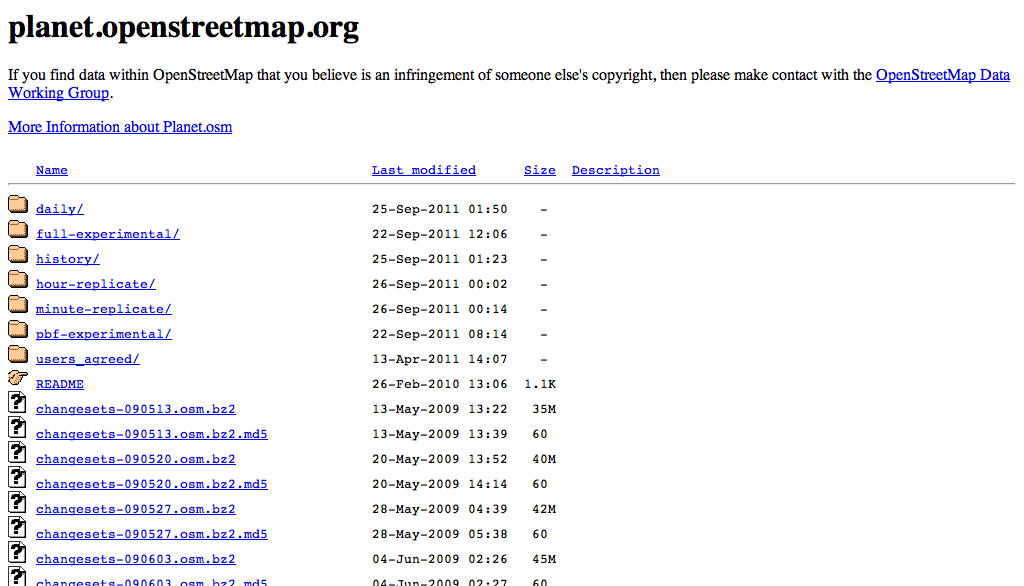
There’s a link to the wiki, but in my mind “link to the wiki” is collaborative project code-speak for “teach the controversy”*. My recommendation for fixing the index page is on Github, and boils down to just a few things:
- Say what’s on the page, ideally multiple times.
- Link to the latest data near the top.
- Say how big and old the data is.
- No surprises: it should still be an autoindex page.
- Say what’s on the page again.
- Help people understand how they might use data.
- Help people not have to use the whole thing at once.
- Sort the list by recency instead of alphabetically.
It looks like this:
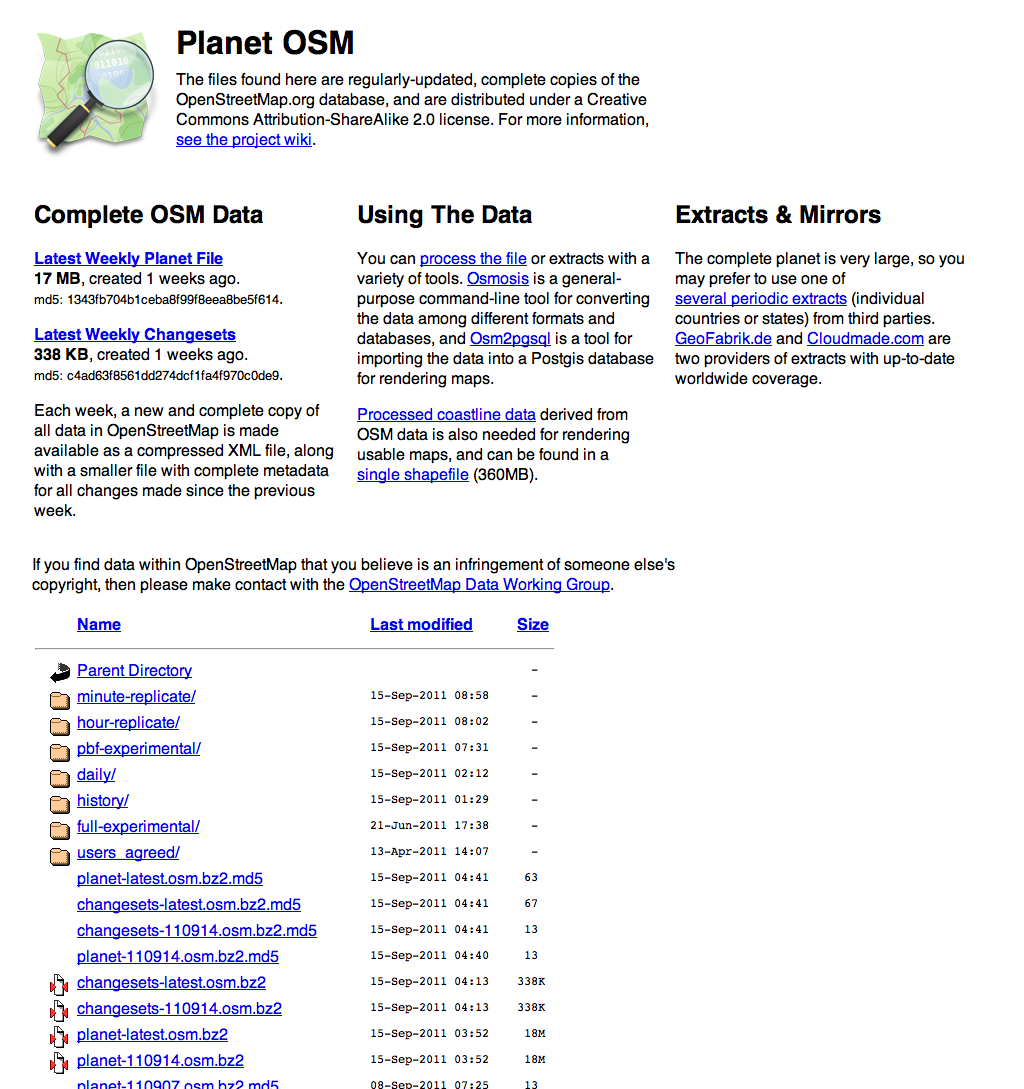
I was asked at the talk whether a better Planet index was not also a job for a motivated outsider, and I think this is one situation where OSM.org itself needs to step up and take visible ownership of the situation. Regular data publishing is no longer an experimental sideshow to the OSM project, it’s right on the main stage. It reminds me of Twitter’s streaming “firehose” API history. We were one of the first groups to consume the live stream when Twitter had under 100K active users in 2007 and a persistent TCP stream was a fairly weird idea Blaine Cook and Kellan Elliott-McCrea were experimenting with under the name “social software for robots”. Today, the Streaming API is a major part of Twitter’s business and powers 100% of our work with MTV, NBC, and other live Twitter event visualization projects. It has levels of service and real documentation, and generally points toward the future of what OSM’s planet files and minutely-diffs can be to data consumers. With a small amount of effort, those planet files can be mode more usable for non-technical users, which means more happy, enthusiastic and creative users of OSM data overall.
subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski