tecznotes
Michal Migurski's notebook, listening post, and soapbox. Subscribe to ![]() this blog.
Check out the rest of my site as well.
this blog.
Check out the rest of my site as well.
Jun 26, 2011 2:42am
seeing like a state, lying with pictures
![]()
Eyeo Festival is this week in Minneapolis, and I’m gathering notes for my panel with Mark Hansen, Laura Kurgan, and Lisa Strausfeld. I’m thrilled that Mark extended an invitation, especially since our conversation will be about data visualization and social justice:
This panel will look into the relationship between data (collection | sharing | analysis | visualization) and social justice. What can we reveal about the state of things by creating new views of the data? Can making the data more meaningful actually effect change in society?
We’re up on Wednesday afternoon just before the closing wrap-up, and as I consider some initial answers to the questions above I keeping coming back to Seeing Like A State, James C. Scott’s book-length argument on visibility and power, recommended to me a few years ago by Adam Greenfield. I’m finding myself expanding the premise of the panel somewhat: do we reveal new things about society by viewing data, or do we bend society into new forms by choosing data that can be viewed?

Scott talks about the state and his examples are mostly large-scale agricultural programs and high-modernist city planning, but I’m seeing echoes of his argument in current excitement about infographics and visualization as a medium, well-documented in blogs like Fast Co Design, Infosthetics, and artfully lampooned by Phil Gyford last year. The core piece of terminology in Seeing Like A State is “legibility”, and as a powerful institution demands more its methods shift from descriptive to prescriptive, from more-effectively seeing reality to modifying reality to make it more easily seeable.
Page 38 defines the problem, from the point of view of the state:
Rural living in seventeenth- and early eighteenth-century Denmark, for example, was organized by ejerlav, whose members had certain rights for using local arable, waste, and forest land. It would have been impossible in such a community to associate a household or individual with a particular holding on a cadastral map. The Norwegian large farm (gard) posed similar problems. Each household held rights to a given proportion of the value (skyld) of the farm, not to the plot land; none of the joint owners could call a specific part of the farm his own. Although it was possible to estimate the arable land of each community and, making some assumptions about crop yields and subsistence needs, arrive a plausible tax burden, these villagers derived a substantial part of their livelihood from the commons by fishing, forestry, collecting resin, hunting, and making charcoal. Monitoring this kind of income was impossible.
My co-panelist Laura Kurgan is maybe best-known for her astonishing Million Dollar Blocks project, a data investigation into New York prison spending dating back to 2004. Million Dollar Blocks has always been a favorite of mine, for a few reasons: our instinctual response at Stamen to this type of data is to put a slider on it, but Laura Kurgan and Eric Cadora went with the much more expressive, emotional $1,000,000 cutoff to make a point. If you’re not from Brooklyn it’s not even all that important which blocks make the cut. A slider is a slider and a million bucks is a million bucks, but only one of them fits into a short headline to make the point truly armor-piercing. The name of the project gathers up a jumble of data and history and offers it up in a legible form that snaps into instant relief the wisdom of spending seven figures on incarceration.
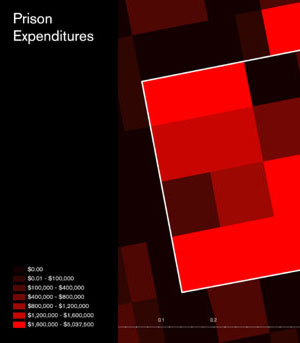
If you can’t see the value, you can’t judge its relative worth.
Back to Scott, Page 39:
As long as the common property was abundant and had essentially no fiscal value, the illegibility of its tenure was no problem. But the moment it became scarce (when “nature” became “natural resources”), it became the subject of property rights in law, whether of the state of the citizens. The history of property in this sense has meant the inexorable incorporation of what were once thought of as free gifts of nature: forests, game, wasteland, prairie, subsurface minerals, water and watercourses, air rights (rights to the air above buildings or surface area), breathable air, even genetic sequences, into a property regime. In the case common-property farmland, the imposition of freehold property was clarifying not so much for the local inhabitants—the customary structure of rights had always been clear enough to them—as it was for the tax official and the land speculator.
The imperative of legibility is a result of scarcity, and the audience for it may not necessarily be its subjects. “The order in question is most evident, not at street level, but rather from above and from outside” (page 57).

Moving on to visualization of data for non-state entities or corporations, many of them have the same state-scale needs and means at their disposal. The blanket term for this is business intelligence (or “insight” if you prefer the advertisements in airport terminals), and we’re seeing the popularization of infographics derived from this genre change focus from inward-facing charts (such as Stephen Few’s work on bullet graphs) to “snackable social objects” as Brad and Jesse from JESS3 call them. I won’t say too much about that except to point out one terrible, terrible bit of nonsense by David McCandless to illustrate what happens when large, interested entities decide to push the idea of visualization as a way to package and communicate facts.

David made it for General Electric, which says this about its efforts in visualization:
At GE, we believe data visualization is a powerful way to simplify complexity. We are committed to creating visualizations that advance the conversation about issues that shape our lives, and so we encourage visitors to download, post and share these visualizations.
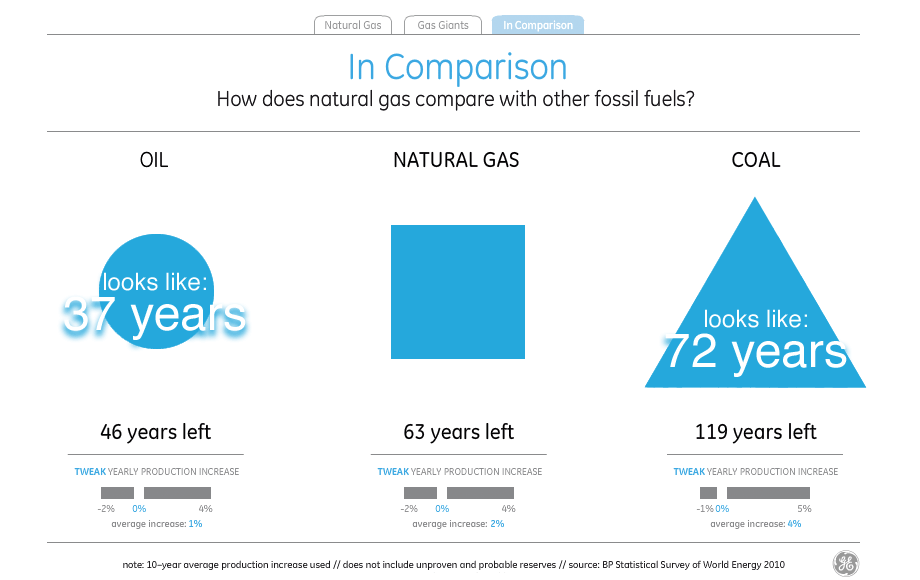
It’s just one number, but you can roll over each one of the little squares to see a country’s reserves (as measured by BP in 2010), which sort of makes you think of a heatmap until you start to wonder about the grout in between all the bricks that adds up to almost a full fifth of the total visual area.

Switching to the “comparison” tab is where this choice of visual style comes home to roost, and it becomes obvious that McCandless’s decorative decisions clash with GE’s stated goal of advancing the conversation.
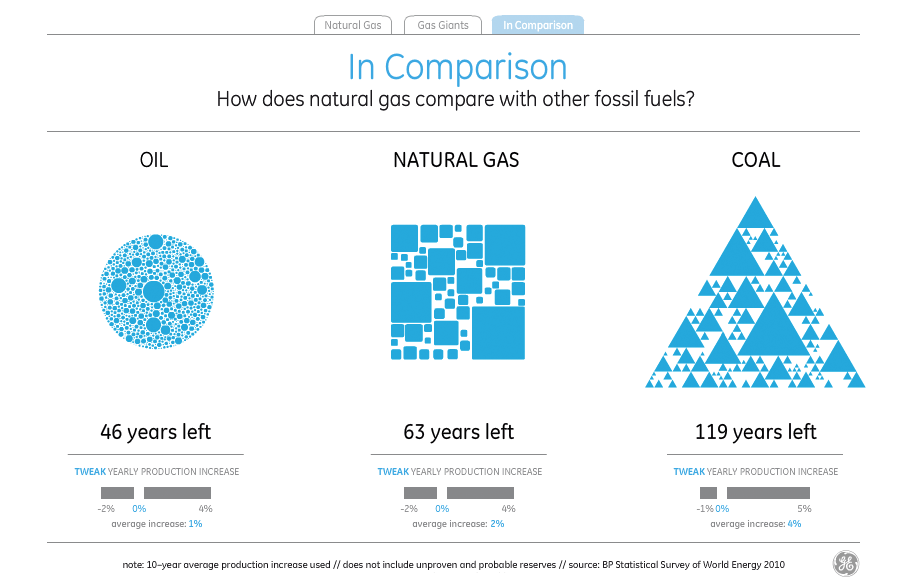
I’ve not found a way to make those numbers and shapes match up. Doing the same trick as above with visual density, it looks as though the amount of visual error in the white parts between the shapes reaches as high as 50%.
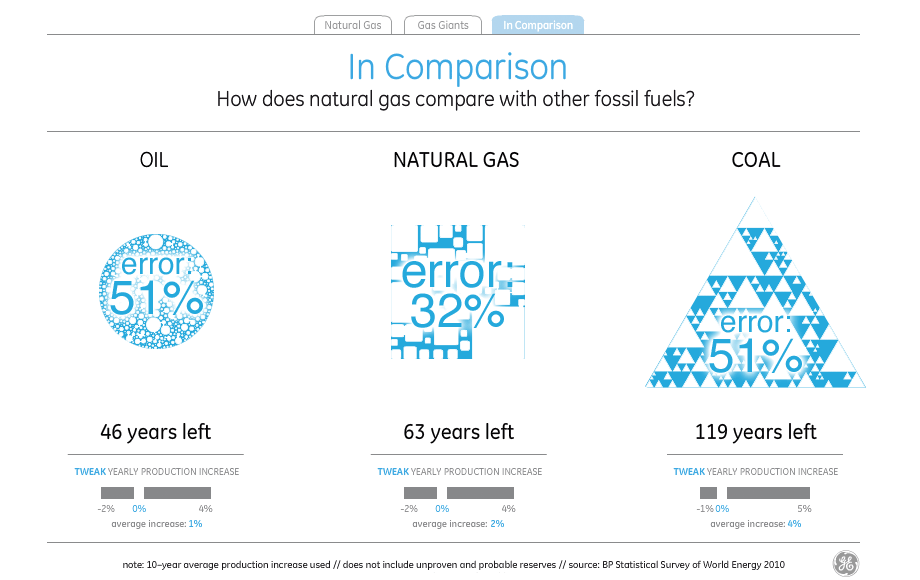
If you treat the natural gas supply of 63 years as a standard and try to read the visual density of the shapes to represent oil and coal to the left and right, you end up with visual variables very different from what the numbers say. The amount and density of blue circles understates the amount of oil by 17 years, while the amount and density of blue triangles understates the amount of coal by a shocking 62 years, making it look like there’s less coal than natural gas.
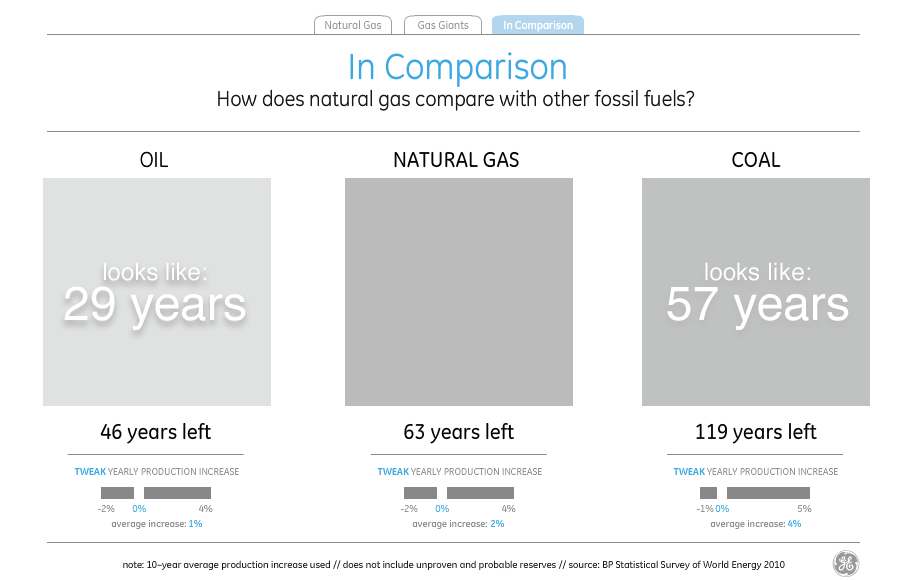
Just in case David really meant the shapes to be interpreted as filled-in and all those little bits are just him wanking around in Flash, I checked and found that the shapes still consistently understate everything except natural gas by as much as 40%. Since the title of the visualization is “the world has huge natural gas reserves”, I guess one way to make the point is to lie about the oil and coal reserves.
It’s obvious that even if McCandless’s snow job on the part of General Electric managed to show accurate numbers, it would still illustrate many of the characteristics of abstract legibility from Seeing Like A State. From page 80,
State simplifications have at least five characteristics that deserve emphasis. Most obviously, state simplifications are observations of only those aspects of social life that are of official interest. They are interested, utilitarian facts. Second, they are also nearly always written (verbal or numerical) documentary facts. Third, they are typically static facts. Fourth, most stylized state are also aggregate facts. Aggregate facts may be impersonal (the density of transportation networks) or simply a collection of facts about individuals (employment rates, literacy rates, residence patterns). Finally, for most purposes, state officials need to group citizens in ways that permit them to make a collective assessment. Facts that can be aggregated and presented as averages or distributions must therefore be standardized facts.
It’s worth noting that James C. Scott isn’t blindly criticizing statistical simplifications: “They are anything but simple-minded, and they are often wielded with great sophistication by officials. … the grouping of synoptic facts necessarily entails collapsing or ignoring distinctions that might otherwise be relevant.” (page 81). What he does criticize is the misinterpretation or outright modification of objective reality to fit that synoptic view, and this is where the argument becomes relevant to the panel again.
My response to all this is something to the effect that people should help other people to see and represent their world usefully and accurately. While it’s so often true that the power of synoptic viewing is available only to those members of society perched near the top, I can think of a number of cases where that same power is distributed democratically. The U.S. Census and U.S.G.S. both come to mind as organizations whose data product is made relentlessly public as a matter of normal operation, giving ordinary citizens the means to see their world as the state chooses to see it. The same state apparatus that puts people in prisons helps create the conditions under which Laura Kurgan can research the financial impact of those prisons.
Public data projects like Wikipedia or OpenStreetMap similarly provide for the creation of high-quality, shared data sets that cannot be taken away once released, thanks to the parallel efforts of legal experts like Creative Commons, the Free Software Foundation, and others.
The data issue I hope we manage to touch on in the panel might be better phrased as how to use new views of data to activate the creation and maintenance of reliable social data.
![]()
Jun 16, 2011 6:14am
parting gifts
I jumped on the @towerbridge teacup-outrage bandwagon fairly early, so I’ve had a few days to think about how Twitter could have improved their response to the situation.
Meanwhile, this arrived:

Coming up on a few years of joining and leaving online services, I’ve become interested in graceful exits. What responsibilities does a Flickr or Facebook have when you decide to move elsewhere, or simply stop sharing some aspect of your life? So much effort goes into user acquisition and new account creation, so little into the sunset process.
After a few years on image-sharing service Ffffound!, I moved my activity to the more-explicitly social and more account-having Pinterest. There are friends there, you can comment on other people’s pictures, and if you decide to use it as-advertised you can track pictures of things you might want to buy. Hello Pinterest, goodbye Ffffound!. Still, I’d been using Ffffound! since 2007 and amassed something like 5,500 images—about five per day or one every five hours. What to do with all that stuff? Inspired by James Bridle’s work with printed recordings of ephemeral data streams and the U.K.-based Newspaper Club, a bound printed book seemed like the obvious thing.

Produced with Lulu and a bit of PDF-bashing code, I created a multi-volume print of everything I ever posted. The images here are from the color proof print that showed up at the office on Tuesday. The real thing will be somewhere in the neighborhood of 1,400 pages, probably spread over four volumes, with a hardback cover and hopefully capable of surviving the death of Ffffound! and all of its stable hash identifiers. It will contain everything I know about every image: the web page it came from, a title if there was one, and the highest quality version of the original image I can find.
The complete image and data collection is close to 700MB, so with a bit of compression I could probably cram it all onto a CD and stick that in the back—animated GIFs of popular rappers don’t print well.

Twitter eventually did right by Tom when they reinstated the old Tower Bridge bot under a different name, but it really only came together after a weekend’s worth of unhappiness from its fans. Assuming that the only way to respond to a trademark claim from a London event space was to unilaterally reassign Tom’s account, Twitter should have planned a less robo-legal approach to moving people around. If the content of the account (as opposed to its name) was not a violation of the terms of service, they should have changed the name and informed Tom. If the content of the account was itself a problem, they should have collected it into a downloadable form such as a spreadsheet or zip file, and shipped that to Tom along with notice of his termination. I understand the complexity of online service legal concerns, but the perils of reasoning by stereotype mean that genuinely brilliant creations like the original @towerbridge can be easily (and irreversibly) abused by the process.

Back to books, Craig Mod describes the post-artifact book:
A system of unlocking. A system concerned with engagement. Sharing. Marginalia. Ownership. Community. And, of course, reading. It’s the system that transforms the book from isolated vessel for text into a shared interface. It’s a system that’s beginning to appear in fits and starts in reading applications we use today. It’s the system most directly connected with readers. And it’s a system that, when executed well, makes going back to printed books feel positively neutered.
Neutered or not, leaving a living, breathing service is a valid step in the opposite direction, from post-artifact to post-service artifact, to a parting gift.
Jun 3, 2011 3:26pm
code for oakland
Code For Oakland is a thing I am involved in, tomorrow. It’s a one-day bar camp on using local data to build apps for Oakland at Kaiser Center, and you’re invited.

subscribe to ![]() this site.
|
contact Michal Migurski
this site.
|
contact Michal Migurski